- backhaul network
- Backbone Network
Chapter 6: Infrastructure for Transportation Cyber-Physical Systems
SMART CITIES - INFRASTRUCTURE AND TRANSPORT OF THE FUTURE
Smart Cities - Infrastructure and Transport of the Future
OBJECTIVES
- Introduction
- Networking among data infrastructure
- Data collection and ingest
- Data processing engines
- Serving layer
- Transportation Cyber-Physical Systems infrastructure as code
- Future direction
- Summary and conclusions
1. INTRODUCTION
- To meet the complex data challenges of TCPS, standard data infrastructure must evolve to cope with the characteristics of TCPS data which can be described using ‘5Vs of big data’:
- (1) volume,
- (2) variety,
- (3) velocity,
- (4) veracity and
- (5) value.
- A data infrastructure to accommodate these characteristics called lambda architecture (LA).
- As shown in Fig. 6.2, the data infrastructure in LA is divided into four primary components:
- the data layer,
- the batch layer,
- the stream layer and
- the serving layer.
- The batch layer is consisted of components that can store and process massive amount of data without a real-time service-level requirement.
- Currently, one of the most popular software ecosystems that is being used in the batch layer is the Hadoop ecosystem, which includes the Hadoop Distributed File System (HDFS) for large-scale storage and the Hadoop MapReduce framework for data processing.
- The stream layer does not maintain any persistent storage component. Instead, it relies on streaming data processing infrastructure that can ingest and process data in real time.
- The serving layer is where users can interact with the data stored on the system using applications written in different programming languages.
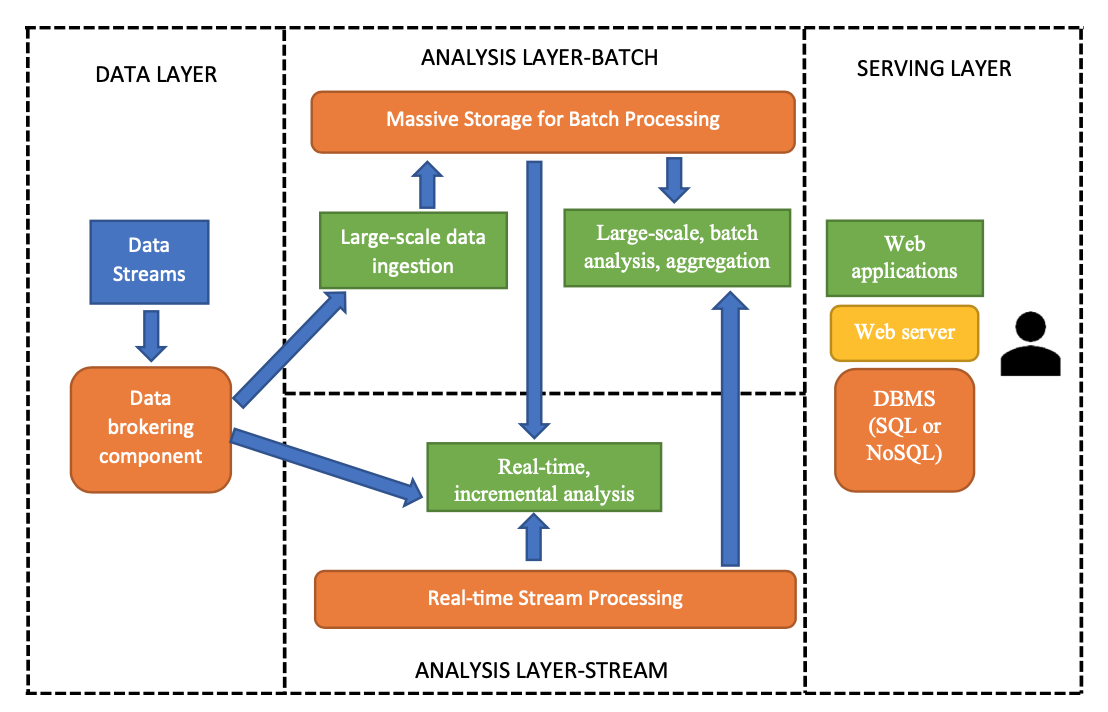
Figure 6.2 Lambda architecture for data infrastructure.
