Cybersecurity System Audits
Chapter 5 – Business Resilience
Objectives
- Networked Applications
- Types of Disasters
- Business Continuity Planning Process
- Business Impact Analysis
- Recovery Procedures
- Restoration Procedures
- Types of tests
- Best Practices
- RTO and RPO
- Types of sites
- Server Clusters
Networked Applications and Client-Server Model
- Networked Applications:
- Business applications are typically networked, allowing multiple users across locations to access centrally installed applications.
- Data networks enable communication between central servers and user workstations, facilitating client-server and web-based applications.
- Client-Server Model:
- This model includes a central application server, database servers, and user workstations.
- The server handles requests from workstations, while the workstation manages user interactions and displays information.
- Users can input, view, or edit information through the application.
- The workstation processes inputs locally and sends them to the server, which updates and stores the data.
Web-Based Applications and Middleware Components
- Web-Based Applications:
- These applications are favored over client-server due to central business logic and lightweight data requirements.
- Business logic resides on central servers; users only need browsers, which reduces maintenance.
- Web-based applications are universally accessible across different operating systems, like Windows, macOS, and Linux.
- Middleware:
- Middleware acts as a bridge, coordinating processes between servers and managing complex transactions.
- Types of middleware include:
- TP Monitors: Manages business transactions across multiple servers.
- RPC Gateways: Facilitates communications between components using remote procedure calls.
- ORB Gateways: Manages transactions across distributed systems using CORBA or COM.
Challenges of Client-Server Applications
- Network Performance Issues:
- Client-server applications often create high data loads, slowing down the network, especially with multiple users.
- Example: A single database query may return thousands of records to a workstation, consuming bandwidth and reducing efficiency.
- High usage across workstations can lead to significant lag and application performance issues.
- Workstation Software Updates:
- Synchronizing software updates across all workstations is challenging.
- Updates must be applied simultaneously to maintain consistency, but some workstations may be offline or unavailable.
- This inconsistency can lead to application malfunctions or incompatibility issues for users with outdated software versions.
- Limitations and Shift to Web-Based Solutions:
- Due to these challenges, many organizations found client-server applications unsatisfactory.
- The rise of the World Wide Web offered a more scalable and efficient alternative for multi-user applications.
Advantages of Web-Based Applications
- Centralized Business Logic:
- All business logic is stored on one or more centralized servers.
- No need for workstation updates
- Efficient Display Logic:
- User interfaces, like forms and lists, are created with HTML, a simple and universal markup language.
- Reduces application complexity on workstations.
- Low Network Demand:
- Web applications minimize data load, sending only essential display data to workstations.
- Reduces bandwidth usage
- Minimal Updates for Workstations:
- Workstations require only browser updates
- Simplifies maintenance and ensures consistency across user devices.
- Broad Compatibility:
- Runs on various operating systems (e.g., Unix, Windows, macOS, Chrome OS, Linux).
- Offers flexibility and accessibility, supporting a range of devices without specific software requirements.
Understanding Business Resilience in IT Systems
- Definition of Business Resilience:
- Focuses on the stability and continuity of IT systems and business applications that support critical business processes.
- Ensures the ongoing functionality and survival of an organization during major disasters or disruptions.
- Importance of Resilience in the Digital Era:
- With digital transformation (DX), business processes are increasingly dependent on information technology.
- Enhancing IT resilience is essential to maintain organizational operations, minimize losses, and sustain productivity.
- Core Elements of Business Resilience:
- Business Continuity Planning (BCP): Proactively addresses potential disruptions to reduce risk and ensure critical functions continue.
- Disaster Recovery Planning (DRP): Outlines steps to recover IT systems and restore business operations after a disaster.
Understanding Disasters in Business Continuity
- Definition of Disasters:
- Disasters are unexpected, unplanned events that disrupt business operations, ranging from minor interruptions to complete operational shutdowns.
- The impact of a disaster can be confined to a small area or spread over a wide region, affecting entire networks or specific functions within an organization.
- Classification of Disasters:
- Natural Disasters: Events originating from natural phenomena that occur without human intervention.
