CYB306 Cyber-Physical Vehicle System Security
Chapter 7: Data Management Issues in Cyber-Physical Systems
SMART DATA ANALYTICS: BMW GROUP RELIES ON INTELLIGENT USE OF PRODUCTION DATA.
Smart Data Analytics: BMW Group relies on intelligent use of production data.
OBJECTIVES
- Cyber-physical systems: an interdisciplinary confluence
- Cyber-physical systems are diverse
- Data management issues
- Database systems for cyber-physical systems
- Data analytics for cyber-physical systems
- Current trends and research issues
1. CYBER- PHYSICAL SYSTEMS: AN INTERDISCIPLIN ARY CONFLUENCE
CPS are a synergistic confluence of various subdisciplines, including model- based system design, formal methods for system specification and verification, real-time systems, embedded systems, sensors and actuators, distributed algorithms, concurrency theory, control theory, Internet of Things (IoT), cognitive computing and high-performance computing.
CPS-level characteristics include system specification and verification, stability and safety, communications and interoperability, performance and scalability, reliability and dependability and privacy and security.
Other facetsinclude cybersecurity, power and energy management, human factors and system usability.
CPS are also transformative given their potential for dramatically enhancing the capabilities of existing applications and ushering in innovative devices such as an artificial pancreas.
CPS are playing increasingly critical roles in power generation and distribution, health care, manufacturing and transportation (air, ground and sea).
Since CPS-based systems communicate and respond faster than humans, their potential to provide efficiency, adaptability, autonomy and reliability is also greater.
Data analytics (DA), machine learning (ML) and databases play a critical role in control and decision-making on physical components/systems.
2. CYBER- PHYSICAL SYSTEMS ARE DIVERSE
CPS hardware and software architectures vary widely.
An example of Transportation Cyber-Physical Systems (TCPS) can be given for a cybersecurity application of TCPS at an unsignalised intersection.
In this example, a software-based security threat detection system, residing in a server, is overseeing one or more roadside units at a stop-controlled unsignalised intersection.
Here roadside units are alerting the side street vehicles when it is safe to cross the main street traffic that has the right of way at an unsignalised intersection.
However, any malicious cyberattack on the roadside units could jeopardise the reliability of providing a reliable warning to side street traffic, which can result in potential crashes at that intersection.
Once the software-based security threat detection software detects a security attack on a roadside unit in a connected vehicle environment at a stop-controlled unsignalized intersection, it alerts the roadside unit about the attack and instructs the roadside unit to activate preselected security protection system for such an attack.
Here, the physical world, vehicles and roadside units and cyber-infrastructure such as a server and analytics such as the security detection software are connected through a wireless medium to form TCPS to thwart a cyberattack at a stop-controlled unsignailsed intersection operating a Stop Sign Gap Assist connected vehicle application.
3. DATA MANAGEMENT ISSUES
CPS need a range of data management solutions depending on their on-board computing power and energy constraints.
Some CPS may offload compute-intensive tasks to data centres and receive results back in near real time, while others need real-time on-board DA capability.
There are four data-related issues for CPS:
- (1) choice of a data management system that closely matches with the functional and nonfunctional requirements of CPS,
- (2) dealing with data quality,
- (3) dealing with human cognitive biases and
- (4) data privacy and security issues.
The economies of scale offered by cloud platforms and their ubiquity make a compelling case for using them for CPS data management and analytics.
3.1 DATA MANAGEMENT SYSTEM CHOICES
- Relational database management systems (RDBMS) are the backbone of almost all software applications until recently.
- Underlying the RDBMS is the relational data model for structuring data and the ISO/ANSI standard SQL for data manipulation and querying.
- The relational data model is based on first-order predicate logic and lends itself naturally for providing a declarative method for specifying queries on the database.
- The SQL language is originally based on relational algebra and tuple relational calculus.
- From the CPS perspective, we categorise DBMS into:
- (1) relational DBMS,
- (2) document-oriented DBMS,
- (3) graph-oriented DBMS,
- (4) column family DBMS,
- (5) native XML DBMS,
- (6) time series DBMS,
- (7) Resource Description Framework (RDF) stores and
- (8) keyevalue Stores.