2. NETWORKING AMONG DATA INFRASTRUCTURE
- In TCPS, infrastructure, vehicles and people collaborate to support the application requirements of both end users and other stakeholders.
- Data infrastructure, a centralised, distributed or centralised- distributed architecture, needs to communicate with data senders, data receivers and among components of the data infrastructure itself.
- These communications take place either wirelessly or through wired mediums.
- Data infrastructure could include one layer or multiple layers of data storage and processors, depending on the application requirements.
- The United States Department of Transportation (USDOT) has supported the development of the Connected Vehicle Reference Implementation Architecture (CVRIA) as a guidance for developing connected vehicle applications and infrastructures.
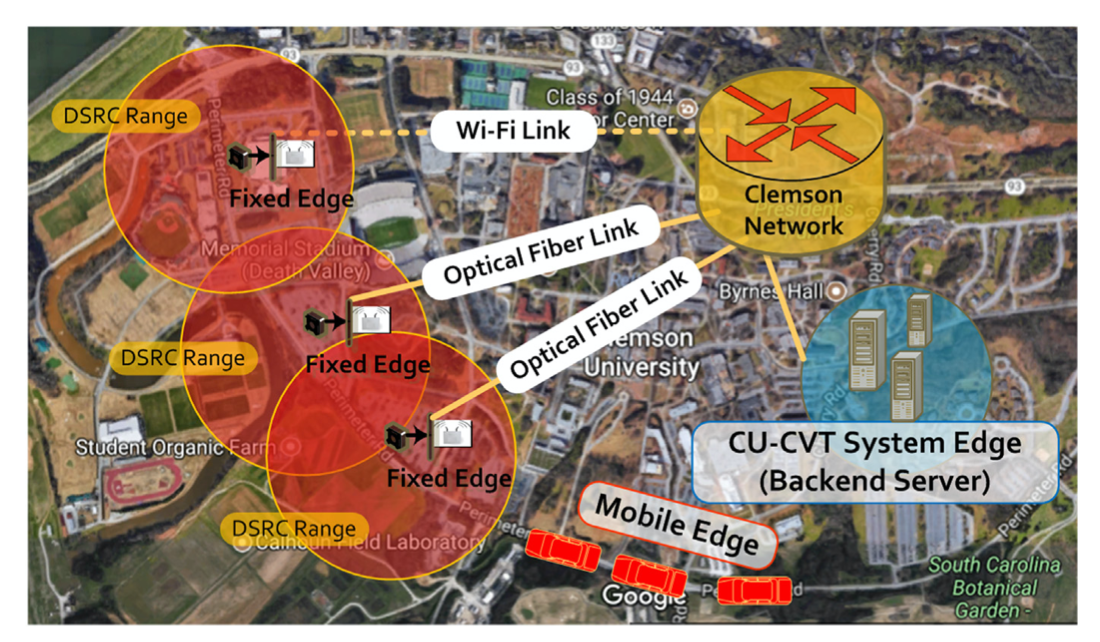
Figure 6.4 Vehicles and data infrastructure connected through different communication mediums [11].
3. DATA COLLECTION AND INGEST
- The first process that takes place within the TCPS data processing and decision support infrastructure is the collection of the data.
- TCPS can have a wide variety of different data sources and needs to be able to quickly and efficiently store and capture all the data from these devices.
- Once these data are collected and stored, it needs to be ingested and sent off to perform analytics on the data to extract the meaningful data.
- This is typically done through a data brokering component that manages where the data are sent and how they are processed.
3.1 TRANSPORTATION CYBER-PHYSICAL SYSTEMS DATA SOURCE CHALLENGES
- TCPS data can come from a variety of sources such as sensors and cameras that are connected to traffic lights, connected vehicles, satellites and even travellers.
- Each of these sources produces different types of data that pertain to different aspects of a TCPS such as location, weather, route of travel, accident avoidance and overall infrastructure performance.