- Human-Made Disasters: Incidents caused directly or indirectly by human activity.
Understanding and classifying disasters aids in creating effective Business Continuity Planning (BCP) strategies that prepare organizations for various disaster scenarios, enhancing resilience and minimizing recovery time.
Types of Disasters in Business Continuity Planning
- Natural Disasters:
- These are environmental phenomena with the potential to cause widespread damage to infrastructure, resources, and personnel. They include events occurring naturally in, on, or above the earth.
- Examples of Natural Disasters:
- Earthquakes: Sudden ground movements that may cause landslides, avalanches, and flooding.
- Volcanoes: Eruptions that release magma, ash, and pyroclastic flows, impacting vast regions.
- Landslides: Downhill earth movements that bury structures and reroute waterways.
Specific Types of Natural Disasters
- Avalanches: Rapid snow and debris flows, which can disrupt roads, utilities, and business sites.
- Wildfires: Natural fires in forests or grasslands that damage structures, equipment, and power lines.
- Tropical Cyclones: Strong storms (e.g., hurricanes) with winds up to 190 mph, causing flooding, wind damage, and power outages.
- Tornadoes: High-speed rotating winds reaching over 300 mph, capable of destroying buildings and infrastructure.
- Windstorms: High-velocity winds causing power outages and structural damage, albeit less intense than cyclones.
- Lightning: Electrical storms damaging power systems and triggering fires.
- Ice Storms: Freezing rain that accumulates on surfaces, collapsing power lines under weight.
- Hail: Large ice particles causing property damage (e.g., vehicles, buildings).
- Flooding: Overflowing water sources damaging infrastructure and disrupting operations.
- Tsunamis: Large ocean waves, often from seismic activity, that devastate coastlines (e.g., 2011 Japan tsunami).
Understanding Human-Made Disasters
- Definition:
- Human-made disasters result from direct or indirect human actions, leading to disruptions in business operations.
- These disasters cause localized or widespread damage, leading to potential long-term interruptions.
- Types of Human-Made Disasters:
- Civil Disturbances: Includes protests, riots, strikes, looting, and related actions like curfews or lockdowns, disrupting normal business activities.
- Utility Outages: Failures in essential services (electricity, water, communication) due to equipment malfunctions, sabotage, or natural events.
- Service Outages: IT and software disruptions from hardware failures, software bugs, or misconfigurations, affecting online services.
- Materials Shortages: Supply interruptions for essentials (food, fuel), affecting business continuity; reminiscent of past events like the 1970s fuel shortage.
- Fires: Unlike natural wildfires, human-caused fires impact buildings, equipment, and resources within businesses or homes.
How Disasters Affect Organizations
- Direct and Secondary Effects of Disasters
- Direct effects include physical damage to facilities, equipment, and data.
- Secondary effects may affect ongoing business operations, such as disrupted supply chains or delays in services.
- Risk Analysis in Business Continuity Planning (BCP)
- Risk analysis in the BCP process identifies potential disaster impacts on specific areas.
- Assesses primary, secondary, and downstream effects, helping to develop effective recovery and contingency plans.
- Requires understanding of the interdependencies of business processes and IT systems to prioritize resources effectively.
- Beyond Operational Impact: Long-term Effects
- Disasters can impact an organization’s brand, image, and reputation.
- Effective communication with customers, suppliers, and shareholders is crucial to managing perceptions and trust.
The Business Continuity Planning (BCP) Process
- Importance of Disaster Preparedness
- Effective BCP begins with understanding potential disasters and their organizational impacts.
- Emphasizes the need to "plan first, act later" to ensure readiness and minimize disruptions.
- BCP as a Life Cycle Process
- BCP is a continuous, adaptive process, not a one-time effort.
- Involves a series of activities aimed at maintaining ongoing disaster preparedness.
- Continually adapts to changing business conditions and operational needs.
- Key Elements in the BCP Life Cycle
- Develop BCP Policy: Define the overall framework and guidelines for continuity efforts.
- Conduct Business Impact Analysis (BIA): Assess potential impacts of disruptions on business functions.
