Section 7.6 Scripting and Programming
As you study this section, answer the following questions:
- What are scripts used for?
- What is a variable in a script?
- What are some shell processor types?
- What program is used in Windows to execute scripts?
- What is the software development life cycle?
- What are the two approaches to reverse engineering?
In this section, you will learn to:
- Identify programming languages
- Explain the software development life cycle
- Perform reverse engineering
The key terms for this section include:
Key Terms and Definitions
| Term | Definition |
|---|---|
| Shell scripts | Allows users and administrators to automate tasks using a scripting language like Bash or PowerShell. |
| Variables | Holds reusable dynamic values and are foundational to the use of scripts. |
| Boolean operators | Used to perform comparisons in scripts. |
| Metacharacters | Characters that have special meaning to a computer program, such as shell. |
| Redirection | Allows for the output of commands to be sent to other locations, such as a file or another program. |
| PowerShell | Windows program used to develop and execute scripts. |
| Extensible Markup Language (XML) | A text-based markup language like HTML that uses tags derived from Standard Generalized Markup Language (SGML). XML is used to transfer data. |
| JavaScript Object Notation (JSON) | An object-oriented, event-driven programming language that enables website interaction (as opposed to HTML, which simply displays information). |
| Windows Management Instrumentation Command line (WMIC) | A powerful command line tool for performing administrative tasks and is well suited to scripting and automation. WMIC is part of the Windows Management Instrumentation (WMI) framework. |
| Python | An interpreted, high-level, general-purpose programming language used for a wide variety of purposes. |
| Regular expressions (regex) | Powerful tool used in many programming languages for manipulating text and data. |
| Software development life cycle | Process that helps ensure that programs are functional and secure. |
| Software assurance | Customer confidence that software functions as it should and is free from exploitable vulnerabilities. |
| Reverse engineering | The process of deconstructing software to reveal its design and code. |
This section helps you prepare for the following certification exam objectives:
| Exam | Objective |
|---|---|
| CompTIA CySA+ CS0-003 | 1.3 Given a scenario, use appropriate tools or techniques to determine malicious activity
2.1 Given a scenario, implement vulnerability scanning methods and concepts
2.5 Explain concepts related to vulnerability response, handling, and management
|
| TestOut CyberDefense Pro | 4.3 Analyze Indicators of compromise
|
7.6.1 Programming and Scripting Overview
Click one of the buttons to take you to that part of the video.
Scripting Languages 00:00-02:27 Developing scripts is a useful skill for anyone in the IT field, as scripts can be developed to automate specific tasks that are performed on a regular basis. The script can be developed using a variety of languages and platforms based on the Operating System. In this lesson, we'll look at some of the different platforms and languages we can use in developing our scripts. We'll also look at some situations where developing scripts can be useful.
A script is typically a text file with commands written in a specific scripting language. These commands are usually human-readable, and they efficiently perform repetitive tasks and even complex, data-driven tasks.
Generally, a scripting language is interpreted in real-time, line by line. A typical program must be compiled before running, meaning the code's text must be converted into binary code. Scripting languages are usually something a human can look at and interpret, whereas binary code is much more difficult to read.
One of the more popular scripting languages used today is Python. Python is a high-level, general-purpose programming language that emphasizes easy-to-read code. Python is an extremely versatile language that can be used for various purposes. One of the great features of Python is the large number of libraries that can be used to help adapt Python to practically any purpose.
In the Linux and Unix world, shell scripting is used extensively for automation and maintenance. Although there are several languages that fall under the term "shell scripting," the most common form of shell scripting is the Bourne Shell (sh).
Other shells include the Bourne Again Shell (bash), the Korn Shell (ksh), and the Z Shell (zsh). Each shell has its own syntax variation, but all are directly related to the Bourne Shell.
On a Windows system, we'll use PowerShell to develop and run scripts. PowerShell is like bash but uses different commands and syntax. PowerShell uses cmdlets—small, executable functions built into the language—and wraps them together to perform tasks. PowerShell can be used to automate a variety of tasks, such as adding a large number of users into Active Directory by referencing the data in a spreadsheet.
Scripting languages are also used to develop content on the internet. JavaScript Object Notation, or JSON, is an object-oriented, event-driven programming language that enables website interaction. With web applications becoming more prevalent, JSON has become one of the more popular languages on the internet.
Extensible Markup Language, or XML, is also used extensively on the internet. XML uses tags like HTML but is used to transfer data, not display it as HTML does.
Scripting Uses 02:27-03:17 Scripts and scripting languages are used for many tasks, including developing web content, software development, and automating network and system management tasks.
Scripts can also be used by a security analyst to automate scanning logs or automating complicated tasks in command line tools like Nmap. Attackers will also use scripts to automate their scanning and enumeration processes to exploit vulnerable hosts.
Automation saves systems administrators a lot of time. If a task can be reduced to collecting data, then all an admin needs to do is run a script that performs a series of single operations repeatedly until the task is completed.
One common use of scripting is adding users to Active Directory. Instead of adding users one at a time, a PowerShell script will use the data in a spreadsheet to create the accounts, saving time and automating this process.
Summary 03:17-03:34 That'll wrap up this lesson on scripting. In this lesson, we looked at some of the more common scripting languages you should be aware of including Python, bash, PowerShell, JSON, and XML. We then went over some examples of how scripts can be used in various areas to automate tasks.
7.6.2 Shell Scripting Commands Facts
Scripts are great tools that anyone in the IT field can utilize to automate specific tasks that are performed on a regular basis. Scripts can be developed using a variety of languages and platforms based on the operating system.
This lesson covers the following topics:
- Shell scripts
- Shell commands
- Writing shell scripts
Shell Scripts
Shell scripts allow users and administrators to automate tasks using a scripting language like Bash or PowerShell. Shell scripts are perfect for repetitive or complicated tasks and are versatile, ranging from a few simple commands to highly complex programming structures.
Shell scripts are essential for automation and efficiency, and they can automate many tedious tasks that otherwise require slow and error-prone manual effort. For example, shell scripts are great for creating backups, automating software updates, performing software installations, and automating system maintenance.
Analysts can use shell scripts to locate important information stored in logs or automate complicated commands that depend on command line tools. For example, a script can use N map to find hosts with active ports 80 and 443 and then perform additional steps to collect more information about the discovered services before saving the results to a file.
Pen testers and attackers also leverage shell scripts to perform various tasks to enumerate hosts and networks or automate the steps required to exploit vulnerabilities. Linux and Unix operating systems use shell scripting extensively for automation and maintenance tasks. There are different variations of shells that are used in these systems, and each has its own syntax. The following table describes these shell command processor types:
| Shell Processor Type | Description |
|---|---|
| Korn shell (ksh) | Typically used on proprietary UNIX systems, such as IBM's AIX. |
| Bourne shell (sh) | A simple, lightweight shell found on most *nix systems and devices. |
| C shell (csh) | Often associated with proprietary UNIX, such as Oracle's Solaris. |
| C shell (tcsh) | An improved version of C shell, available for many platforms. |
| Bourne Again shell (bash) | An improved version of sh and very widely used. |
| Z shell (zsh) | Expands upon Bash shell and supports many plugins to expand its functionality. |
Shell Commands
The following table lists some common Linux (and UNIX) commands and a brief description of their purpose.
| Shell Command | Description |
|---|---|
| cat | Display the content of a file. |
| tail | Display the last ten lines of a file. |
| head | Display the first ten lines of a file. |
| touch | Create an empty file. |
| mkdir | Create a directory. |
| cp | Copy a file or directory. |
| mv | Move an object, such as a file. Also used to rename files and directories. |
| rm | Remove a file or directory. |
| file | Determine the type of a file. |
| ls | Display the contents of a directory. |
| locate | Search for files. Locate uses a database to improve the speed and efficiency of searches. |
| find | Search for files by parsing the file system. |
| wget | Simple command to retrieve content from an HTTP server. |
| curl | Similar to wget but includes more sophisticated options. |
The following table lists common administrative commands. These commands are particularly important, and their use should be closely monitored.
| Administrative Shell Command | Description |
|---|---|
| vi/vim | A file editor for use in a terminal. Very popular but nonintuitive to use. |
| su | Substitute or switch user. |
| sudo | Precedes a command that requires elevated privileges. |
| useradd | Create a user account. |
| usermod | Change the attributes of a user account. |
| chmod | Change the read, write, and execute attributes of a file or directory. |
| chown | Change permissions on a file or directory. |
| mkfifo | Similar in concept to a standard | style pipe but implemented as an actual file. |
Writing Shell Scripts
The use of vi and vim text editors has been a staple of Linux and UNIX administration for many decades. Understanding how to use this tool is important, but its learning curve is steep.
The nano text editor has been in active development for many years, and its adoption has increased in recent years. Nano provides a user-friendly and intuitive interface, as shown in the following screen capture.