- These different types of data need to be processed using different methods.
- Some of these data collected require very little to zero processing, for example, the count of vehicles that passed a certain location during a certain period, whereas other collected data require significantly more processing such as a video feed from a CCTV camera.
- This wide variability in the type of data and the processing power required to obtain the required insights from the data greatly impacts the type of data infrastructure utilised by TCPS.
- 有关收养的法律
- the laws pertaining to adoption
- For those TCPS that require more processing intensive tasks, the underlying data infrastructure needs to not only be able to handle the amount of data being generated but also be able to process the same data efficiently.
- The amount of data being collected by the TCPS can be on the scale of petabytes which poses an issue with the storage of such a large amount of data.
- On top of the storage issue, there is the issue of accessing and processing the data.
- This requires robust processing engines and vast amounts of infrastructure to be feasible.
- Another unique aspect of a TCPS is the way that the data are transmitted to the collection site.
- Some of the data collected by the TCPS come from sensors and other devices mounted on moving vehicles which poses a unique challenge.
3.2 DATA BROKERING INFRASTRUCTURE
With various components of the batch layer and stream layer, a TCPS data infrastructure is essentially a large-scale distributed system.
As a result, it faces the same challenges when scaling up the communication infrastructure.
These challenges include complex environments, heterogeneity in hardware and software components, dynamic and flexible deployment and high reliability, throughput and resiliency.
TCPS data infrastructure can then leverage the same solution that distributed systems have, which is to implement a message-oriented middleware (MOM).
In this case, messages are data elements being transferred from data sources to various data storage and processing components.
With MOM, data are sent from sources, called producers, to a queue, called broker.
The destination processing entities called consumers can acquire data actively by pulling from the broker or passively by having the data pushed by the broker.
Some advantages of having a MOM infrastructure instead of using remote procedure call among components are listed as follows:
- Communications between producers and consumers are asynchronous and loosely coupled.
- Data losses through network of system failure are prevented due to intermediate in-memory storage on brokers.
- As participants in communication patterns are loosely coupled, it is easier to scale individual components within the data infrastructure.
- Decoupled communication also leads to reduction of failure propagation.
4. DATA PROCESSING ENGINES
After the data have been collected and ingested, the next step is to perform analytics on the data to get the information required by the TCPS.
There are two general classes of processing engines that can be utilised by TCPS that we will be discussing: batch processing engines and stream processing engines.
Each class performs different analyses which provide valuable insight into the functionality of the TCPS.
4.1 BATCH PROCESSING ENGINES FOR TRANSPORTATION CYBER-PHYSICAL SYSTEMS
Fig. 6.5 provides an overview of Hadoop Distributed File System (HDFS)’ architectural design.
From a user’s perspective, visual observations of data stored in HDFS are like those of data stored in a standard Linux operating system.
In fact, many command-line data operations in HDFS use the same keywords as their Linux counterparts.
To ensure resiliency and reliability, HDFS utilises a heartbeat model in which the DataNodes must periodically contact the Name-Node to confirm their active status.
If a DataNode fails to do so, the NameNode will proactively initiate the process to replicate all blocks associated with this DataNode onto other DataNodes.