Table 7.1 A Taxonomy for and Classification of Database Management Systems (DBMSs)
| Database Class | Salient Characteristics | Widely Used Systems |
|---|---|---|
| Relational DBMS | Two subclasses: row-oriented and column-oriented. Column-oriented RDBMS: optimised reads and writes for online transaction processing; enforces strong data integrity; provides transaction support, data distribution, data replication and fine-grained access control. Column-oriented: optimised reads for online analytical processing; enforces strong data integrity and provides distributed data analytics. | Oracle, MySQL, Microsoft SQL Server, PostgreSQL and DB2 |
| Document-oriented | Ideal for managing semistructured, arbitrarily nested hierarchical document data organised in the form of keyevalue pairs in JSON format; support flexible schema evolution; accommodate high data variability among data records. | MongoDB, Amazon DynamoDB, Couchbase, CouchDB, MarkLogic and Microsoft Azure Cosmos DB |
| Graph-oriented | Ideal for efficiently storing and flexibly querying relationship-rich data; powerful operators for graph traversals and identifying subgraphs and cliques based on relationship types. | Neo4j, Microsoft Azure Cosmos DB, OrientDB, Titan and ArangoDB |
| Column family | Ideal for efficiently storing sparse, nontransactional, and heterogeneous data and retrieving partial records; accommodate flexible and evolving database schema; tolerance to both network failures and temporary data inconsistency; increased processing power through horizontal scalability. | Cassandra, HBase, Microsoft Azure Cosmos DB, Microsoft Azure Table Storage, Accumulo and Google Cloud Bigtable |
| Native XML | Ideal for efficiently storing and retrieving sparse and hierarchically structured heterogeneous data with high variability from one record to another; all layers in an application see the same data model, and hence, there is no need for mapping of the data model between layers. | MarkLogic, Oracle Berkeley DB, Virtuoso, BaseX, webMethods Tamino, Sedna and eXist-db |
| Time series | Ideal for storing and retrieving time series data, which is data indexed by time; efficient execution of range queries; performance at scale; support for age-based data retention and archival. | InfluxDB, RRDtool, Graphite, OpenTSDB, Kdbþ, Druid and Prometheus |
| RDF stores | Also called triplestores are optimised for the storage and retrieval of triples; simple and uniform data model with a declarative query language named SPARQL; import/ export through standardised data interchange formats - N-triples and N-quads. | MarkLogic, Jena, Virtuoso, GraphDB, AllegroGraph and Stardog |
| Keyevalue stores | Optimised for storing keyevalue pairs to guarantee real-time retrieval independent of data volume; key-based lookup query mechanism; increased processing power through horizontal scalability; high availability and reliability. | Redis, Memcached, Microsoft Azure Cosmos DB, Hazelcast, Ehcache, Riak KV, OrientDB, Aerospike, ArangoDB and Caché |
3.2 DATA QUALITY ISSUES
CPS typically depend on artificial intelligence (AI) systems and ML algorithms for their operation.
Traditionally, there are two threads of data quality research.
- The first one is advanced by computer science researchers, and issues of interest include identification of duplicate data, resolving data inconsistencies, imputing missing data, and linking and integrating related data obtained from multiple sources.
- The second thread of data quality research is addressed by information systems researchers.
- Various dimensions used for data quality assessment using a data governance-driven framework.
- The dimensions include data governance, data specifications, integrity, consistency, currency, duplication, completeness, provenance, heterogeneity, accuracy, streaming data, outliers, dimensionality reduction, feature selection and extraction, business rules, gender bias, confidentiality and privacy and availability and access controls.
3.3 HUMAN COGNITIVE BIASES IN DECISION- MAKING
The human cognitive biases are listed as follows:
- Anchoring bias refers to the tendency of humans to use the first piece of information they receive as the standard to determine the validity of data received subsequently.
- Availability heuristic is related to peoples’ tendency to assign unreasonable information value to the data that are easily available to them. Convenience data sampling techniques best exemplifies the availability heuristic.
- Bandwagon effect points to the fact that the degree of belief in a hypothesis is proportional to the number of people who believe in that belief. This leads to irrational reasoning and false conclusions.
- Blind spot bias indicates that not being able to recognise one’s own bias is a bias in itself.
- Choice-supportive bias refers to the tendency of people to rationalise the choice they have made, though the choice may be faulty or not optimal. This bias leads to missing more optimal decisions.
- Clustering illusion alludes to the tendency of humans to hypothesise nonexisting patterns in random events. Actions based on these hypotheses have no logical foundation.
- Confirmation bias refers to the phenomenon exemplified by the saying birds of a feather flock together.
- Conservatism bias points to the fact that humans value existing evidence more than new evidence.
- Information bias refers to the tendency of humans to seek that information which does not affect action.
- Ostrich effect is the tendency to ignore information that is not pleasant or palatable.
- Outcome bias refers to judging the value of a decision exclusively on the outcome and ignoring the exact process involved in making the decision. This leads to not being able to identifying all the factors that affected the decision.
- Overconfidence encourages greater risk taking in decision-making.
- Placebo effect refers to the power of nothing - a desired outcome will happen by simply believing that it will happen.
- Pro-innovation bias is overvaluing the usefulness while overlooking its limitations.
- Recency is the tendency to place more prominence on newer data relative to old data.
- Salience is best exemplified by the metaphor low-hanging fruit. It refers to the tendency to focus on statistically improbable events over probable events.
- Selective perception is perceiving the world through the lens of our expectations.
- Stereotyping refers to overgeneralization, though significant differences exist in the data.
- Survivorship bias refers to an incorrect decision due to biased or imbalanced data and not being cognisant about the biased data.
- Zero-risk bias refers to tendency of avoiding quantifying uncertainty and reasoning with it.
3.4 CYBERSECURITY ISSUES IN DATA MANAGEMENT
The CPS pose the following key security challenges:
- CPS applications range widely in terms of security requirements.
- In emerging applications such as the IoT, the computing power of the CPS components is limited.
- CPS are systems comprised of heterogeneous components - different computing platforms and capabilities.
- While a CPS should secure data as in IT infrastructure environment, it should also consider security issues that span multiple systems and those that arise due to user interactions with these systems.
- CPS have strict timing requirements on the data in addition to security.
- CPS design approaches that do not consider security issues may render such CPS vulnerable to security breaches.
- The counteracting measures for cyberattacks on CPS should consider the interactions between the cyber and physical aspects of the systems.
- CPS may use different networking technologies (e.g., wired and wireless) and diverse protocols, which introduces additional challenges.
- Typically, CPS are highly autonomous systems with embedded intelligence. While this reduces manual intervention and supervision, it also necessitates protection against malicious attacks.
- Feedback loops play an important role in CPS control. Therefore, feedback data need to be protected against tampering attempts.