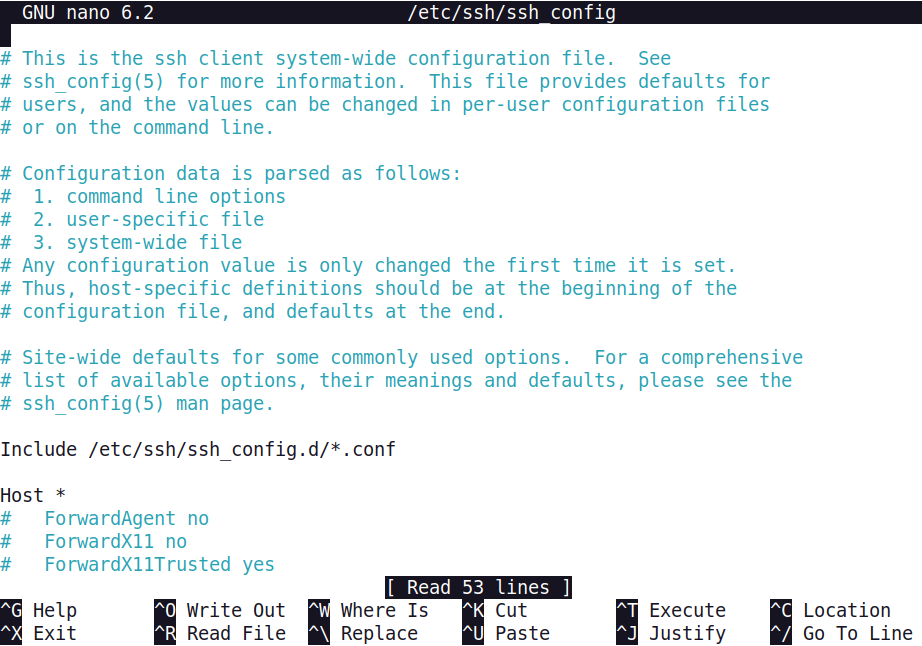
7.6.3 Bash Shell Variables and Loops Facts
Variables, loops, and other tools are used extensively in bash scripts. Proper utilization of these tools is vital in creating robust and powerful scripts.
This lesson covers the following topics:
- Variables
- Arithmetic
- Boolean operators
- If/Else statements
- Loops
Variables
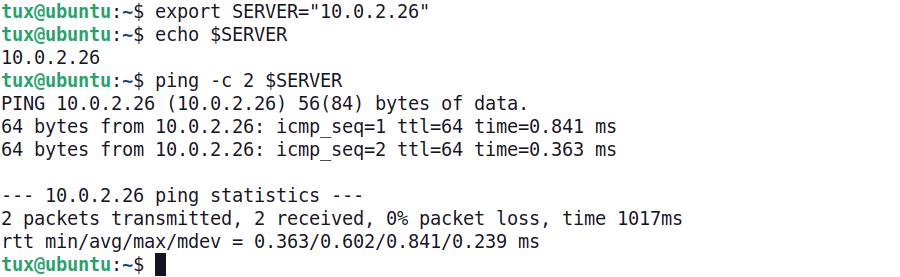
Variables hold reusable values and are foundational to the use of scripts. In this example, a shell variable named SERVER has been created. The export command sets the variable within the current shell session.
The variable SERVER is created with a value of 10.0.2.26. The value saved to a variable can be recalled using the $ symbol. When reading the command, one way to remember this is to replace $ with "The value of." For the second line below, echo $SERVER can be translated as "echo the value of SERVER." On the third line, the SERVER variable is used with the ping command. Notice that the value of SERVER is displayed in the command output.
Variable values can be set dynamically. In the example below, a script named script.sh is written using the nano text editor. Afterward, the chmod command is used to set the execute attribute on the script, allowing it to be easily used. On the third line below, the cat command displays the content of the script file. The script contains the following four lines:
- The shebang identifying as a bash script
- Echo a prompt for a name
- Saving user-typed input to the variable NAME
- Echo a response, including the user-provided value

Arithmetic
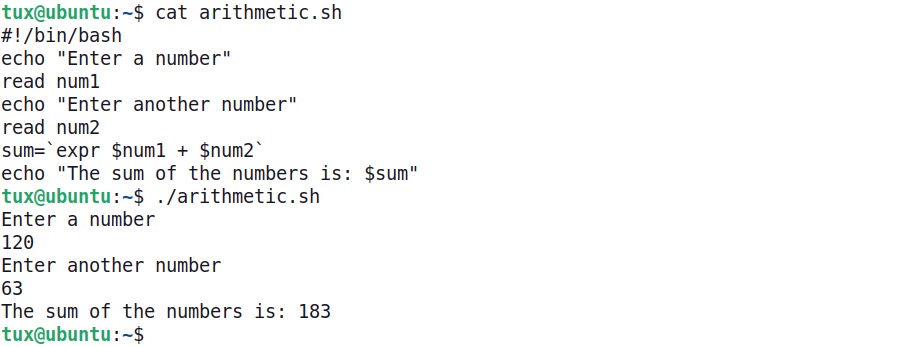
Shell scripts support many mathematical operations. Shells like bash must incorporate a few special conventions in order to perform arithmetic. For example, the expr command is needed when performing arithmetic.
The script below shows the use of variables and arithmetic. The variables num1 & num2 hold values supplied by the user, and the variable sum is used to store the result of adding them together. Notice that the arithmetic operation is contained with back quotes (sometimes called ticks). The back quote resembles a single quote but is not the same. The back quote key is typically located on the top-left corner of the keyboard.
The following table shows the different arithmetic operators.
| Operator | Description |
|---|---|
| + | Addition |
| - | Subtraction |
| * | Multiplication |
| / | Division |
| % | Modulus |
Boolean Operators
Boolean operators are used to perform comparisons. For example, the statement var1 = var2 would assign the value of var2 to the variable var1. This is a problem if the intent is just to determine equivalency. The correct syntax to compare values is var1 = = var2. If they are the same, the result is "true;" if not, the result is false.
The following table describes some common boolean operators:
| Boolean Operator | Description |
|---|---|
| == | Is equal to |
| != | Is not equal to |
| -eq | Alternative form of "is equal to" |
| -ne | Alternative form of "is not equal to" |
| -gt | Greater than |
| -lt | Less than |
| -ge | Greater than or equal to |
| -le | Less than or equal to |
If/Else Statements
Boolean operators are important for decision-making in a shell script. Comparisons are used to create decision branches which help steer the direction of the script's commands.
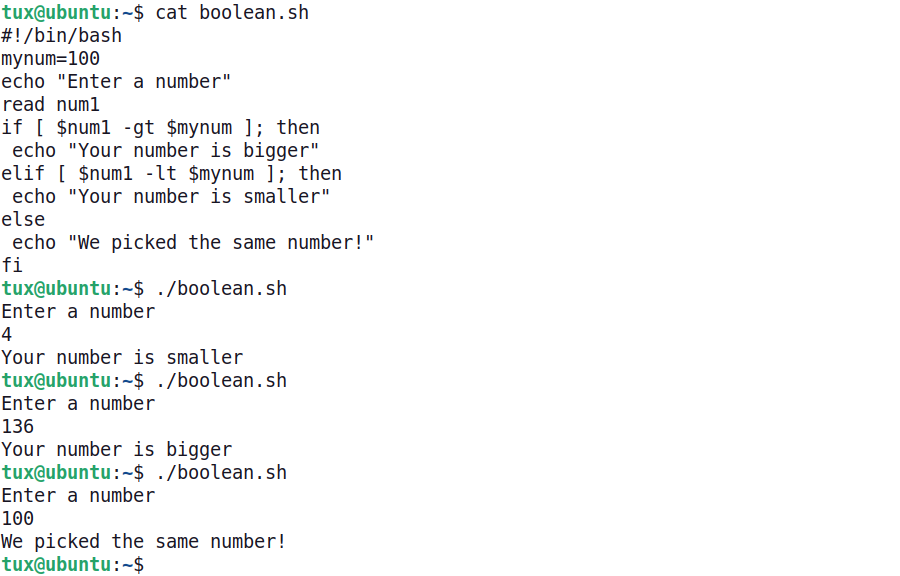
If/Else statements help identify a course of action based on a set of comparisons. Multiple comparisons incorporate an if/elif/else format, as shown in the following example. Notice that the boolean c omparisons are contained within square brackets , and there are spaces between the brackets and the c omparison statement. This script prompts the user for a number and compares it to the number 100, which is saved in the mynum variable. The script displays a different message depending on the results of the comparison.
While Loops
In the previous example, the script needed to be rerun each time we wanted to play the game. What if a player wanted to make several guesses to try and determine the "secret" number without needing to relaunch the script each time? A while loop will continue processing a series of commands until a predetermined condition is met. In the following example, the If/Else script is contained within a simple while/done loop. The If/Else portion of the program will continue to run until the user presses the CTRL-C key combination.