- Perform Criticality Analysis: Identify critical systems and processes to prioritize in recovery.
The Business Continuity Planning (BCP) Process
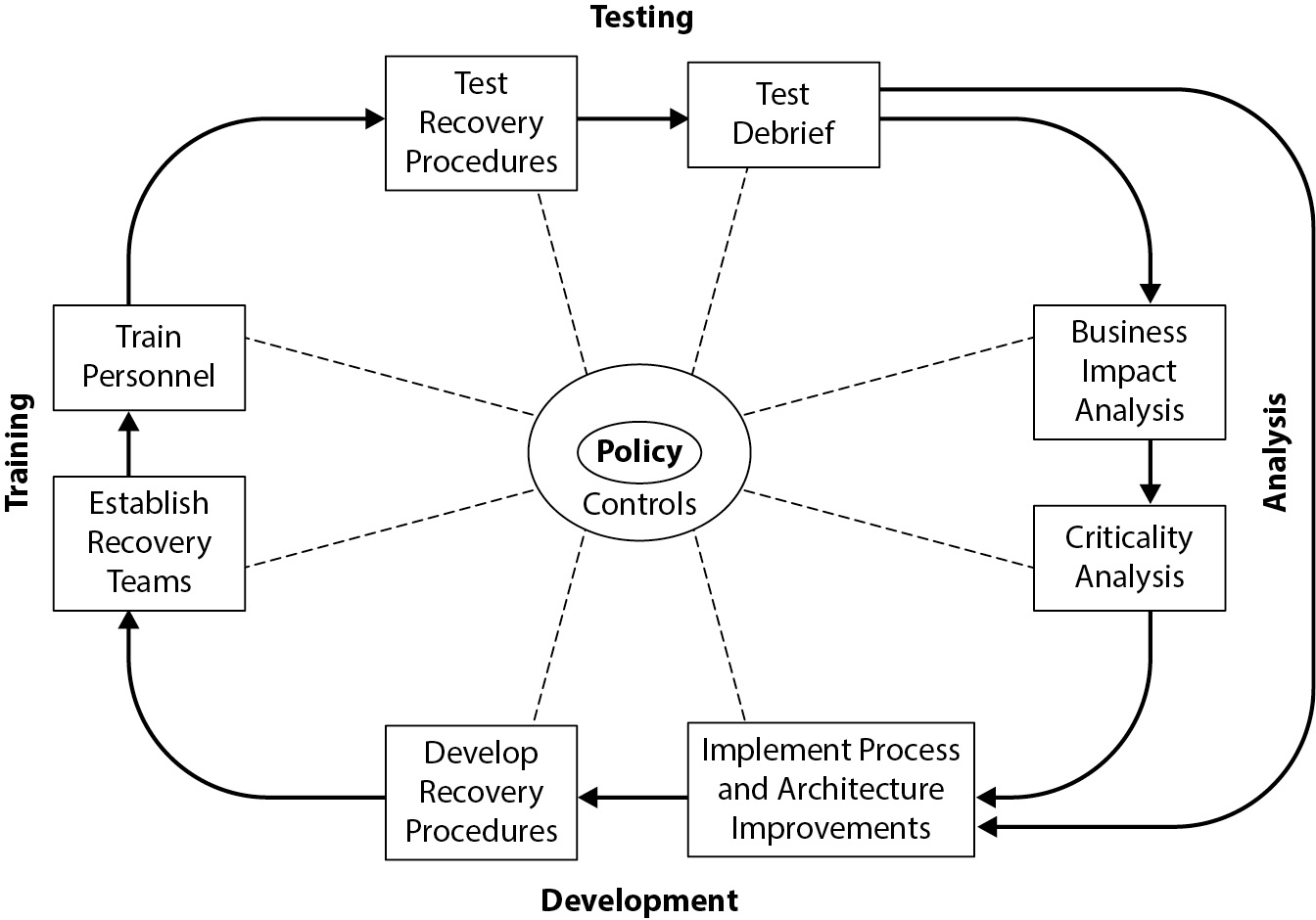
Figure 5-27 The BCP process life cycle
COBIT Controls in Business Continuity
- Role of COBIT DSS04 in BCP
- COBIT DSS04 ensures continuous service by providing eight key controls for a comprehensive BCP approach.
