Networked Applications
Other than simple end-user tools on a business workstation, business applications are rarely installed and used within the context of an individual computer. Instead, many applications are centrally installed and used by many people who are often in many locations. Data networks facilitate the communications between central servers and business workstations. The applications discussed in the following sections are client-server, web-based, and middleware.
Client-Server
Client-server applications are a prior-generation technology used to build high-performance business applications. They consist of one or more central application servers, database servers, and business workstations. The central application servers contain some business logic—primarily the instructions to receive and respond to requests sent from workstations. The remainder of the business logic will reside on each business workstation; primarily this is the logic used to display and process forms and reports for the user.
When a user is using a client-server application, he or she is typically selecting functions to input, view, or change information. When information is input, application logic on the business workstation will request, analyze, and accept the information and then transmit it to the central application server for further processing and storage. When viewing information, a user will typically select a viewing function with, perhaps, criteria specifying which information they want to view. Business logic on the workstation will validate this information and then send a request to the central application server, which in turn will respond with information that is then sent back to the workstation and transformed for easy viewing.
The promise of client-server applications was improved performance by removing all application display logic from the central computer and placing that logic on each individual workstation. This scheme succeeded in principle but failed in practice for two principal reasons:
- Network performance
Client-server applications often overburdened the organization’s data network, and application performance failed when many people were using it at once. A typical example is a database query issued by a workstation that results in thousands of records being returned to the workstation over the network. - Workstation software updates
Keeping the central application software and the software modules on each workstation in sync proved to be problematic. Often, updates required that all workstations be upgraded at the same time. Invariably, some workstations are down or otherwise unavailable for updates (powered down by end users or taken home if they are laptop computers), potentially resulting in application malfunctions for those users.
Organizations that did implement full-scale client-server applications were often dissatisfied with the results. And at nearly the same time, the World Wide Web was invented and soon proved to be a promising, simpler alternative.
Client-server application design has enjoyed a revival with the advent of smartphone and tablet applications, or apps, which are often designed as client-server.
Web-Based Applications
With client-server applications declining in favor, web-based applications were the only way forward. The primary characteristics of web-based applications that make them highly favorable include
- Centralized business logic
All business logic resides on one or more centralized servers. There are no longer issues related to pushing software updates to workstations since they run web browsers that rarely require updating. - Lightweight and universal display logic
Display logic, such as forms, lists, and other application controls, is easily written in HTML, a simple markup language that displays well on workstations without any application logic on the workstation. - Lightweight network requirements
Unlike client-server applications that would often send large amounts of data from the centralized server to the workstation, web applications send mainly display data to workstations. - Workstations requiring few, if any, updates
Workstations require only browser software. Updates to applications themselves are entirely server-based. - Fewer compatibility issues
Instead of requiring a narrow choice of workstations, web-based applications can run on nearly every kind of workstation, including Unix, Windows, macOS, Chrome OS, or Linux.
Middleware
Middleware is a component used in some client-server or web-based application environments to control the processing of communications or transactions. Middleware manages the interaction between major components in larger application environments.
Some of the common types of middleware include
- Transaction processing (TP) monitors
A TP monitor manages transactions between application servers and database servers to ensure the integrity of business transactions among a collection of database servers. - RPC gateways
These systems facilitate communications through the suite of RPC protocols between various components of an application environment. - Object request broker (ORB) gateways
An ORB gateway facilitates the execution of transactions across complex, multiserver application environments that use CORBA (Common Object Request Broker Architecture) or Microsoft COM/DCOM technologies. - Message servers
These systems store and forward transactions between systems and ensure the eventual delivery of transactions to the right systems.
Middleware is typically used in a large, complex application environment, particularly when there are multiple technologies (operating systems, databases, and languages) in use. Middleware can be thought of as glue that helps the application environment operate more smoothly.
Business Resilience
In the context of information systems, business resilience is concerned with the resilience of IT systems and business applications that support critical business processes, to ensure the ongoing viability of the organization as well as survival in the event of a major disaster. Given the phenomenon of digital transformation (DX), which represents an increasing dependency of business processes on information technology, ensuring the resilience of IT systems is all the more important. The two primary activities within business resilience are business continuity planning and disaster recovery planning.
Business Continuity Planning
Business continuity planning (BCP) is a business activity that is undertaken to reduce risks related to the onset of disasters and other disruptive events. BCP activities identify the most critical activities and assets in an organization. They identify risks and mitigate those risks through changes or enhancements in technology or business processes so that the impact of disasters is reduced and the time to recovery is lessened. The primary objective of BCP is to improve the chances that the organization will survive a disaster without incurring costly or even fatal damage to its most critical activities.
The activities of BCP development scale for any size organization. BCP has the unfortunate reputation of existing only in the stratospheric, thin air of the largest and wealthiest organizations. This misunderstanding hurts the majority of organizations that are too timid to begin any kind of BCP effort at all because they believe that these activities are too costly and disruptive. The fact is that any size organization, from a one-person home office to a multinational conglomerate, can successfully undertake BCP projects that will bring about immediate benefits as well as take some of the sting out of disruptive events that do occur.
Organizations can benefit from BCP projects, even if a disaster never occurs. The steps in the BCP development process usually bring immediate benefit in the form of process and technology improvements that increase the resilience, integrity, and efficiency of those processes and systems.
EXAM TIP
Business continuity planning is closely related to disaster recovery planning—both are concerned with the recovery of business operations after a disaster.
Disasters
I always tried to turn every disaster into an opportunity.