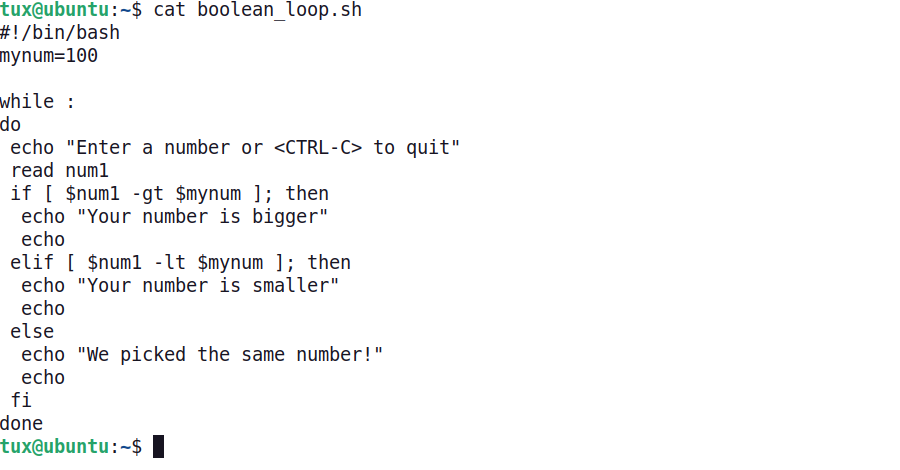
The following shows how the program operates when started. Notice that the script does not need to be restarted after each guess because of the while loop.

7.6.4 Metacharacters, Quotes, and Redirection Facts
This lesson covers the following topics:
- Metacharacters
- Command substitution
- Redirection
Metacharacters
Metacharacters are characters that have special meaning to a computer program, such as a shell. Metacharacters include:
New line,space,& tab- The characters
\* ? [ ] ' " \ $ ; & ( ) | ^ < >
If a metacharacter needs to be used as a normal character, problems can arise. The following examples shows different ways to manage metacharacters:
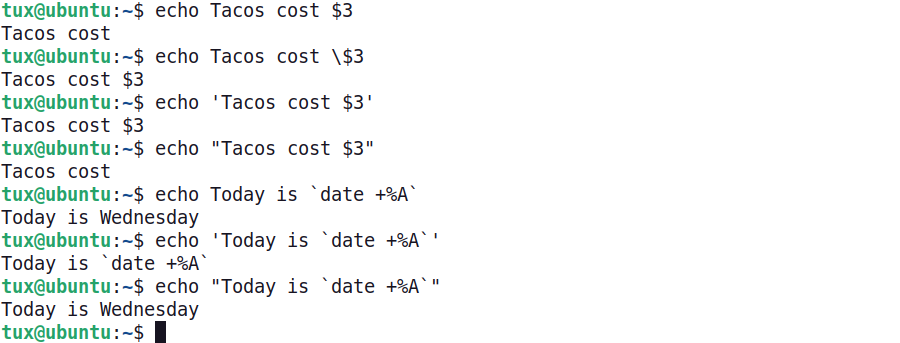
- In the first example, the metacharacter problem is shown as the cost of the taco not being displayed.
- In the second example, the escape character
\is used to instruct the shell to translate the $ as a character and not as a metacharacter. The result is that the cost of the taco is successfully displayed. - The third and fourth examples show the impact of quotes. The third example shows that text contained within single quotes is interpreted as text only, even if metacharacters are included.
- The fourth example shows that double quotes preserve the meaning of metacharacters contained within them.
- Lastly, the use of back quotes allows the result of a command to be displayed. Notice that when the
date +%Acommand is contained within single quotes, the characters are displayed instead of the result of the command. (The result of the date +%A command is to display the current day of the week.) When thedate +%Acommand is contained within double quotes, the back quotes are interpreted differently.
Command Substitution
Variables can also be used to store commands. The following example shows how this is accomplished. Notice that the commands are contained within back quotes.
Redirection
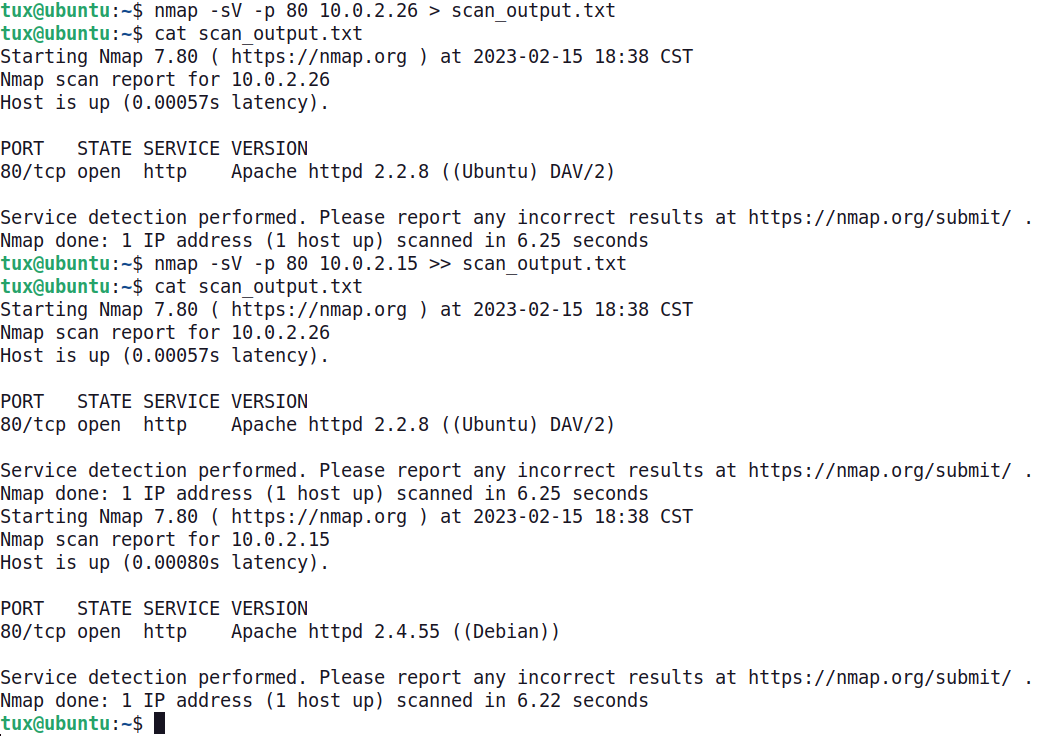
Redirection allows for the output of commands to be sent to other locations, such as a file or another program. The following example shows the output of an Nmap scan being redirected to a file. Nmap provides native output redirection capabilities too, but its standard output is being used as an example here.
The redirection character > is being used to send the output of the Nmap scan to a file named scan_output.txt . Notice that when the command is rerun to scan a different port, the scan_output.txt file is overwritten with the new results.
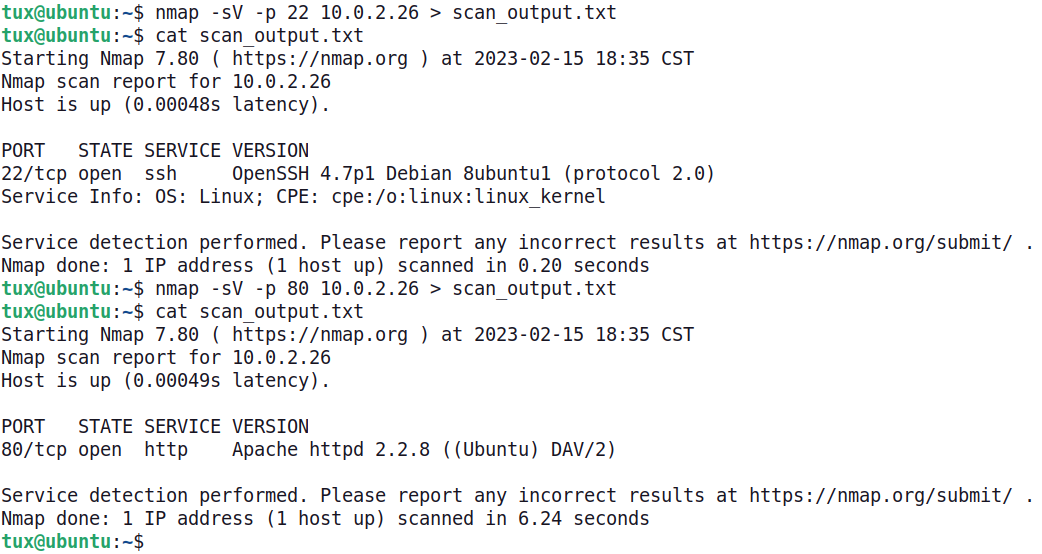
To append output to a file, the >> characters must be used. Notice in the following example how the second scan uses the >> characters to append the new results to the end of the file, preserving the original content.
7.6.5 Windows PowerShell Facts
Developing and executing scripts in Windows is done using PowerShell. PowerShell is similar to other shell programs but uses its own commands and syntax. PowerShell is built on the .NET framework and uses cmdlets, which are small executable functions built into the PowerShell language.