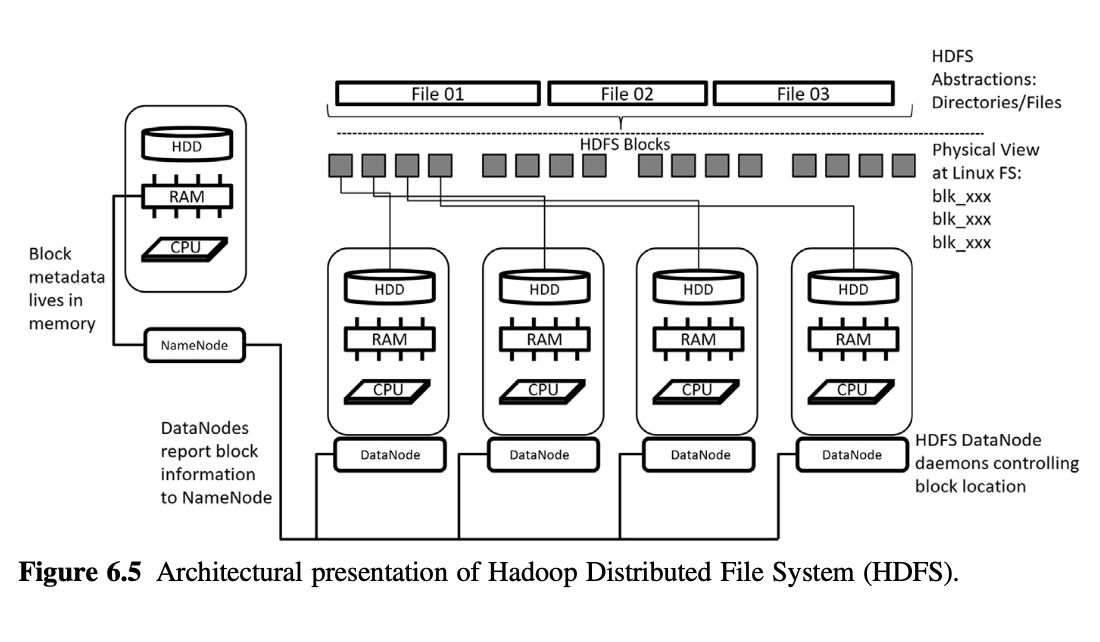
Figure 6.5 Architectural presentation of Hadoop Distributed File System (HDFS).
In a data processing operation on HDFS, the programming codes developed for the Map phase will be executed on all individual data blocks.
The Hadoop MapReduce framework will spawn map tasks on DataNodes that physically store these blocks and effectively move computation to data.
Each map task would emit intermediate data under the form of <Key, Value> pairs.
We could think of a <Key, Value> pair as a data element, where Key represents a distinguishing characteristic of this data element (multiple data element can have similar distinguishing characteristics) and Value represents the actual relevant contents of this element.
These intermediate data elements are stored in memory and spilt over into local hard drives as they are generated.
After all Map tasks are completed, the Hadoop MapReduce framework aggregates and sorts all pairs based on their Keys.
These intermediate data elements are stored in memory and spilt over into local hard drives as they are generated.
This sentence means that when intermediate data (temporary data produced during processing) is created, it is first kept in memory (RAM) to enable faster access and processing. However, if there is too much data to fit into memory, some of it overflows or "spills" onto the local hard drive, where it is stored temporarily. This approach balances the need for quick access with available memory limits. 这句话的意思是,当生成中间数据(处理过程中产生的临时数据)时,首先将其保存在内存(RAM)中,以便更快地访问和处理。然而,如果数据量过大以至于内存不足,一部分数据会“溢出”到本地硬盘上,暂时存储在那里。这种方法在满足快速访问需求的同时,平衡了内存的限制。
The data is not saved permanently. The intermediate data stored in memory or on the local hard drive is typically temporary and used only for the duration of the current processing task. Once the task is completed or the data is no longer needed, it will usually be deleted or replaced. This temporary storage is mainly for efficiency in processing rather than for long-term data storage. 这些数据不会被永久保存。保存在内存或本地硬盘上的中间数据通常是临时的,仅在当前处理任务的持续时间内使用。一旦任务完成或数据不再需要,通常会被删除或替换。这个临时存储主要是为了提高处理效率,而不是用于长期存储数据。
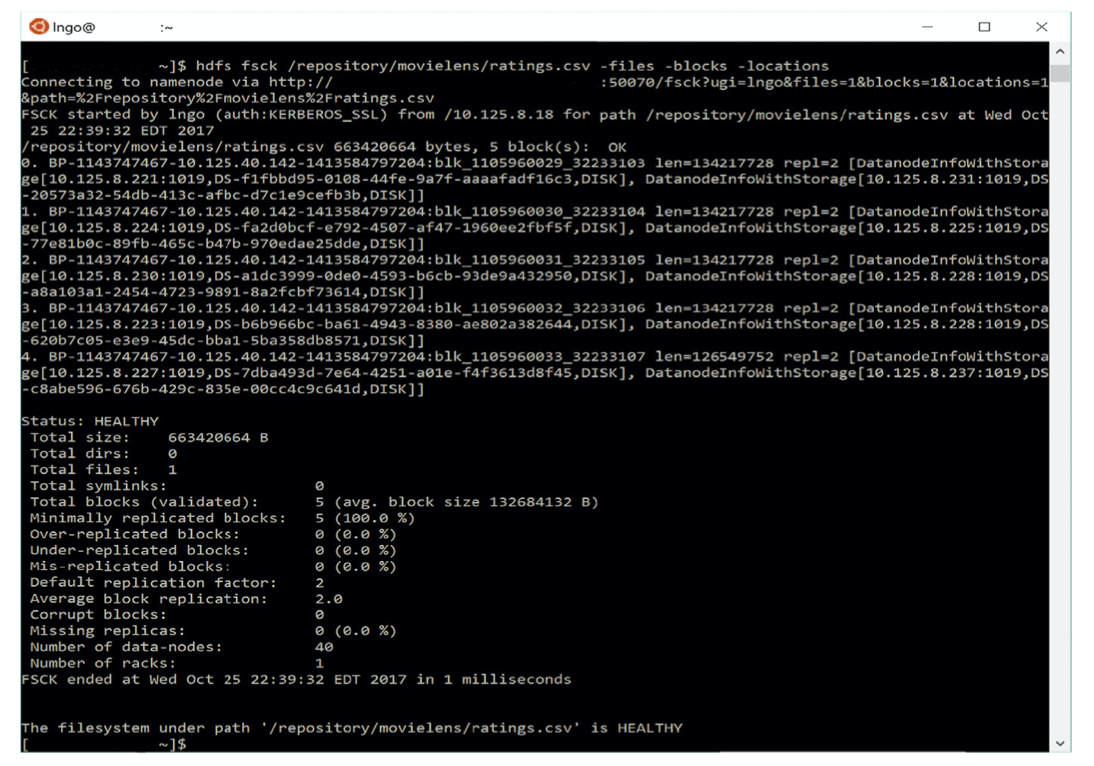