- Key COBIT DSS04 Controls
- Define BCP policy, objectives, and scope.
- Maintain a proactive continuity strategy.
- Develop and implement a response plan for business continuity.
- Exercise, test, and review the BCP to identify improvements.
- Conduct regular reviews and updates to enhance the continuity plan.
- Train staff on continuity procedures and roles.
- Manage and verify effective backup arrangements.
- Conduct a post-resumption review to evaluate BCP effectiveness.
Business Impact Analysis (BIA)
- BIA aims to evaluate the potential impact of various disaster scenarios on essential business operations.
- This assessment is a prerequisite to formulating robust continuity or recovery plans, ensuring preparedness for diverse disruptions.
- BIA involves in-depth analysis, beginning with identifying and documenting all critical business processes and IT systems.
- Inventorying key assets is foundational to understanding dependencies and potential impacts on operations.
- The initial phase in BIA is compiling a comprehensive list of critical processes and systems within the BCP project scope.
- Collected data is organized into a multi-column spreadsheet to visualize and analyze processes collectively.
- MTD (Maximum Tolerable Downtime) represents the longest duration a critical process can be disrupted before threatening the organization’s survival.
Establishing Key Recovery Targets – RTO and RPO
- Recovery Time Objective (RTO):
- Defines the maximum allowable time to restore a process after a disaster begins.
- RTO focuses on minimizing downtime to meet operational needs.
- Recovery Point Objective (RPO):
- Sets the acceptable data loss limit from the onset of a disaster.
- RPO highlights the importance of regular data backups and ensures data integrity.
- Using RTO and RPO in DR Planning:
- Both metrics guide the disaster recovery team in creating economical and effective recovery solutions.
- Aligns recovery strategies with organizational priorities and ensures quick, data-secure operations post-disruption.
Key Roles in Disaster Response
- Emergency Response Team:
- Acts as the first line of response during a disaster.
- Prioritizes evacuation, sheltering personnel, first aid, and triage of injured staff.
- May involve firefighting and other immediate actions to ensure safety.
- Command and Control (Emergency Management):
- Critical leadership role to coordinate disaster response efforts.
- Ensures resources are effectively allocated amidst competing priorities.
- May require rotation among personnel to manage fatigue in extended situations.
Communication Strategies in Disaster Response
- Internal Communications:
- Critical for relaying updates and commands between response teams and management.
- Maintains alignment on status and evolving priorities within the organization.
- Alternative methods should be prepared if standard channels like phones and emails fail.
- External Communications:
- Key audiences during a disaster include:
- Customers, Suppliers, and Partners for business continuity.
- Shareholders and Neighbors to ensure transparency and community safety.
- Regulators, Media, Law Enforcement, and Public Safety Authorities for compliance and safety.
- Key audiences during a disaster include:
Damage Assessment and Salvage Operations
- Damage Assessment:
- Qualified experts evaluate affected assets, which may include buildings, equipment, and data.
- Experts may be internal or external, such as structural engineers to inspect building safety postearthquake.
- Assessment informs insurance claims, a vital funding source for recovery.
- Salvage Operations:
- Identifies recoverable assets and facilitates repair or replacement to resume critical operations.
- Priority given to salvage tasks affecting essential machinery or inventory needed for business continuity.
- In some cases, damaged goods may be sold or repurposed if deemed unsalvageable for operational use.
Recovery Procedures
- Definition:
- Recovery procedures are essential steps to restart critical services that support business functions identified in the Business Impact Analysis (BIA) and Criticality Analysis (CA).
- Designed to work alongside resilience technologies added to IT systems to enhance recovery speed.
- Example: Acme Rocket Boots:
- For the critical order-entry function, Acme aims for recovery within 48 hours post-disaster.
- Investment in storage, backup, and replication technologies enables faster recovery.
- Procedure includes restoring the database from replicated cloud data, applying recent patches, and prepping recovery servers for production.