This lesson covers Windows PowerShell:
Windows PowerShell
PowerShell provides similar command line capabilities as UNIX and Linux systems. Early editions of the Windows operating system utilized the command prompt (cmd.exe). The cmd command line interpreter is still supported by new editions of Windows, but PowerShell offers far greater capability and is well suited to scripting.
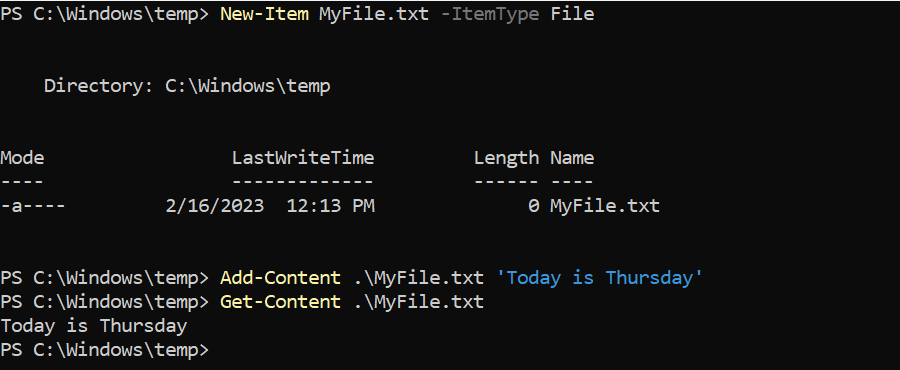
Many of the same concepts used in Linux shell scripting apply to PowerShell, but the command syntax differs. PowerShell is easily recognized by its use of cmdlets that utilize a verb-noun syntax. Examples of PowerShell cmdlets include Get-Help, Invoke-Command, New-Item, Set-Content, and many others. PowerShell scripts use the file extension .ps1.
In the following example, the New-Item , Add-Content , and Get-Content cmdlets are used to create a file, write content into it, and then display it on the screen.
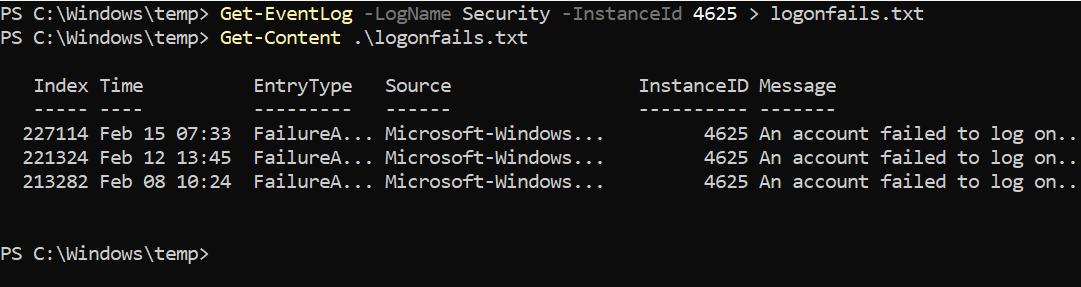
PowerShell supports redirection similarly to other shells. In this example, the output of the Get-EventLog cmdlet is redirected to a file named logonfails.txt. The cmd Get-EventLog is instructed to obtain events from the Windows Security log that match the Event ID 4625, which is associated with failed logon events.
Learning the syntax of PowerShell is a big hurdle initially. Windows provides the PowerShell ISE (Integrated Scripting Environment), designed to help craft scripts. The following screen capture shows the PowerShell ISE and the PowerShell equivalent of the guessing game script.
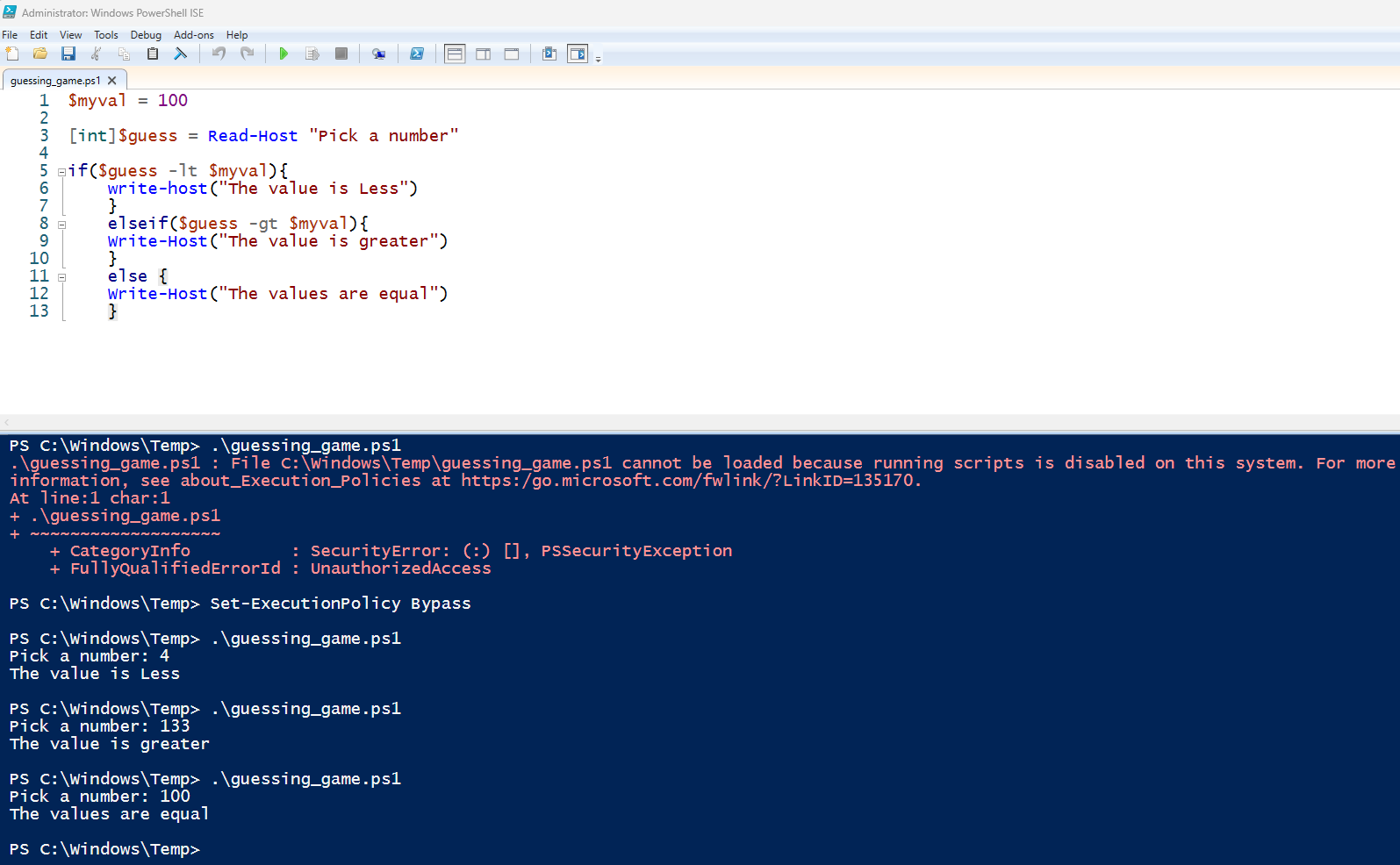
There are several important things to notice in the example above :
- The user input variable required integer specification using the
[int]qualifier. - The $ symbol is used in the definition of the variable.
- The syntax of the if/else statements is more complicated syntactically.
- When the command was first called, an error was displayed indicating that the script could not be run due to a policy violation.
- The Set-ExecutionPolicy cmdlet was used to bypass the security control, which then allowed the script to run.
Windows is highly restrictive in allowing scripts to run because of the risks they pose. As a result, any use of the Set-ExecutionPolicy should be carefully tracked.
7.6.6 XML & JSON Facts
This lesson covers the following topics:
- eXtensible Markup Language (XML)
- JavaScript Object Notation (JSON)
eXtensible Markup Language (XML)
eXtensible Markup Language (XML) is a text-based markup language like HTML that uses tags derived from Standard Generalized Markup Language (SGML). Unlike HTML, the primary purpose of XML is to transfer data, not display it. XML also uses opening and closing tags, but one of the key differences of XML is that the language itself does not define the tags. Instead, the author can invent the tags and the structure, allowing the developer to tag the data fields with something more meaningful.
In the below example, the <Product> tag is created and used to more accurately reflect the content of the table:

The XML tag now indicates that this is a table containing Products . Each product line has a product tag with an open and a close, and each field of data is tagged according to the data it holds. It is easy to recognize which fields represent product names and which are product numbers because each piece of data is tagged appropriately for what it represents.
Developing XML markup may not be a typical task for most analysts, but recognizing its syntax is important.
JavaScript Object Notation (JSON)
JavaScript Object Notation (JSON) is an object-oriented, event-driven programming language that enables website interaction (as opposed to HTML, which simply displays information). JSON is a derivative of JavaScript and is based on the JavaScript language. With the advent of web applications, JavaScript has become one of the core languages of the internet. JSON is used to transfer information and interact with programming languages like JavaScript.