Figure 6.6 Example Hadoop Distributed File System’ block distributions.
Behind the scene, Hadoop MapReduce framework takes care of several critical technical steps.
To support parallelisation, it takes advantage of the fact that data stored on HDFS are already split and distributed across multiple DataNodes.
The Hadoop MapReduce framework and HDFS are the core components of the Hadoop ecosystem, which provide a reliable and highly scalable environment to support data processing.
However, due to the complexity in algorithmic designs (everything must be mapped to Map and Reduce) and overhead costs (Hadoop components are implemented using Java Virtual Machines), it is suitable for batch jobs on massive amount of data but not for interactive jobs on smaller data sets.
The Hadoop core components are among the top candidates for the batch layer of a data infrastructure.
4.2 STREAM PROCESSING ENGINES
The batch layer is more suitable for data processing tasks that aggregate massive amount of data, noninteractive, and do not require real time or near-real-time response rate.
Therefore, it is the responsibility of the stream layer to work on small- or medium-sized data in interactive manner to provide outputs in real time.
It should be noted that Apache Spark still utilises the MapReduce programming paradigm.
However, Apache Spark is implemented such that all data (original data, intermediate data and final results) are maintained in memory and reusable/accessible across different stages of interactive jobs.
Spark’s operations are classified into transformations or actions.
Transformations include operations that are pleasantly parallel in nature and will result in a new resilient distributed datasets (RDD) abstraction from existing RDD.
Transformations include operations that are pleasantly parallel in nature and will result in a new resilient distributed datasets (RDD) abstraction from existing RDD.
This sentence means that "transformations" are actions that work well with parallel processing. Since each transformation operation can be done independently on different data parts, they are well-suited for distributing across multiple computers in a cluster.