4. DATABASE SYSTEMS FOR CYBER-PHYSICAL SYSTEMS
Table 7.2 Common Database Security Threats
| Database Threat | Description |
|---|---|
| Excessive and unused privileges | When users are granted database privileges that exceed the requirements of their job function, privileges can be used to gain access to confidential information. Also, when employee job roles change, corresponding changes to access rights to sensitive data are often not updated. Per Imperva [20], 47% of companies report that their users have excessive rights. A query-level access control is used to restrict privileges to minimum required operations and data. |
| Privilege abuse | Users may abuse legitimate database privileges for unauthorised purposes. Database systems administrators (DBAs) have unlimited access to all data in the database. A DBA may choose to access unauthorised, sensitive application data directly without going through the application’s authorisation and access controls. Privilege abuse is an insider threat. In 2016, more than 65% of the data breach losses were attributed to privileges abuse [20]. Enforce policies restrict not only what data are accessible but also how the data are accessed. |
| SQL injection and insufficient application security | Hackers insert unauthorised or malicious SQL statements to get access to the data to copy or alter it. A query-level access control is effective in detecting unauthorised queries injected via web applications and database stored procedures. |
| Weak audit trail | Failure to collect detailed audit records of database activity represents a serious organisational risk on many levels. Fine-granular audit, unfortunately, degrades database performance. Native audit tools of the database vendors are typically inadequate to record the contextual details required to detect attacks and support security and compliance auditing. Network-based audit appliances operate independently of all users and offer granular data collection without performance penalty. Imperva notes that only 19% of companies perform database monitoring [20]. |
| Unsecured storage media | Unprotected backup storage media is often stolen. High-privilege users such as DBAs will often have direct physical access to the database servers. Such users can turnoff native audit mechanism and copy data by issuing SQL commands. To prevent this type of data breach, all database backup files should be encrypted. |
| Malware and platform vulnerabilities | Advanced attacks that blend multiple tactics such as spear phishing emails and malware are used to penetrate organisations and steal-sensitive data. Intrusion detection software and intrusion prevention software (IPS) are effective in detecting and blocking known database platform vulnerabilities and malware. |
| Platform vulnerabilities | Attackers exploit vulnerabilities in database management systems and the underlying operating systems. For example, attackers exploit vulnerabilities such as default accounts and passwords and database system configuration parameters to launch attacks. |
| Denial of service (DoS) | The attack renders the system unavailable to the authenticated and authorised users. Buffer overflows, data corruption, network flooding and resource consumption are typical DoS techniques. Resource consumption is unique to databases and is often overlooked. An attacker may rapidly open a large number of database connections. This in turn triggers the connection rate control, which will prevent legitimate users from consuming database server resources. DoS prevention measure should target multiple layers including the network, applications and databases. IPS and connection rate controls are effective in combating DoS. |
| Limited security expertise and education | Many smaller organisations lack the expertise required to implement data and application security controls and policies. This coupled with lack of user training opens doors to security breaches. Invest in security software and user training. |
4.1 CLUSTER-BASED DISTRIBUTED COMPUTING
Distributed computing is a paradigm in which networked computers solve computational problems through communication and coordination by passing messages.
Concurrent execution, absence of a global clock and independent failure of components characterise distributed systems.
In the context of NoSQL systems, distributed computing is a means to provide performance at scale and achieve high availability and reliability.
NoSQL architectures consist of several components (e.g., storage disks, CPUs, application servers) residing on networked computers.
The components communicateand coordinate their actions to achieve a common goal through mechanisms such as shared memory and message passing.
Client-server architecture is a widely used computing model for distributed applications. - A server provides a service which is made available to the clients through an API or protocol. - Typically, the server and clients reside on physically different computers and communicate over a network. However, the server and clients may reside on the same physical computer.
NoSQL systems provide their services as servers.
- A NoSQL server typically runs on a cluster in production environments.
- The responsibility for processing client requests and distributing and coordinating workload among various nodes can be centralised or distributed.
- A specific node is designated as the master and is responsible for intercepting client requests and delegating them to worker nodes.
- In this sense, the master node acts as a load balancer.
- The master node is also responsible for coordinating the activities of the entire cluster.
- This architecture simplifies cluster management, but the master node becomes the single point of failure.
- If the master node fails, a standby master takes over the responsibility.
- Shown in Fig. 7.2B is an alternative to the master-worker architecture, which is called master-master or peer-to-peer.
- All nodes in the cluster are treated equal.
- At any given point of time, a specific node is accorded the role of a master.
- If the master node fails, one of the remaining nodes is elected as the new master.