JSON and XML are similar in several ways. Both utilize tags or keys created by the developer and are thus more relevant to the data. JSON and XML can both be read, parsed, and used by many programming languages. However, JSON has a more simplified coding syntax than XML, with fewer requirements, and it is not considered a markup language because it is object oriented.
Like JavaScript, JSON uses curly brackets for its syntax, and it does not require the opening and closing tags seen in XML and HTML. JSON is written using key/value pairs. When the product list is written using JSON, the Product Name is an example of a key, and the associated value is Adjustable Race . The key value is always a text string. The value in the value section of the key/value pair must be one of the following data types: a string, an object, a number, an array, Boolean, or null.

One element that makes JSON coding simpler is the ability to use an array (list of elements). In the JSON product list, the array is the list of the products. An array is noted using square brackets and contains comma-separated elements. The ability to use an array helps make JSON more streamlined than XML, which requires that each product have its own line of code.
JSON and XML are common languages used in data interfaces for information exchange. Data interfaces are often overlooked during vulnerability assessments because they are not always obvious. Data interfaces often transmit sensitive information such as usernames, passwords, and PII. Interfaces often operate similarly to other web applications and are susceptible to injection attacks and eavesdropping. Input validation and transport encryption controls are essential protections for XML and JSON communication.
7.6.7 Additional Scripting Tools Facts
This lesson covers the following topics:
- Windows Management Instrumentation Command Line (WMIC)
- Python
- Regular expressions
Windows Management Instrumentation Command Line (WMIC)
Windows Management Instrumentation Command Line (WMIC) is a powerful command line tool for performing administrative tasks and is well suited to scripting and automation. WMIC is part of the Windows Management Instrumentation (WMI) framework. It allows administrators to query, configure, and manage various system components, such as the operating system, hardware, and services. It also provides access to hardware and software information and can be used to manage and deploy applications remotely.
process call create
wmic /node:10.0.2.6 /user:Administrator /password:CySAisC00L! process call create "cmd.exe /c netsh advfirewall set allprofiles state off"
Python
Python is an interpreted, high-level, general-purpose programming language used for a wide variety of purposes. It is versatile for everything from simple scripts to advanced web and desktop applications. Python is highly customizable and benefits from a large community of contributors. There are thousands of third-party libraries for Python to help adapt it to practically any purpose. Python is used in data science, finance, computer science, system development, software engineering, cybersecurity, and many other fields.
Python programs and scripts use the .py file extension. Running python scripts requires the Python runtime, which is frequently included by default on many Linux systems. The extensibility and power of Python scripts allow them to perform many adversarial tasks. With the right skills, Python can perform everything from reconnaissance to exploitation, persistence, and cleanup.
Python is a powerful tool for defense operations too. Python can perform advanced tasks on log files, analyze network traffic, detect malware, monitor and control system services, and many other tasks.
Regular Expressions
Regular expressions (regex) are a powerful tool for manipulating text and data. They provide a concise and flexible means for matching text strings, such as specific characters, words, or patterns of characters. Regular expressions are great for searching, replacing, and manipulating text. Pattern matching is essential for locating data based on characteristics. For example, as an analyst, it may be necessary to search for any instances where credit card numbers are stored inappropriately. The challenge becomes how to locate something when its value is unknown. If the credit card number is known, searching for a match is simple. When data that looks like a credit card must be located, regular expressions are indispensable.
Regular expressions are used in many programming languages, including C, C++, Java, Perl, and Python. The syntax of Regular expressions varies among languages, but the basic concepts remain the same. Regular expressions are composed of characters and special characters. The characters include letters, numbers, and symbols, while the special characters are used to indicate special matches. The most commonly used special character is the dot (.), which is used to match any character. Other special characters include the asterisk (*), which matches any number of characters, and the question mark (?), which matches any single character.
Regular expressions can validate data, find patterns in large amounts of text, search and replace text, validate email addresses, search for phone numbers, and replace instances of one word with another.
The following tables describes the different regex elements and their purposes:
| Element | Purpose |
|---|---|
| [ABC] | Character set |
| [A-Z] | Range |
| \w | Word |
| \d | Digit |
| \s | Whitespace |
| ^ | Beginning |
| $ | End |
| ? | May or may not exist |
| {1,3} | Quantifier |
To see how regular expression works, consider the following list of (fake) telephone numbers:
- (202) 555-0322
- 202-555-0323
- (202) 555-0803
- 202.555.0313
- 202-555-0716
- 202-555-0523
- 202 555-0291
- 202 555 0201
All of these numbers represent the same thing, a telephone number, but the formatting varies substantially. Some numbers use parenthesis for the area code, while others do not. Some use a dash (-) as a separator; some use a dot (.) and some a space. A regular expression can be used to match all of these variances, but getting the ultimate solution usually takes a few iterations. The following table shows some different regular expressions and the results:
| Regular Expression | Explanation |
|---|---|
| \d{3}[-.]\d{3}[-.]\d{4} | This regex matches four of the numbers. It looks for a sequence of three numbers followed by a . or a -, then three more numbers followed by a . or a -, then four numbers. |
| \d{3}[-.\s]\d{3}?[-.\s]\d{4} | This regex matches six of the numbers. It expands upon the previous example by adding \s (which represents whitespace) and ? (which translates as "may or may not exist"). |
| \(?\d{3}\)?[-.\s]\d{3}?[-.\s]\d{4} | The example matches all eight numbers. It extends upon the previous example by adding \(?, \)? to locate the parenthesis. |
7.6.9 Software Development Life Cycle (SDLC) Integration
Click one of the buttons to take you to that part of the video.
Software Development Life Cycle (SDLC) Integration 00:00-00:39 With so many digital criminals in the world, companies have to spend a great deal of time and effort to protect their software from threats. They also need to convince their customers that their products are free from vulnerabilities. These could be vulnerabilities that were put in the software intentionally or those that were introduced during the software development life cycle, or SDLC. This is known as creating software assurance. In this video, I'm going to go over how we can safely integrate the SDLC into our systems and make sure that customer confidence remains high.
SDLC 00:39-01:36 The SDLC includes the steps of gathering and analysis, design, implementation and coding, testing, deployment, and maintenance. This means that developers first plan out what they need the software to do and then they design it to meet those specifications. It's only after this phase that they write the actual code and test it to make sure it works the way it should.
Once they've created a viable product, the developers deploy the software so that it can be utilized by end users. But developers also have to continually maintain the end product once it's deployed in case any other bugs or vulnerabilities appear. There are various ways to implement this life cycle, but whichever model you choose, it's important to think of the end user and their peace of mind at every stage. If you do that while designing and testing your prototype, you're more likely to have a secure final product.
Risk Management 01:36-02:39 One best practice is to think about risk management during the quality assurance process. Managing risk is part of creating a quality customer experience, and so the quality assurance team should always be proactively looking for software vulnerabilities. The extra investment of time and money up front will pay dividends over your product's lifetime. But again, even after software is deployed, the quality assurance process isn't finished. It's much easier and less expensive to find problems before software is released than having to deal with fixing them afterward, but remember that security is an ongoing process and we shouldn't let our guard down after deployment either.
There's no software that's released completely bug free, and so you should continue to try to find these bugs and fix them. This is especially important after you release updates, as this is the most likely time for new vulnerabilities to be uncovered. You need to keep looking for these vulnerabilities so that your customers can have continued confidence in your product.
Think About the End User 02:39-03:12 When you're considering how to build software assurance, you should put yourself in the end user's position. Think about specific ways that a customer would use your product. For example, if it's accounting software, you might consider that the customer would use it to file their taxes, create a budget, or track monthly expenses. Take time to simulate each of these experiences as the end user. This'll often show where the software is lacking. This should be done in addition to scouring the actual code for errors.
Unknown vs. Known Testing Environments 03:12-03:48 Your approach to providing software assurance should include both known and unknown testing. Unknown testing means you test the software with no prior knowledge of how it's supposed to work, in the same way an end user would experience it for the first time. With known testing, you consider the program's internal workings and structure as well as how well the program is functioning. Sometimes, you can implement partially known testing, which is a combination of the two approaches. In this case, you consider some of the internal workings while treating the program mostly as an unknown testing environment.
Summary 03:48-04:41 That's it for this lesson. In this lesson, we discussed how software goes through a life cycle, which is just the different steps in its development to get to the place we need it to be. The software is planned, developed, tested, released, and maintained. Next, we discussed that while going through this process, it's important to think about software assurance, which is the confidence the end user has that the product is free from vulnerabilities to the greatest extent possible. We also discussed how spending time to think about the end user's experience during development pays dividends in the long run because it's much easier to fix problems before releasing a product than afterward. And finally, we discussed the importance of testing using various techniques, such as known and unknown testing.
7.6.10 Software Development Life Cycle (SDLC) Integration Facts
A key focus for software developers is to ensure that programs are not just functional, but also secure. Customers should be confident that the software works and is free from vulnerabilities. This is known as software assurance. Following a process such as the software development life cycle (SDLC) helps ensure that programs are functional and secure.