When you perform a transformation, it doesn’t change the original dataset (RDD). Instead, it creates a new Resilient Distributed Dataset (RDD) based on the applied operation. RDDs are special data structures designed for distributed computing, allowing data to be processed across many machines efficiently while being fault-tolerant.
这句话的意思是“转换”是一种适合并行处理的操作。由于每个转换操作可以在不同的数据部分上独立进行,所以它们非常适合在集群中的多台计算机上分布执行。
当您进行转换时,它不会更改原始数据集(RDD),而是基于应用的操作创建一个新的弹性分布式数据集 (RDD)。RDD 是为分布式计算设计的特殊数据结构,可以在多台机器上高效地处理数据,同时具备容错能力。
- The real-time streaming analytic aspects of Spark is enabled by creating another data entry point called StreamingContext which is connected to the SparkContext and allows data to be continuously inserted into the Spark cluster’s RDD environment over time.
- Unlike Flink, Spark does not work with actual continuous data streams but discretise these streams into streams of small, user-defined timing windows.
- These are called discretized streams (DStreams).
- Each timing window within a DStream is considered an RDD, and all standard Spark programming functionalities and practices are applicable on these RDD.
- SparkStream has been observed to achieve twice the throughput of Storm, another streaming engine developed by Twitter.
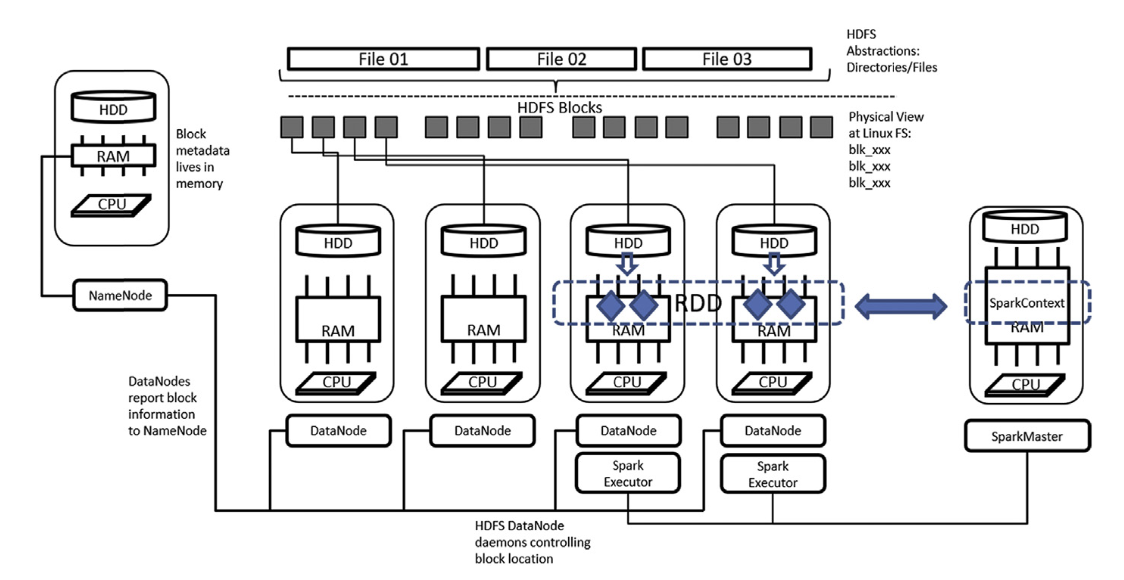
Figure 6.7 Spark deployment inside Hadoop infrastructure. HDFS, Hadoop Distributed File System; RDD, resilient distributed datasets; HDD, hard disk drive.
5. SERVING LAYER
In the lambda architecture (LA), the serving layer is where end users can interact with the data and analytical results stored within the infrastructure.
This is can be done via a web-based application where a user can interact with the data via a web browser.
However, there are also other software tools and options for interacting with the data at the lower levels utilising various application programming interfaces (APIs) which can also be categorised into the serving layer.
At the batch layer, the Hadoop MapReduce framework supports execution of native Python and R codes driven by the map and reduce tasks.