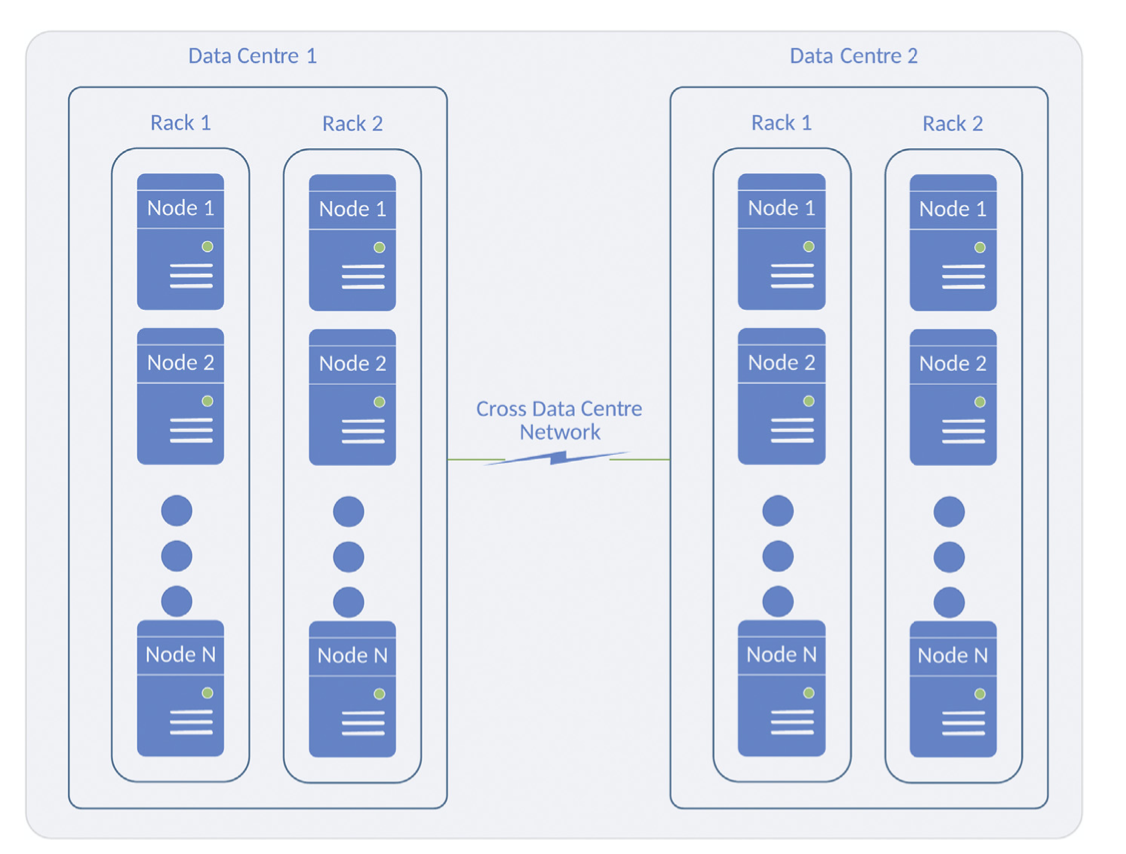
Figure 7.1 Data centre clustering. Reproduced with permission from V. Gudivada, Cognitive Computing: Concepts, Architectures, Systems and Applications, in: V. Gudivada, V. Raghavan, V. Govindaraju, C.R. Rao (Eds.), Cognitive Computing: Theory and Applications, Volume 35 of Handbook of Statistics, Elsevier, New York, NY, September 2016, 3e38.
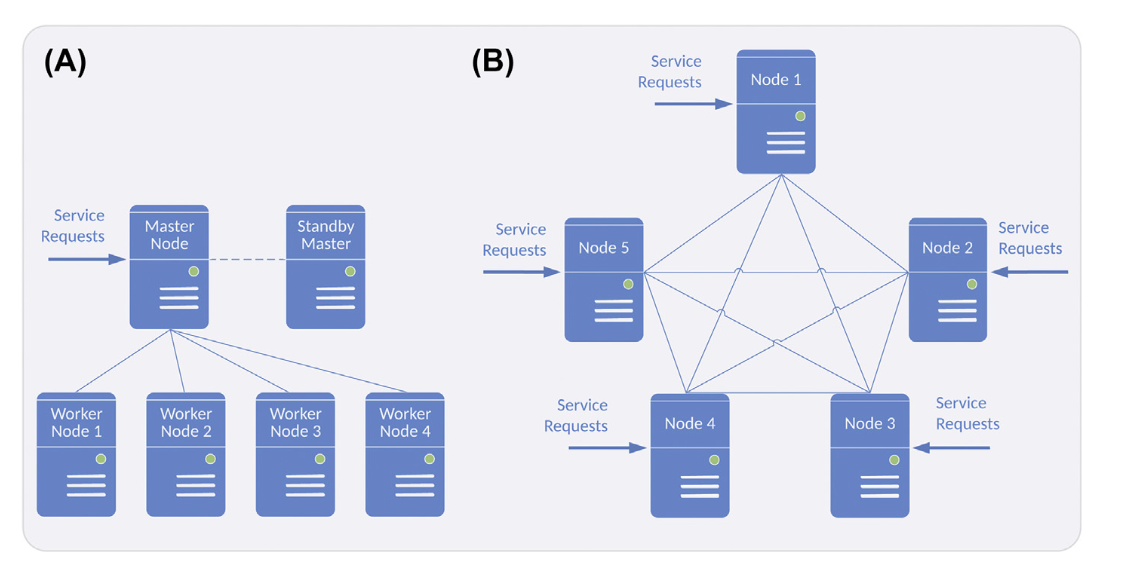
Figure 7.2 Shared-nothing cluster architecture. (A) Master-worker shared-nothing architecture and (B) master-master shared-nothing architecture. Reproduced with permission from V. Gudivada, Cognitive Computing: Concepts, Architectures, Systems and Applications, in: V. Gudivada, V. Raghavan, V. Govindaraju, C.R. Rao (Eds.), Cognitive Computing: Theory and Applications, Volume 35 of Handbook of Statistics, Elsevier, New York, NY, September 2016, 3e38.
4.2 RELAXED DATA CONSISTENCY REQUIREMENTS
- ACID is an acronym that stands for atomicity, consistency, isolation, and durability.
- ACID characterizes the desirable properties for transaction execution in relational database management systems.
- Atomicity refers to executing a database transaction as a single unit of work.
- Though the transaction may be comprised of several tasks, the atomicity property requires that all tasks be executed as a single unit of work — an all-or-nothing proposition.
- In contrast to ACID, NoSQL systems provide a range of options for maintaining data consistency through three design features – basic availability, soft state, and eventual consistency, which are referred to as BASE (a contrived acronym).