This lesson covers the following topics:
- Software development life cycle
- Known vs. unknown testing environments
- OWASP Testing Guide
Software Development Life Cycle
Following the software development life cycle helps developers first plan the goals and functions of a program, design the program to meet these specifications, and maintain and update it as needed. The following table describes the phases of the cycle:
| Phase | Description |
|---|---|
| Requirement Gathering | The developers first plan what they need the software to do and establish software requirements. |
| Design | The developers create a design plan to meet the software requirements. Developers should analyze the specific ways the customer will use the product and design the program to provide the optimal experience. |
| Coding | The developers write the program code that runs the software. |
| Testing | The developers test the program code through various processes.
|
| Deployment | The developers deploy the program so that it can be used. |
| Maintenance | The developers maintain and update the program as needed. As bugs and vulnerabilities are discovered, updates and patches should be released to ensure a quality product for the life of the program. |
The secure software development life cycle (SSDLC) is a process for developing software that emphasizes security throughout the entire development. It helps identify and mitigate security risks at every stage of the software development life cycle, from initial design to testing and deployment. This contrasts with traditional software development life cycles that focus on collecting and implementing functional user requirements. Traditional software development life cycles produce software that works well but is not necessarily secure.
The SSDLC is a continuous process that parallels typical SDLC practices. Each stage includes requirements to ensure that security is continuously monitored and improved throughout the entire software development life cycle. By incorporating security requirements into every stage of the software development life cycle, the SSDLC helps to ensure that software is both functional and secure.
Known vs. Unknown Testing Environments
Extensive testing is needed to provide software assurance. This testing needs to take place throughout all phases of the SDLC. The following table describes the types of testing environments:
| Testing Type | Description |
|---|---|
| Known testing | This testing environment looks at the program’s internal workings and structure. It also looks at how well the program is functioning. |
| Unknown testing | This testing mimics the end user's experience. The tester uses the software with no prior knowledge of how it functions. Unknown testing:
|
| Partially known testing | Partially known testing is a combination of both unknown and known testing. The code and functions of the program are tested while the program is treated as an unknown environment. |
OWASP Testing Guide
The OWASP Testing Guide is a comprehensive guide for testing the security of web applications. It is the product of Open Web Application Security Project (OWASP) designed to help developers, testers, and security professionals identify and address security vulnerabilities in web applications.
As of this writing, the current version of the OWASP Testing Guide is 4.2 with version 5.0 under active development.
The OWASP Testing Guide provides a structured approach to web application security testing and provides specific guidance for each of the following areas:
- Information gathering
- Configuration and deployment management testing
- Identity management testing
- Input validation testing
- Testing for error handling and logging
- Testing for cryptography
- Business logic testing
- Client-side testing
- Testing for web services
- Testing for mobile security
7.6.11 Assessment and Coding Practices
Click one of the buttons to take you to that part of the video.
Assessment and Coding Practices 00:00-00:29 Software assurance is the confidence level that customers should have that your software functions the way it's supposed to and is free from exploitable vulnerabilities. These can be vulnerabilities that were put into the software intentionally, or they can be those that were accidentally inserted at any time during the development life cycle.
There are many best practices that companies can utilize to ensure customer confidence in their products. In this lesson, I'm going to discuss several of these best practices.
UAT 00:29-00:58 One of these methods is known as user acceptance testing, or UTA. You might've heard of this as beta testing. As the final testing phase, UTA's goal is to test the product to see if it actually works in real-world scenarios. This kind of testing deals with showing the program to the end user and asking them for feedback about their experience. You want to find answers to questions like whether the software performed the task it was supposed to, if the user had trouble using the software, and whether it provided what was promised.
Stress Testing 00:58-01:28 Another kind of testing we use is called stress testing. With this type of testing, you try to find out if your software performs well under taxing conditions. Basically, you're trying to determine whether your software is robust enough to handle a variety of conditions. While performing your stress test, you want to push the software to its limits to see whether it breaks.
By finding out where your software is still vulnerable to stress, you can determine what still needs to be done to make sure your final product is ultimately able to perform well in the field.
Security Regression 01:28-01:46 Security regression testing is another kind you should do each time there's been a bug fix or major software update. This means testing the latest version to ensure that it's not less secure than previous versions and still performs as expected. If it doesn't, your team needs to figure out what to do to fix or patch up any new security holes.
Code Review 01:46-02:21 Code review is another process that should take place during the entire development life cycle.
This is the practice of having coworkers check each others' code for mistakes. This streamlines the process, ensuring that more mistakes are caught before they're introduced into a build.
Although it's possible to check code through automatic processes, it's worth having another set of human eyes look over it to make sure it all makes sense and that other coders are following best practices.
These best practices include keeping code as simple as possible, sanitizing data sent to other systems, and validating input.
Input Validation 02:21-02:46 Input validation is the process of checking that a user's input is valid before passing it on to the rest of the system.
For example, if a user is supposed to input a telephone number into a specific field, the program should validate that the user didn't add any letters or symbols before passing it along. This is important because hackers can use malicious inputs to cause programs to behave in ways they weren't intended to.
Output Encoding 02:46-03:27 Let's shift gears now to best practices that have to do with coding.
Output encoding is the process of converting HTML control characters, such as ampersands, with their encoded representations.
For example, although the end user sees the ampersand sign when they view the document, the HTML code used to produce this sign is &. You can see a few more examples here.
If all the HTML is encoded correctly, it outputs the correct symbols. But if not, there'll be stray code displayed to the end user, which can cause the application to look messy. But most importantly, output encoding protects your application from cross-site scripting.
Session Management 03:27-04:08 Something you need to test with web applications is session management.
Session management is the process of securely handling multiple requests to a web-based application or service from a single entity. Whenever a user authenticates to a web application, such as TestOut's LabSim, a session is created for that user.
Once this happens, the application needs to properly handle multiple requests being made from a single user during the session. This is important because the user can usually access things that aren't accessible to those who aren't authenticated. If you don't properly manage sessions, hackers could be able to gain access to other users' sessions and their privileged information.
Authentication 04:08-04:46 As you're probably aware, authentication is the process that grants an application end-user access, and there are many options available for users to authenticate themselves with. For example, the software might do its own authentication, or it might use a federated solution that allows it to gain authentication data from another trusted service.
Regardless of the method, your development team needs to make sure there are no vulnerabilities in this process. You do this by requiring things like multi-factor authentication, where there's more than one authentication step, and by employing other security measures. For example, you could lock out users who fail the authentication check multiple times in a row.
Parameterized Queries 04:46-05:20 If your application uses SQL or something similar, another coding best practice is to use parameterized queries.
Parameterized queries let you easily vary a query's results based on input values without changing the underlying query's content. In other words, these queries are pre-compiled SQL statements that only require parameters or variables in order to execute. Using these queries is a good way to prevent SQL injection attacks, which is where an attacker injects malicious input into an SQL query to steal data or run their own code.
Static vs. Dynamic Analysis 05:20-06:49 Now, let's look at code analysis. There are two different types of code analysis you'll likely encounter—static and dynamic. Perhaps a good way to introduce you to them is to use a sports analogy.
Static analysis is analogous to a football punter practicing their kicking into a practice net. While doing this, the punter can focus specifically on their form, such as how many steps to take and at which angle to approach the ball. After several kicks, the punter has a good feel for the pace and angle of the kick. The problem is that he or she can only progress so far with this method.
Dynamic analysis is more like punting during a scrimmage with fellow teammates. This lets the punter practice their kicking against a live opponent. This is beneficial because it helps the punter test their reaction to all sorts of unexpected situations to see if they're kicking the ball hard enough and in the right direction.
Although sports and computers are very different, the basic concepts are the same. Static analysis means you're evaluating the code without executing the application, like kicking into a net. In other words, you're looking at the code at a conceptual level. We often see this method used when debugging application code. It's also a good way to discover code vulnerabilities and do a quick code review.
Dynamic code analysis, on the other hand, is the evaluation we do while the application is actually running, like playing a scrimmage game. The main purpose is to find and debug errors that are too subtle or too complex to find with static analysis. Both types have an important place in the review process.
Formal Verification 06:49-07:53 The last best practice is formal verification of critical software. As we've already seen, one of the most common testing methods is to use humans as opposed to machines. But testing large and complex systems can be time-consuming and expensive, and there are also things that we as people miss that machines pick up.
It might be annoying, but it's not the end of the world if a bug slips by in a word processor or video game. But if that application deals with safety or finances, a simple bug could mean the end of lives or financial ruin for individuals and companies. This is where formal verification becomes critical.
Formal verification of software means mathematically proving that a program meets certain standards and specifications in its behavior. These verification techniques are mathematically rigorous, meaning they're based on sound mathematical deductions. Since formal verification is mathematically precise, there isn't any risk of misinterpretation. The downside to formal verification is that it can be very time-consuming and can require a long learning curve.