Communication Protocols in Disasters
- Essential Communication Structure:
- Call Tree System: Structured to notify key personnel efficiently, where each person has a few calls to make, expediting the notification process.
- Flexibility in the call tree ensures coverage despite potential unavailability of some personnel.
- Automated Outcalling Systems:
- Automated systems notify personnel with prerecorded messages, tracking who has been reached.
- Systems should be geographically remote from the disaster area for reliability, with internet access for disaster response coordination.
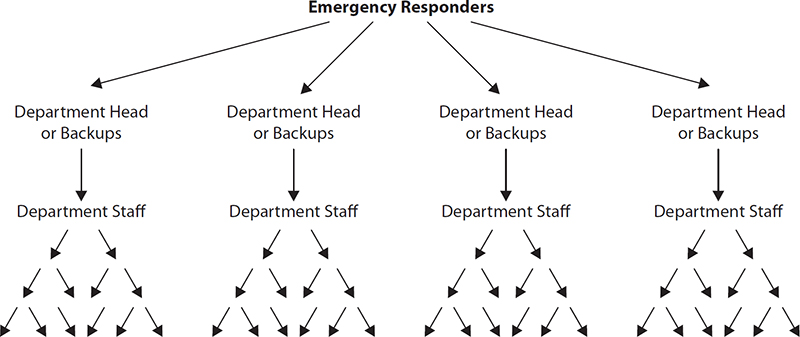
Figure 5-31 Example call tree structure
Importance of Testing Recovery and Continuity Plans
- Purpose of Testing:
- Tests ensure that Business Continuity (BC) and Disaster Recovery (DR) plans are functional and effective.
- Testing reveals flaws in plans, systems, and processes, improving response to actual disasters.
- Example issues found during testing: missing hardware components, procedural errors, or unclear instructions.
- Necessity of Testing:
- Without testing, the effectiveness of BC and DR plans is unknown, putting the organization at risk.
- Plans require regular testing due to ongoing technological and process changes.
Types of Recovery and Continuity Plan Tests
- Test Types:
- Document Review: Simple review of plan documents to ensure accuracy and clarity.
- Walkthrough: Team discusses steps without actual execution, identifying potential issues.
- Simulation: Simulated scenario to test response processes without disrupting operations.
- Parallel Test: Recovery systems are activated alongside primary systems to validate readiness.
- Cutover Test: Full shift from primary to recovery systems, testing complete failover.
- Preparation Steps for Tests:
- Participants: Identify relevant personnel across departments for full participation.
- Scheduling: Confirm availability to ensure involvement from all stakeholders.
- Facilities: Set up necessary space (e.g., conference room) and arrange for meals if needed.
- Scripting: Develop scenarios for simulations, parallel, and cutover tests to enrich value.
- Recordkeeping: Assign note-takers for organized test results and future reference.
- Contingency Planning: Especially for cutover tests, ensure a backup plan if issues arise.
Best Practices and Professional Resources for BCP & DRP
- Starting with Established Practices:
- There’s no need to create BCP (Business Continuity Planning) and DRP (Disaster Recovery Planning) from scratch.
- Professional standards and associations provide guidelines, certifications, and resources.
- Key Organizations:
- NIST: Develops high-quality federal standards; widely adopted by private sectors.
- BCI: Offers CBCI certification and provides events, journals, and resources.
- NFPA: Develops the NFPA 1620 standard for emergency response and structure protection.
- FEMA: Part of DHS, focuses on disaster relief and emergency planning resources.
- DRI International: Certifications include ABCP, CBCP, and MBCP.
- BCM Institute: Certifications for continuity, recovery, crisis, and communication experts.
Developing Effective Recovery Strategies
- Setting Recovery Targets:
- Management sets specific Recovery Point Objective (RPO) and Recovery Time Objective (RTO) targets for each system.
- BCP teams develop cost-effective strategies to meet these targets.
- The recovery strategy may need adjustments based on cost-benefit analysis with senior management.
- Site Recovery Options:
- Objective: Ensure critical applications can be recovered off-site if primary locations are damaged or destroyed.