With the Hadoop streaming library, which is part of the core Hadoop MapReduce, executable binaries (in this case Python and R programs) can be specified as map and reduce tasks and utilise Linux standard input and output to read data from HDFS’ data blocks.
There also exists APIs within Python and R to support more features from the Hadoop ecosystem.
6. TRANSPORTATION CYBER-PHYSICAL SYSTEMS INFRASTRUCTURE AS CODE
The TCPS data infrastructure required to collect, store, distribute and process the data generated by TCPS can be quite large and complex.
Not to mention that getting the resources within the infrastructure to work at maximum efficiency and effectiveness can be a daunting and time-consuming task that can require many configuration changes, architecture iterations and debugging.
The infrastructure as code (IaC) paradigm aims to change this by allowing users to create, modify and remove infrastructure through code.
IaC is an approach to using cloud era technologies to build and manage dynamic infrastructure.
It treats the infrastructure and the tools and services that manage the infrastructure itself as a software system, adapting software engineering practices to manage changes to the system in a structured safe way.
6.1 TRANSPORTATION CYBER-PHYSICAL SYSTEMS CLOUD INFRASTRUCTURE AS CODE
- Cloud computing has become increasingly popular over the past few years due in partto its flexibility.
- Cloud computing allows users to scale up and scale down their infrastructure based upon the amount of demand which can be particularly useful for TCPS as there are peak times where a lot of data processing is required and other times where very little data processing is required.
- However, this flexibility in scaling up and down does require some additional automation to be performed during the processes of creating, provisioning and removing the infrastructure to ensure that these actions are performed in a consistent and trackable manner.
- This is where IaC can be utilized effectively and efficiently.
- Many cloud computing providers have their own IaC solutions that are designed to help users to create, modify and delete their infrastructure within the cloud.
- Amazon Web Services (AWS) has a service called CloudFormation that allows users to use a simple text file, written in JSON or YAML, to model and provision, in an automated and secure manner, all the resources required for the infrastructure.

Figure 6.8 Sample CloudFormation template to launch an Amazon Web Services EC2 instance [24].
6.2 INTERNET OF THINGS INFRASTRUCTURE AS CODE
Along with the lower-level compute IaC, the cloud also allows for Internet of Things device and sensor infrastructure to be created, modified and removed through code.
This process is a little different than the compute infrastructure, as this process does not involve deploying actual resources, such as sensors, but rather refers to the ability to manage and update the infrastructure.
One such solution is Amazon Greengrass, a software solution that allows a user run a variety of tasks including messaging, data caching, sync, machine learning, and local compute securely on connected devices.
Greengrass uses familiar programming models and languages allowing users to create and test device software in the cloud first and then deploy it to the devices.
This allows for the quick code and device prototyping and better change tracking regarding the software running on the sensors and devices deployed out in the field.
7. FUTURE DIRECTION
Over the next few years, the amount of data being generated by TCPS will continue to grow quickly.
This will lead to an increased need for more efficient and scalable data processing of the TCPS data.
This will require a tighter integration of the traditional data processing systems described in this chapter along with the flexibility and scalability provided by IaC.
By utilising IaC, TCPS will be able to dynamically adjust to handle an increase in the amount of data as more vehicles and other devices connect to the system.
This will keep TCPS running efficiently and effectively without the administrators of the system having to worry about the ever-changing data processing requirements.
8. SUMMARY AND CONCLUSIONS
- Within TCPS the data are the most important information that is produced.
- The data are what contains the information required to keep the TCPS operational and enable their functionality.
- Similarity, without the data processing infrastructure, the TCPS would not be able to obtain or produce the information required to maintain usability.
- As the requirements for data storage and processing change, the data infrastructure behind the TCPS will adapt with it and lead to even more efficient and effective systems.
- IaC will allow TCPS to automatically adapt to changes in demand and will allow for faster iteration and debugging when updating the underlying infrastructure.
- This will allow the people working on these systems to focus more on innovating and less on maintaining and managing the current systems.