- Basic availability feature guarantees that the system is always available for read and write operations.
- This feature is essential for client applications to function despite network non-availability.
4.3 HASH FUNCTIONS
- Hash functions and related data structures play a critical role in NoSQL systems.
- A hash function takes a variable length sequence of bytes and returns a fixed-length sequence of bits.
- The input to the function is called the key and the returned result is called by various names including hash, hash value, message digest (MD5) or checksum.
- Most often a hash function will produce unique hash for a given key.
- MD5 and Secure Hash Algorithm (SHA) are widely used hash functions.
- MD5 algorithm produces a 128-bit hash value.
- SHA is designed by the US National Security Agency for cryptographic applications.
- SHA versions include SHA-1, SHA-2 and SHA-3.
- SHA-1 produces 160-bit output whereas SHA-2 and SHA-3 provide options for 224-, 256-, 383- and 512-bit hash values.
- For example, SHA-1 algorithm produces the hash code a5630b89be6530ae79f855ea90f218db8949ad28 (hexadecimal notation) given the string ‘cyber-physical systems’ as key.
- Hashing is used in NoSQL systems for determining in which node of a cluster to store a new document.
4.4 HASH TREES
- It is helpful to think of hashing as generating a fixed-length output as a unique and shortened representation for a given piece of data.
- A hash tree (aka Merkle tree) is a data structure in which every non-leaf node is labeled with the hash of the labels of its child nodes.
- One important use for hash trees is in efficient and secure verification of data transmitted between computers for veracity.
- Another use is in determining whether the content files in a hierarchical directory structure are same as its backup copy (aka replica).
- Also, if they are not the same, hash trees provide an efficient method to determine which files are different.
- Determining whether a directory and its replica are identical simply involves computing hash values of the corresponding top-level directories.
- If the hash values are equal, the directory and its replica are identical.
- NoSQL systems use hash trees to efficiently synchronise nodes that went into a disconnected state for a while from rest of the nodes in a database cluster.
4.5 CONSISTENT HASHING
- One way to assign records to the nodes of a database cluster is based on the value of the record key.
- If the key values are not uniformly distributed, this assignment may lead to hotspots - some nodes may store a great number of records while others may receive only a few.
- One way to circumvent this problem is to randomly assign a record to a node.
- An undesirable side effect of this is that the order of keys is lost.
- However, it may be highly desirable to keep all records of a geographic location on one node to improve locality.
- Column-oriented NoSQL systems such as HBase and Google’s BigTable store all records of a geographic location on one node, and the node is split into two when certain threshold is reached.
- Consistent hashing is a technique which limits this reshuffling of records when the number of nodes in the cluster is rebalanced - when nodes are added to or removed from the cluster.
- If
kis the number of keys andnis the number of cluster nodes, consistent hashing guarantees that on average no more thank/nkeys are remapped to new nodes. - In summary, consistent hashing plays a central role in minimising the amount of reshuffling when new nodes get added or existing nodes are removed from a distributed system.
- If
4.6 MEMORY-MAPPED FILES, DISTRIBUTED FILE SYSTEMS AND VECTOR CLOCKS
Some NoSQL systems employ memory-mapped files to increase I/O performance especially for large files.
A memory-mapped file is a segment of virtual memory which is associated with an operating system file or file-like resource (e.g., a device, shared memory) on a byte-for-byte correspondence.
However, they may preclude easy application migration from one platform to another.
Vector clock is an algorithm for synchronising data in a distributed system.
It is used to determine which version of data is the most up-to-date by reasoning about events based on event timestamps.
It is an extension of RDBMS multiversion concurrency control to multiple servers. Each server keeps its copy of vector clock.
When servers send and receive messages among themselves, vector clocks are incremented and attached with messages.
A partial order relationship is defined based on server vector clocks and is used to derive causal relationships between database item updates.
Riak, a keyevalue data model based NoSQL system, implements eventual data consistency using vector clocks.
4.7 DATA PARTITIONING, REPLICATION, VERSIONING AND COMPRESSION
- Data partitioning (aka sharding), replication and versioning are orthogonal concepts.
- Data partitioning and replication improve throughput of read and write operations, data availability and query performance.
- The range of key values of data records is called keyspace.
- Replication involves keeping multiple copies of the data on separate nodes for high availability and recoverability.
- In synchronous replication, writing of a data item x to node A is not complete until the writing of x to all its replica nodes is complete.
- Multiple copies of the same data are stored on different computers (aka nodes) to improve data availability and query performance.
- Maintaining multiple time-stamped copies of a data item is called versioning.
- It enables retrieving the value of a data item at certain point of time in the past.
- Versioning combined with replication can quickly lead to enormous demands on disk space.
- Data compression help to alleviate this problem.
- Some NoSQL systems also provide a feature for automatically purging the data after its expiration.
- This is a valuable feature for CPS applications where data have no value after certain time window.
4.8 ELASTICSEARCH: A SEARCH AND ANALYTICS ENGINE
Elasticsearch (ES) is a cluster-based distributed search and analytics engine, which offers horizontal scalability and excels in managing both unstructured and semistructured data.
It enables indexing textual documents at scale and searching for them using queries specified in plain text.
It enables indexing textual documents at scale and searching for them using queries specified in plain text.
Also, it facilitates adding custom search features to applications.
Search results can be enhanced using predictive analysis and relevancy ranking.
Tasks such as identify fraud and anomaly detection are well suited for ES given its near real-time processing capability.
ES does not require upfront database schema definition and the schema evolves with the application.