- Types of Recovery Sites:
- Hot Site: High readiness, minimal downtime; applications are operational with up-to-date software and data replication.
- Warm Site: Moderate readiness; requires some system updates and data restoration from backups.
- Cold Site: Low readiness, mostly empty space or minimal setup; requires system setup and data loading post-disaster.
Developing Effective Recovery Strategies

Table 5-16 Relative Costs of Recovery Sites
RAID and Storage Solutions in Disaster Recovery
- RAID (Redundant Array of Independent Disks):
- Improves data reliability and system resilience by distributing data across multiple disks.
- RAID Configurations:
- RAID-0: Data striping for performance (no fault tolerance).
- RAID-1: Data mirroring for reliability.
- RAID-4/5: Data striping with parity for fault tolerance.
- RAID-6: Dual parity, can withstand two disk failures.
- Types of Storage Solutions:
- Storage Area Network (SAN): Dedicated storage connected via fiber optics; perceived as local storage by servers.
- Network Attached Storage (NAS): Connects to servers over a network, accessible via protocols like NFS/SMB.
Data Replication Methods for Enhanced Resilience
- Replication Overview:
- Replication: Copies data to a secondary location, enabling quick data recovery.
- Achieves near-real-time data availability in geographically distant sites.
- Replication Techniques:
- Storage-Level: Directly mirrors data on another storage system.