Summary 07:53-08:38 That's it for this lesson. In this lesson, we discussed various software methods, including getting user input from user acceptance testing, using a stress test to make sure our software can handle extreme conditions, and making sure that a new update doesn't make an application less secure than before. We also discussed how our code should be peer reviewed using both static and dynamic analysis. We went over how input validation makes sure that only valid inputs are fed into a system, and how session management ensures that only authenticated users are given access to sensitive data. All these testing methods assure our customers that a piece of software we provide is as secure and user-friendly as possible.
7.6.12 Assessment and Coding Practices Facts
This lesson covers software assurance best practices.
Software Assurance Best Practice
Software assurance is customer confidence that software functions the way it is supposed to and is free from exploitable vulnerabilities. Vulnerabilities can be put into software intentionally or accidentally inserted during the development life cycle.
The table below describes best practices to help you maintain a high level of software assurance.
| Software Assurance Best Practice | Description | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| User acceptance testing (UTA) | User acceptance testing:
| ||||||||||||||||
| Stress testing | The purpose of stress testing is to determine if the software performs well under variety of taxing conditions. A typical stress test has five main steps:
| ||||||||||||||||
| Security regression testing | Security regression testing:
| ||||||||||||||||
| Code review | Code review is the process of a team other than the product developers checking the code for mistakes. This helps to ensure that mistakes are caught before they're introduced into a build. Code reviews should strive to:
| ||||||||||||||||
| Input validation | A web application (or any other client-server application) can be designed to perform input validation locally (on the client) or remotely (on the server). Applications may use both techniques for different reasons, but client-side validation can be easily bypassed. Input validation must always occur as a server-side control. Where an application accepts string input, the input should be subjected to normalization or sanitization procedures before being accepted. Normalization means that a string is stripped of illegal characters or substrings and converted to a predetermined character set. This ensures that the string is in a format that can be safely processed by the input validation method and mitigates the risk of receiving characters that may be processed as instructions. An attack often uses obfuscation to disguise the nature of malicious inputs. Obfuscation swaps characters to formats still recognized by the server but more likely to be missed by application firewalls and IDS systems. For example, a simple directory traversal attack using "normal" characters looks like the following:
When the input is modified to use URL encoding, the input accomplished the same objective but appears much differently:
| ||||||||||||||||
| Output encoding | As well as validating input, a web application should use context-appropriate output encoding to prevent the execution of malicious code. Output encoding is a defensive technique that assumes that input validation may have failed or that it might not have been possible to sanitize input. In that context, the application needs a reliable way of distinguishing between code to execute and data to process. For example, if a function updates a web page based on client input, when constructing the HTML string to send to the browser, potentially unsafe characters—character returns, escape characters, delimiters, and others—received as input parameters should be encoded as HTML entities. This means the input will be displayed to the user as text and not executed as a script. Output encoding mitigates against injection and XSS attacks that seek to use input to run a script. Some examples of output encoding include:
| ||||||||||||||||
| Session management | The process of a web-based application or service securely handling multiple requests from a single user or entity. Whenever a user authenticates to a web application, a session is created for that user. The application needs to properly handle subsequent requests from that user during the session. If sessions are not properly managed, hackers can gain access to other user sessions and privileged information. The following tables outlines some important considerations for secure session management:
| ||||||||||||||||
| Authentication | The process used to verify access authorization to an application. Types of authentication include:
To ensure the authentication process, consider using:
| ||||||||||||||||
| Parameterized queries | Parameterized queries (used with SQL or a similar application) let you vary the results of a query, based on input values without changing the content of the underlying query. These queries are pre-compiled SQL statements that require only parameters or variables in order to execute the query. Parameterized queries help prevent SQL injection attacks (an attacker injects malicious input into an SQL query). | ||||||||||||||||
| Static code analysis | Static analysis is the process of evaluating the code without executing the application. You review at the code at a conceptual level. You can use static code analysis to:
| ||||||||||||||||
| Dynamic code analysis | Dynamic analysis evaluates the code as it runs. You can use dynamic code analysis to find and debug program errors that a static code analysis may not reveal. | ||||||||||||||||
| Formal verification | Formal verification uses a program or system to mathematically prove or disprove that a program meets certain standards and specifications of behavior. The verification techniques are mathematically rigorous, meaning they're based on sound mathematical deductions. Since formal verification is mathematically precise, there isn’t any risk of misinterpretation. The downside to formal verification is that it can be time-consuming and requires a long learning curve. | ||||||||||||||||
| Data protection | Secure coding practices ensure that sensitive data is kept confidential and secure. The best practices for secure coding are outlined in several sections within this lesson and include input validation, using encryption, implementing strong authorization and authentication, proper error handling, secure storage of sensitive data, and regular testing and maintenance. |
7.6.13 Reverse Engineering Overview
Click one of the buttons to take you to that part of the video.
Reverse Engineering Overview 00:00-00:31 In this lesson, I'm going to discuss reverse engineering. When working with software, reverse engineering is the process of deconstructing software to reveal its design in an attempt to find vulnerabilities. These vulnerabilities can then be used by attackers when they carry out their nefarious plans. There are two approaches to dealing with reverse engineering. One approach is to try and prevent an attack. The other is to combat the malware directly.
Reverse Engineering for Prevention 00:31-00:55 The first method is to take an offensive approach. This is done by having developers send their code to a third party to see if they can reverse engineer the code themselves. This proactively processes the code in the same way an attacker would, but without the malicious intent. It gives developers the opportunity to make needed changes to their code before allowing it to be accessible to the public.
Endpoints 00:55-01:29 The second approach is defensive. Often, the first place you should check for security weaknesses are the network's endpoints. Endpoints are devices such as laptops, mobile phones, tablets, or desktops that are physically located on connection points. These devices are brought to the network by individuals and might not have the same level of protection that other devices do. Endpoints usually have lower security standards than workstations and, at the same time, often have full access to networks. This makes them a favorite target for malware attacks.
Endpoint Protection 01:29-01:44 You should help users that bring their own devices to establish high-level security policies. But it's also important to scan these devices regularly for malware. When malware is detected, reverse engineering the code is an essential step for protection and prevention.
Reverse Engineering Tools 01:44-02:32 In cybersecurity, reverse engineering malware is where a security analyst seeks to understand how malicious programs were designed and what their capabilities are by extracting code from a binary executable. Let's first look at the types of tools you can use to reverse engineer malware.
We can categorize these tools into four types: disassemblers, decompilers, hex editors, and debuggers. Each has its own function to offer. Disassemblers translate binary into assembly language; decompilers translate binary into high-level languages. Hex editors let you edit the contents of binary, and debuggers let you view and change a program as it's running. Some software tools integrate these together.
Decompose Binary 02:32-03:43 There are three common ways to decompose binary into a state that's understandable for inspection. The first is through machine code, in which binary is executed by a processor that's usually two hex digits per byte. When you use this method, keep in mind that Windows portable executable binaries start with the hex characters 4D 5A. They can also be shown as the ASCII string MZ, or as TV if they're encoded as Base64. Machine code instructions often change registry and memory contents, perform logical bitwise and mathematical operations, and make use of system memory addresses.
The second way is through assembly code, where a disassembler translates machine code into text strings in assembly language. Disassemblers produce the text strings as they're happening and don't organize them. This information is best utilized by a security analyst who can reconstruct the programming logic using specialized software tools. The third way is through high-level code. This is using software tools to decompile assembly code to high-level pseudocode that can find branching logic.
Disassemblers and Decompilers 03:43-04:45 Okay, now let's go over some of the most common disassemblers and decompilers in use today.
One of the most popular is IDA Pro, which is an interactive disassembler tool for analyzing multiple kinds of malware. It's generally used for static reverse engineering, but it does have debugging capabilities. This is an automated tool that identifies API calls, constants, function parameters, and disassembled code elements. It runs on Windows, macOS, and Linux. This is an expensive but popular option because it's so effective. HEX Rays is an add-on for IDA Pro that can decompile assembly language to pseudocode and show you the malware entry point. Next, is Ghidra, which is an NSA open-sourced disassembler and decompiler that runs on Windows, macOS, and Linux. Ghidra has automated and interactive modes, can be customized with Java or Python, has a great user interface, and is free.
Additional Disassemblers and Decompilers 04:45-05:52 Then we have Binary Ninja, which is a disassembler and decompiler created by hackers. It displays the disassembled binary in a graph or linear view. It comes in commercial, personal, and free versions. The free version is a limited version without all the features of the paid versions. It runs on Windows, macOS, and Linux. Next, is Hopper, which is a disassembler made for macOS that runs on Linux as well. It disassembles, decompiles, and debugs applications. It can display the assembly, flow, and pseudocode of a procedure at the same time. And finally, we have another free, open-source decompiler called Radare2. It uses a command line interface to do its job. This can be challenging to learn how to use, so now a user-friendly graphical interface has been created for it called Cutter. The Cutter option includes a debugger, hex editor, linear disassembly view, binary patching, and Python scripting engine. It can run on Windows, macOS, and Linux.