Lastly, the advanced query language of ES enables powerful and flexible querying.
4.8.1 ELASTICSEARCH ARCHITECTURE
ES logical architecture is shown in Fig. 7.3.
The components shown in the left column are open source and are collectively referred to as Elastic Stack.
Logstash is a full-fledged extract, transform and load platform for ingesting bulk data into ES.
In contrast, Beats is a light-weight component for ingesting real-time data.
The ES is the primary component which indexes documents and distributes indices across various nodes of its cluster.
ES offers an Hypertext Transport Protocol (HTTP) REST interface to enable applications and users to query ES indices.
It also offers several built-in algorithms for searching and scoring documents and customising the search results.
Kibana turns ES into a DA platform.
Kibana runs in web browser and offers an excellent user interface for querying and data visualisation.
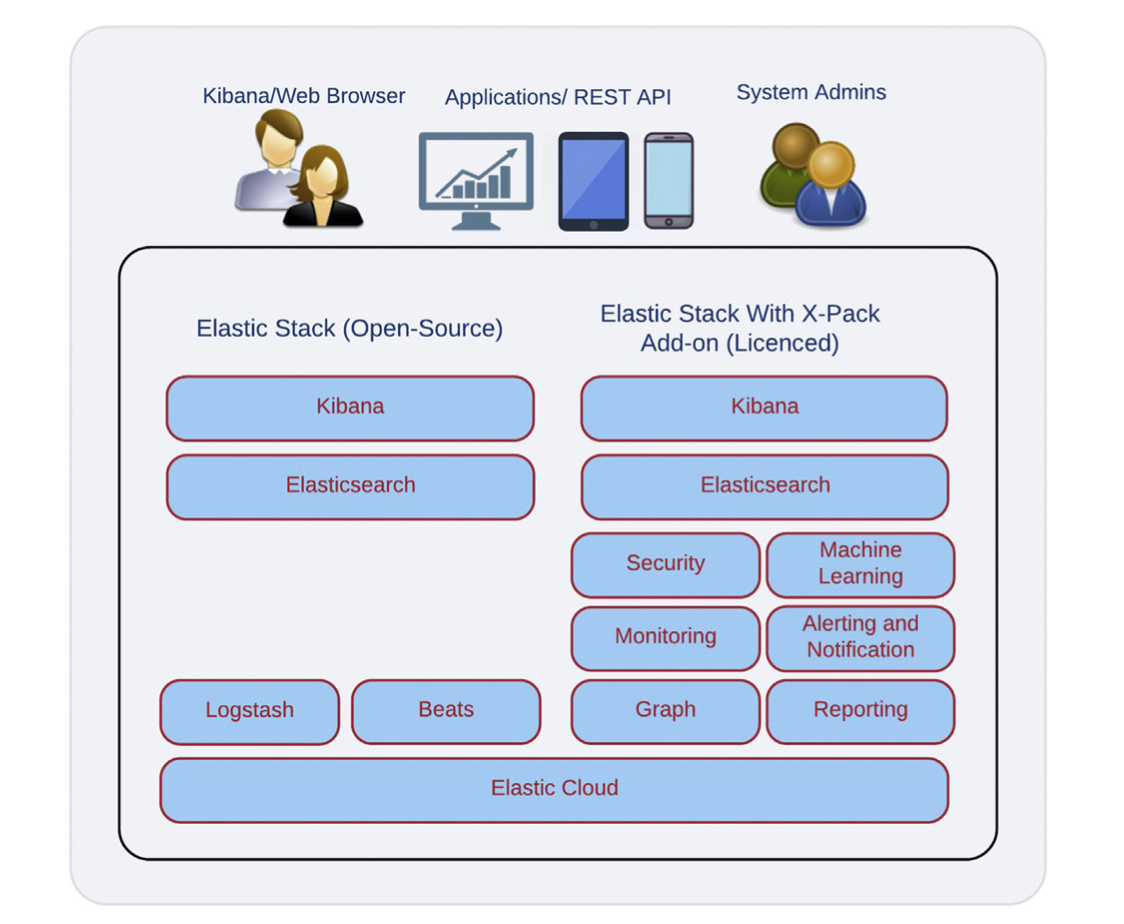
Figure 7.3 Elasticsearch logical architecture.