- OS-Level: Transmits file system updates across servers.
- Database-Level: Database management systems replicate transactions to a secondary server.
- Application-Level: Applications write data to multiple storage systems (less common).
- Types of Replication:
- Synchronous Replication: Ensures identical data across systems; incurs latency.
- Asynchronous Replication: No latency; potential lag between data in primary and backup.
Server Clusters and High Availability
- Definition: A server cluster is a collection of servers that function as a single resource to ensure high availability for critical applications, minimizing downtime.
- Cluster Configurations:
- Active-Active: All servers are active, sharing workload. Suitable for high-demand applications.
- Active-Passive: Standby servers are activated if an active server fails (failover). Ideal for balanced availability and cost.
- Geographic Clusters (Geo-Clusters):
- Servers located in separate regions, connected via a WAN.
- Provides resilience against regional disasters, offering greater continuity.
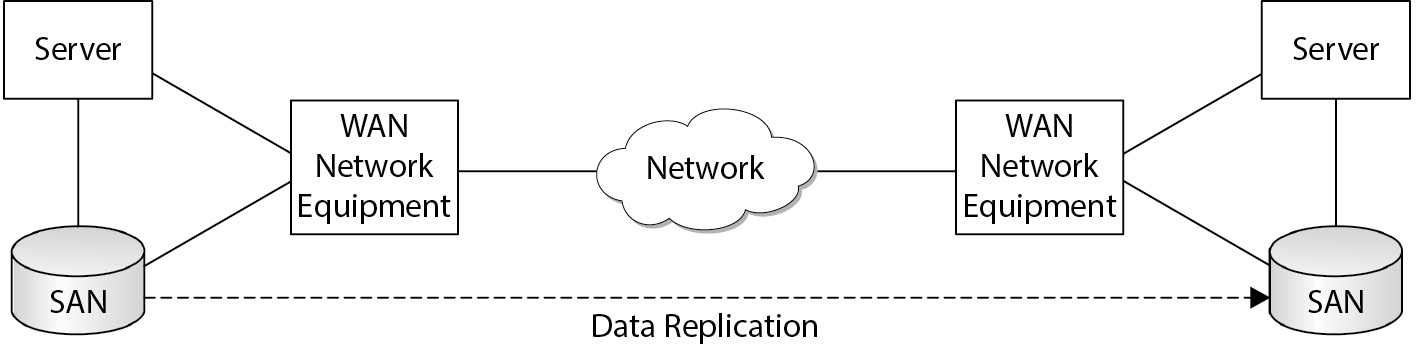
Figure 5-35 Geographic cluster with data replication
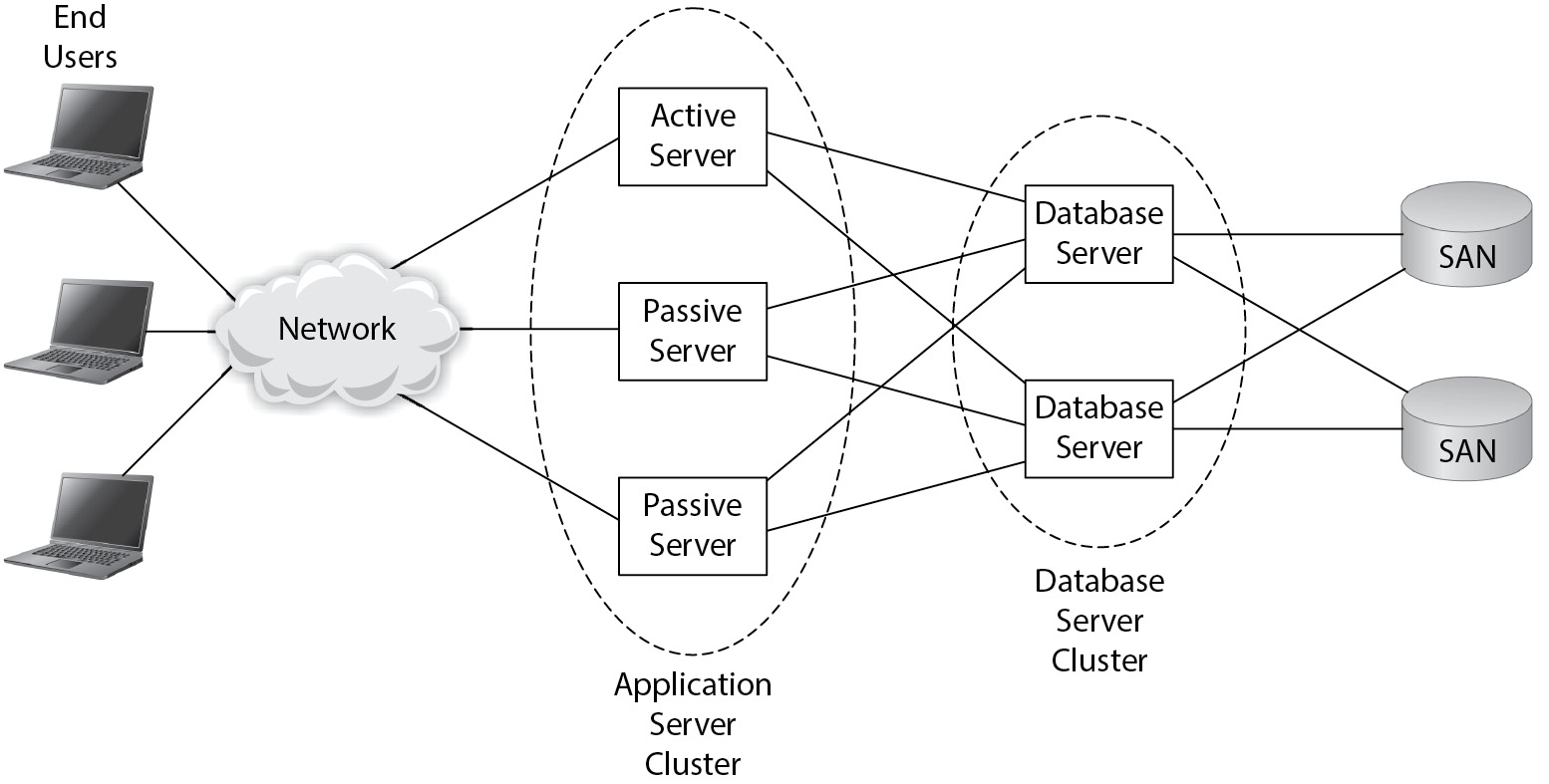
Figure 5-34 Application and database server clusters
Backup Schemes for Data Recovery
- Types of Backups:
- Full Backup: Comprehensive data snapshot; typically done weekly.
- Incremental Backup: Backs up only new or changed data since the last backup, saving time.