Hex Editor Tools 05:52-06:32 Now, let's go over a few hex editor tools that are available. First, is 010 Editor. This one must be purchased for a low fee and runs on Windows, macOS, and Linux. The rest are free or have free options. They include HxD, Haxinator, wxHexEditor, and Hex Editor Neo. Hex editors can help you reverse engineer because they can extract basic features from a file. In addition, they can sometimes help with getting past obfuscation methods. You can even use them to manually extract printable strings from a file's ASCII representation.
Debuggers 06:32-07:17 Finally, let's go over debuggers. Debuggers are programs that run a suspicious program in a controlled environment, allowing the malware analyst to monitor its execution in real time to track the effect it has on computer resources. Debuggers can stop the program during its execution and report memory content, storage devices, and CPU registries. You can also change variables' values when you pause the debugger manually or when it reaches breakpoints you've set. You can set these breakpoints by indicating a pause when a specific function is called or when variables are set to given values. It could be helpful to execute code line by line to find the malicious parts. Debuggers provide the ability to do this.
Debugger Tools 07:17-07:29 Some common debuggers are WinDbg, GNU Project Debugger (GDB), Wind River, PEiD, PEStudio, and PE32.
Summary 07:29-08:05 That's it for this lesson. In this lesson, we discussed preventative reverse engineering, which helps find vulnerabilities in your own code before hackers do. Then we discussed the risks that endpoints can create in your network. And finally, we went over defensive reverse engineering of malware and the tools that are available to help you break down code. Use these skills to better understand how malware works and the harm it can cause. With this knowledge, you can stop it and prevent any future attacks.
7.6.14 Perform Reverse Engineering
Click one of the buttons to take you to that part of the video.
Perform Reverse Engineering 00:00-00:43 There are certain scenarios where it would be nice to be able to look under the hood at how a piece of software operates. This isn't always possible if a person doesn't have access to the original source code that was used to make the software. This is where software reverse engineering tools come in handy. In this demo, we'll use a tool called Ghidra to analyze a very simple program written in C. I have a terminal open here, and if I run this simple program, we can see it prompts me to input a PIN. If I just enter some numbers and press ‘Enter', it says it was incorrect and continues to prompt me for the right PIN. We can use reverse engineering tools to take this program apart and see if we can find out if there's a pin that this program will accept.
Introduction to Ghidra 00:43-01:14 Let's use Ghidra to analyze this simple executable. Ghidra is a free and open-source program released in 2019 by the NSA. It's quite powerful when it comes to analyzing applications of any type. I've installed Ghidra on this Kali Linux machine. But since it runs on Java, it can easily run on most operating systems. I'll launch Ghidra by navigating to it in my terminal and running ‘./ghidraRun', which is its launch script. We can see that Ghidra has launched and tells us we have "NO ACTIVE PROJECT".
Set up Ghidra Project 01:14-01:35 We need to go to ‘File' and then click ‘New Project'. Ghidra allows a server to be set up to share projects, but we don't have that here. So, this will be a non-shared project and I'll just click ‘Next'. Ghidra now asks us where we want to save the project and to give it a name. I'll just use the default home location, call it ‘testout-demo', and click ‘Finish'.
Import Binary into Project 01:35-02:25 Once we finish creating the project, it'll automatically become our Active Project. But currently, it's empty, so now we need to import our program into it. If I click ‘File', I can see there's an ‘Import File…' option. I'll select this and it'll ask me to browse to the file to import it. I select the program that I ran earlier and click ‘Select File To Import'. Ghidra then detects some information about the program, like its format and the language it was written in. These can be changed if it has them incorrect, but the defaults are right, so I'll just click ‘OK'. Ghidra then gives me a summary of the imported file, and I'll just go ahead and close this window. I can now see my imported file in my project. To begin the analysis, I'll double-click the file to open it.
Analyze Binary 02:25-04:44 Ghidra says this file hasn't been analyzed before, so I'll click ‘Yes' to analyze it now. Ghidra prompts us to customize the analyzation step, but for our purposes, the defaults are just fine. I'll click ‘Analyze'. Now Ghidra is showing us the raw assembly view of our program in the middle here. If I scroll down a little bit and select a function, Ghidra will do its best to decompile this assembly back into C. It does some guessing for things like variable names since those aren't usually saved as part of the final program, but it's sometimes easier than looking at the assembly view. This will come in handy a lot. A very common first step in reverse engineering is to look for strings, or words and phrases that the program uses, such as "Input Pin" or "Wrong Pin", as these can lead us to the right area of the program to look at. Ghidra has a string search for just that purpose. If I select ‘Search' in the top menu and then ‘For Strings…', I can set up certain parameters on the search. But the defaults are fine for now, so I'll click ‘Search'. We can now see all the strings Ghidra has found, like our "Input Pin:" message. And it seems there is a "Correct Pin" message after all! If I select a string in this search, Ghidra jumps in the assembly view to where the string is in the program. Now if I right-click on the string in assembly view, I can find all the references to this string by right-clicking the block in the assembly view and going down to ‘References' and selecting ‘Show References To Address'. It seems like there's only one. If I click it, it'll again jump to that section of the program, and Ghidra will try to decompile the assembly code and come up with its best guess as to the original C code. This looks like exactly what we're after! We can see there's an infinite loop here that asks us to "Input Pin:" and then compares that input against something. If it doesn't match, it shows the "Wrong Pin" message. If it does match, it breaks out and we get the "Correct Pin" message. I'll click the value it compares our input to and, if I just hover over it in the assembly view, Ghidra gives me this decimal number 8787. If I go back to the program in my terminal and input 8787, I get the "Correct Pin" message and my program exits!
Summary 04:44-05:04 That's it for this demo. In this demo, we talked about software reverse engineering. We looked at creating a project in Ghidra, opening and analyzing a program in this project, and using this analysis to gain information about a program that the developer might not have known was left in.
7.6.15 Reverse Engineering Facts
Reverse engineering is the process of deconstructing software to reveal its design and code. An attacker can use reverse engineering to find software vulnerabilities. The vulnerabilities can be used to attack the network.
This lesson covers the following topics:
- Preventative reverse engineering
- Defensive reverse engineering
- Reverse engineering malware
- Reverse engineering tools
There are two approaches to reverse engineering. One approach is to try to prevent an attack. The other approach is to defend against an attack.
Preventative Reverse Engineering
To proactively protect your source code:
- Send source code for new or revised programs to a third party or someone in the organization to reverse engineer it before it is used.
- Evaluate the risk level of any vulnerabilities that are discovered.
- Fix or patch the vulnerable areas before an attacker can exploit them.
Defensive Reverse Engineering
A defensive approach puts security mechanisms in place to prevent an attacker from accessing and exploiting vulnerabilities.
Endpoints are a favorite target for malware attacks. Endpoints are devices, such as laptops, mobile phones, tablets, or desktops, that are physically at the endpoint of a network.
The following table explains some of the key aspects of endpoint security.
| Endpoint Security | Description |
|---|---|
| Vulnerability | Often, endpoints are personal devices brought to the network by individuals. Endpoints:
|
| Protection | To protect endpoints:
|
Reverse Engineering Malware
Important cyber security concepts to consider when you reverse engineer malware include:
- Reverse engineering malware programs can help you understand how the malware works and its capabilities. Reverse engineer malware to extract the code from a binary executable.
- Reverse engineering allows you to examine the code closely. This may help you discover the source of the code.
- Some malware may be obfuscated, making it more challenging to detect, disassemble, or break down.
- You can analyze malware in a sandbox environment to protect your system.
- Some malware can tell if it is being run in a sandbox. It will stop running, run only code that is not dangerous, or it may release a logic bomb.
- There are many tools available for security analysts to reverse engineer malware.
Reverse Engineering Tools
There are four categories of reverse engineering tools:
| Tool Type | Description |
|---|---|
| Disassembler | A disassembly translates binaries into assembler language. |
| Decompiler | A decompiler translates binaries into high-level languages. |
| Hex editor | A hex editor allows you to:
|
| Debugger | A debugger allows you to:
|
There are three common methods of decomposing a binary into a state that is understandable for inspection through disassemblers and decompilers. These four methods are described in the following table.
| Method | Description |
|---|---|
| Machine code | With the machine code method:
|
| Assembly code | With the assembly code method:
If you choose assembly code, it is best to use a security analyst who can reconstruct the programming logic using specialized software tools. |
| Hex editor | With the high-level code method:
|
Some of the most popular disassembler and decompiler tools are described in the following table.
| Tool | Description |
|---|---|
| IDA Pro | IDA Pro is an interactive disassembler for analyzing multiple kinds of malware. IDA Pro:
|
| Ghidra | Ghidra is an NSA open-source disassembler and decompiler. Ghidra:
|
| Binary Ninja | Binary Ninja is a disassembler and decompiler created by hackers. Binary Ninja:
|
| Hopper | Hopper is a disassembler, decompiler, and debugger. Hopper:
|
| Radare2 | Radare2 is an open-source decompiler. Radare2:
|