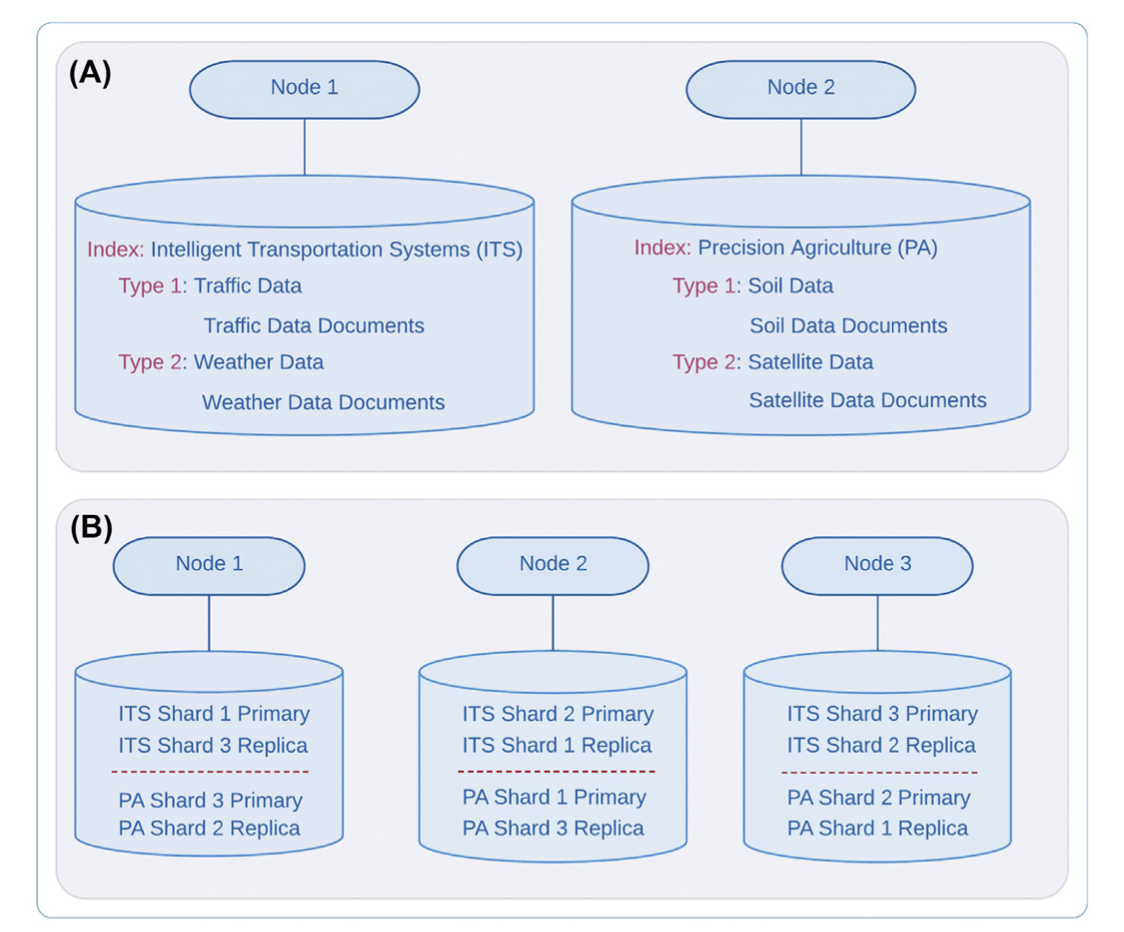
Figure 7.4 Sharding and replication in Elasticsearch. (A) Logical index structure and (B) physical index structure.
Table 7.3 Basic Elasticsearch (ES) Commands
| ES Command | Result Description |
|---|---|
| PUT/publications | Creates an index-named publications |
| PUT/publications/ journals | Creates a type-named journals for publications index PUT |
| PUT/publications/ books | Creates a type-named books for publications index PUT |
| PUT/publications/ chapters | Creates a type-named chapters for publications index |
| PUT/publications/ journals/1 {...} | Inserts a document of type journals with an id value of 1. The document content is specified on JSON format between { and } |
| GET/publications/ journals/1 | Retrieves a document of type journals with an id value of 1. The document is displayed in JSON format (Fig. 7.5) |
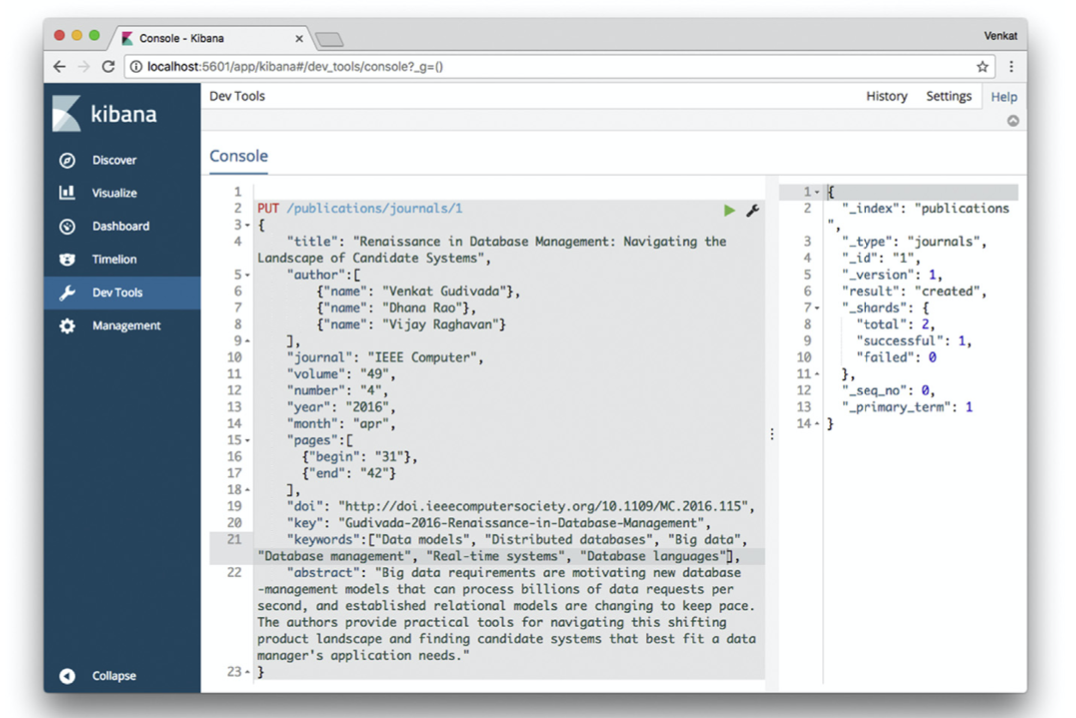
Figure 7.5 Results of executing the query ‘GET/publications/journals/1’ in Kibana.