- Differential Backup: Backs up data changes since the last full backup, balancing time and recovery speed.
- Backup Strategy Considerations:
- Data Set Size: Larger data sets may use incremental/differential backups to optimize time.
- Data Criticality: Important data may require frequent backups.
- System Demand: Perform backups during low-demand times to minimize performance impact.
Backup Media Rotation Schemes
Objective: To balance cost, storage requirements, and retention needs in backup media management.
- Rotation Schemes:
- First In, First Out (FIFO): Uses the oldest media first. Suitable for low-criticality data with minimal retention needs but risks data loss if corruption is undetected.
- Grandfather-Father-Son (GFS): Most common scheme, retaining daily, weekly, and monthly backups, allowing for longer retention in a structured hierarchy.
- Towers of Hanoi: Complex rotation for efficient, extended retention. Follows a mathematical sequence, ensuring certain backups are retained longer without increasing media use.
Auditing IT Infrastructure and Operations
- Auditing Focus Areas:
- Hardware: Standards, maintenance, capacity, change, and configuration management.
- Operating Systems: Compliance with standards, change, and configuration management, maintenance, and security practices.
- Critical Activities:
- Configuration Management: Centralized tracking of system configurations ensures consistency.
- Security Management: Auditing for “hardened” configurations and updated patches to minimize risks.
Auditing File Systems and Database Management Systems (DBMS)
- File System Auditing Ensure file systems with business information are configured for optimal storage and access control.
- Key Areas:
- Capacity Management: File systems must have adequate space for current needs and future growth. Capacity tools and records should be reviewed.
- Access Control: Access should be restricted to authorized personnel with valid business needs.Access requests and permissions should be examined for alignment.
- DBMS auditing requires in-depth scrutiny due to the intricacy of database configurations and change management.
- Key Areas:
- Configuration Management: Ensures consistent DBMS setup across systems through centralized control.
- Change Management: Verifies systematic and approved changes to databases.
Auditing Network Infrastructure
- Objective: Ensure the network infrastructure supports business objectives and is robust against potential disruptions.
- Key Areas:
- Enterprise & Network Architecture: Review detailed schematics, topology, and standards to ensure proper design.
- Security Architecture: Check security measures, including firewalls, IDS/IPS, and access controls.
- Change & Configuration Management: Ensure network device changes follow protocols and are documented.
- Capacity & Access Management: Evaluate capacity monitoring and restrict administrative access to authorized personnel only
Auditing Network Operating Controls
- Network Operations: Examine if the network operates efficiently and securely.
- Key Areas:
- Operating Procedures: Check for documented procedures on login, startup, shutdown, upgrades, and configuration changes.
- Restart Procedures: Ensure there are tested procedures for full or partial network restarts in case of failure.
- Troubleshooting Procedures: Review network-specific troubleshooting guidelines to help quickly resolve issues.
- Security Controls: Evaluate controls over administrator access, logging, and protection of configuration and audit logs.
- Change Management: Verify all changes to network components adhere to a formal life cycle.
Question and Answers
- A web application is displaying information incorrectly and many users have contacted the IT service desk. This matter should be considered a(n)
- A. Incident
- B. Problem
- C. Bug
- D. Outage
- An IT organization is experiencing many cases of unexpected downtime that are caused by unauthorized changes to application code and operating system configuration. Which process should the IT organization implement to reduce downtime?
- A. Configuration management
- B. Incident management
- C. Change management
- D. Problem management
- A database administrator has been asked to configure a database management system so that it records all changes made by users. What should the database administrator implement?
- A. Audit logging
- B. Triggers
- C. Stored procedures
- D. Journaling
- An IS auditor is examining a wireless (Wi-Fi) network and has determined that the network uses WEP encryption. What action should the auditor take?
- A. Recommend that encryption be changed to WPA.
- B. Recommend that encryption be changed to EAP.
- C. Request documentation for the key management process.
- D. Request documentation for the authentication process.
- An organization has established a recovery point objective of 14 days for its most critical business applications. Which recovery strategy would be the best choice?
- A. Mobile site
- B. Warm site
- C. Hot site
- D. Cold site