5. DATA ANALYTICS FOR CYBER-PHYSICAL SYSTEMS
Data analytics (DA) is the science of drawing inferences, making predictions and gaining insights into heterogeneous data which is drawn and integrated from multiple data sources.
DA has its genesis in early versions of computer spreadsheets and RDBMS as online analytical processing.
Its evolution and advances were referred to by various names including data mining, business intelligence, visual analytics and cognitive analytics.
This evolution was primarily driven by ML, high-performance computing and big data.
DA has now become a pervasive term - image analytics, video analytics, text analytics and road traffic analytics - and now refers to the processes of extracting information from unstructured data and using this information for quantitative decision-making.
5.1 TYPES OF DATA ANALYTICS
- Based on its intended purpose, DA is categorised into four classes:
- descriptive,
- diagnostic,
- predictive and
- prescriptive.
- The classes are highly interrelated and their functional overlap is significant. These classes should be viewed as facets spanning a workflow rather than as four distinct categories.
- Regardless of the domain, DA is comprised of three activities: data acquisition, cleaning, transforming and loading; methods and algorithms and a computational platform that implicitly embodies workflows and best practices.
- The first activity involves preparing the input data and loading it into the computational platform.
- Various statistical and ML algorithms and approaches for data analysis are used to accomplish the second task.
- Lastly, the computational platform integrates the first two activities and provides interfaces for users and other applications.
5.2 DESCRIPTIVE ANALYTICS
- The goal of descriptive analytics is providing insights into the past leading to the present.
- It helps to learn from the past and use this knowledge to improve operational efficiencies and spot activities that consume disproportionate amounts of resources (aka resource drains).
- Descriptive statistics and exploratory data analysis (EDA) are the primary tools used for implementing descriptive analytics.
- Descriptive statistics provides tools to quantitatively describe the data in summary and graphical forms - measures of central tendency (mean, median and mode) and dispersion (minimum and maximum values, range, quantiles, standard deviation/variance, distribution skewness and kurtosis).
- EDA brings a visual dimension to descriptive analytics in the form of histograms, scatter plots, matrix plots, box-and-whisker plots, steamand-leaf diagrams, rootograms, resistant time series smoothing and bubble charts.
- This visual exploration helps to gain an intuitive understanding of the data and provides scaffolding for guided inquiry. It also helps to identify research questions for further investigation.
5.3 DIAGNOSTIC ANALYTICS
Diagnostic analytics helps to identify factors that are responsible for what has been observed through descriptive analytics.
In other words, it addresses the question ‘why did it happen?’
Several techniques including data mining and data warehousing are used to answer the question.
It is exploratory in nature and requires a human-in-the-loop.
Diagnostic analytics has been used in the education and learning domain for long under the name diagnostic assessment, which is a manual process.
5.4 PREDICTIVE ANALYTICS
Predictive analytics is about predicting the future based on the past.
It answers the ‘what if’ questions by building predictive models using inferential statistics and forecasting techniques.
Predictive analytics helps to implement preventive actions or change course.
Predictive models are probabilistic in nature and require substantial data for building the models.
Selecting which variables to use for building prediction models is referred to as variable/feature selection.
EDA often reveals which variables are good candidates for model building.
Classification algorithms such as naive Bayes, multilayer perceptron, neural networks, radial basis functions, support vector machines and k-nearest neighbours are also used in predictive analytics.
5.5 PRESCRIPTIVE ANALYTICS
Prescriptive analytics is closely associated with diagnostic and predictive analytics.
While diagnostic analytics answers the question ‘why did it happen?’ and prescriptive analytics helps to answer the question ‘what is likely to happen’, prescriptive analytics is used to increase the chance of realising(realizing) the desired events or diminishing the chances of occurrence of undesired events.
Prescriptive analytics is evolving into what is referred to as cognitive analytics.
Cognitive computing and cognitive science are the foundation of cognitive analytics.
One aspect of cognitive analytics is to compute multiple answers to questions and associate a degree of confidence with each answer.
Because of the inherent complexity and nascency of cognitive analytics, very few organisations have implemented it.
5.6 DATA ANALYTICS RESOURCES AND TOOLS
DA systems come in various forms with functional capabilities that vary widely.
Commercial vendors include SAS, Microsoft, Oracle, Teradata and Tableau Software.
Python, Java and R are very popular programming languages for implementing DA.
ML frameworks and libraries such as TensorFlow, Weka3 and Keras provide suitable abstraction to expedite DA applications.
The Apache UIMA project provides open-source frameworks, tools and annotators for information extraction from unstructured data.
Apache Hadoop and Spark are widely used open-source computing platforms for big data processing and cognitive analytics.
6. CURRENT TRENDS AND RESEARCH ISSUES
CPS applications and their complexity are growing at an exponential rate.
The behaviour of hardware and software in the cyberspace and the physical systems in the physical environment are well understood in isolation.
However, the emergent properties that arise when cyber systems interact with the physical world are complex and do not lend themselves for modelling and analysis.
Ad hoc approaches to CPS system design and implementation may result in systems that are brittle, are not scalable and lack design flexibility.
Formal approaches to CPS design with provision for automated verification and validation is required to minimise software bugs and hardware malfunction and thwart cybersecurity attacks.
CPS-based ITS, in general, and vehicle-to-vehicle and vehicle-to-infrastructure communication, in particular, will have significant impact on people in all walks of life.
CPS will have even more impact on automotive services such as testing, development, maintenance and repair.
Given the data quality and cybersecurity issues, CPS decision-making for missioncritical applications must necessarily involve human-in-the-loop.
/images/306/w0701.png