*–*John D. Rockefeller
In a business context, disasters are unexpected and unplanned events that result in the disruption of business operations. A disaster could be a regional event spread over a wide geographic area, or it could occur within the confines of a single room. The impact of a disaster will also vary, from a complete interruption of all company operations to a mere slowdown. (The question invariably comes up: when is a disaster a disaster? This is somewhat subjective, like asking, “When is a person sick?” Is it when he or she is too ill to report to work, or if he or she just has a sniffle and a scratchy throat? I’ll discuss disaster declaration later in this chapter.)
Types of Disasters
BCP professionals broadly classify disasters as natural or human-made, although the origin of a disaster does not figure very much into how we respond to it. Let’s examine the types of disasters.
Natural Disasters
Natural disasters are phenomena that occur in the natural world with little or no assistance from mankind. They are a result of the natural processes that occur in, on, and above the earth.
Examples of natural disasters include
- Earthquakes
Sudden movements of the earth with the capacity to damage buildings, houses, roads, bridges, and dams; to precipitate landslides and avalanches; and to induce flooding and other secondary events. - Volcanoes
Eruptions of magma, pyroclastic flows, steam, ash, and flying rocks that can cause significant damage over wide geographic regions. Some volcanoes, such as Kilauea in Hawaii, produce a nearly continuous and predictable outpouring of lava in a limited area, whereas others, such as the Mount St. Helens eruption in 1980 in Washington state, caused an ash fall over thousands of square miles that brought many metropolitan areas to a standstill for days and also blocked rivers and damaged roads. Figure 5-23 shows a volcanic eruption as seen from space.

Figure 5-23 Mount Etna volcano in Sicily
- Landslides
Sudden downhill movements of earth, usually down steep slopes, can bury buildings, houses, roads, and public utilities and cause secondary (although still disastrous) effects such as the rerouting of rivers. - Avalanches
Sudden downward flows of snow, rocks, and debris on a mountainside can damage buildings, houses, roads, and utilities, resulting in direct or indirect damage affecting businesses. A slab avalanche consists of the movement of a large, stiff layer of compacted snow. A loose snow avalanche occurs when the accumulated snowpack exceeds its shear strength. A power snow avalanche is the largest type and can travel in excess of 200 mph and exceed 10 million tons of material. - Wildfires
Fires in forests, chaparral, and grasslands are part of the natural order. However, fires can also damage power lines, buildings, equipment, homes, and entire communities, and cause injury and death. - Tropical cyclones
The largest and most violent storms are known in various parts of the world as hurricanes, typhoons, tropical cyclones, tropical storms, and cyclones. Tropical cyclones consist of strong winds that can reach 190 mph, heavy rains, and storm surge that can raise the level of the ocean by as much as 20 feet, all of which can result in widespread coastal flooding and damage to buildings, houses, roads, and utilities and significant loss of life. - Tornadoes
These violent rotating columns of air can cause catastrophic damage to buildings, houses, roads, and utilities when they reach the ground. Most tornadoes can have wind speeds from 40 to 110 mph and travel along the ground for a few miles. Some tornadoes can exceed 300 mph and travel for dozens of miles. - Windstorms
While generally less intense than hurricanes and tornadoes, windstorms can nonetheless cause widespread damage, including damage to buildings, roads, and utilities. Widespread electric power outages are common, as windstorms can uproot trees that can fall into overhead power lines. - Lightning
Atmospheric discharges of electricity occur during thunderstorms, but also during dust storms and volcanic eruptions. Lightning can start fires and also damage buildings and power transmission systems, causing power outages. - Ice storms
Ice storms occur when rain falls through a layer of colder air, causing raindrops to freeze onto whatever surface they strike. They can cause widespread power outages when ice forms on power lines and the resulting weight causes those power lines to collapse. A notable example is the Great Ice Storm of 1998 in eastern Canada, which resulted in millions being without power for as long as two weeks and in the virtual immobilization of the cities of Montreal and Ottawa. - Hail
This form of precipitation consists of ice chunks ranging from 5mm to 150mm in diameter. An example of a damaging hailstorm is the April 1999 storm in Sydney, Australia, where hailstones up to 9.5cm in diameter damaged 40,000 vehicles, 20,000 properties, and 25 airplanes, and caused one direct fatality. The storm caused $1.5 billion in damage. - Flooding
Standing or moving water spills out of its banks and flows into and through buildings and causes significant damage to roads, buildings, and utilities. Flooding can be a result of locally heavy rains, heavy snowmelt, a dam or levee break, tropical cyclone storm surge, or an avalanche or landslide that displaces lake or river water. - Tsunamis
This series of waves usually results from the sudden vertical displacement of a lake bed or ocean floor, but a tsunami can also be caused by landslides, asteroids, or explosions. A tsunami wave can be barely noticeable in open, deep water, but as it approaches a shoreline, the wave can grow to a height of 50 feet or more. Recent notable examples are the 2004 Indian Ocean tsunami and the 2011 Japan tsunami. Coastline damage from the Japan tsunami is shown in Figure 5-24.

Figure 5-24 Damage to structures caused by the 2011 Japan tsunami
- Pandemic
The spread of infectious disease can occur over a wide geographic region, even worldwide. Pandemics have regularly occurred throughout history and are likely to continue occurring, despite advances in sanitation and immunology. A pandemic is the rapid spread of any type of disease, including typhoid, tuberculosis, bubonic plague, or influenza. Pandemics in the 20th century include the 1918–1920 Spanish flu, the 1956–1958 Asian flu, the 1968–1969 Hong Kong “swine” flu, and the 2009–2010 swine flu pandemics. Figure 5-25 shows an auditorium that was converted into a hospital during the 1918–1920 pandemic.
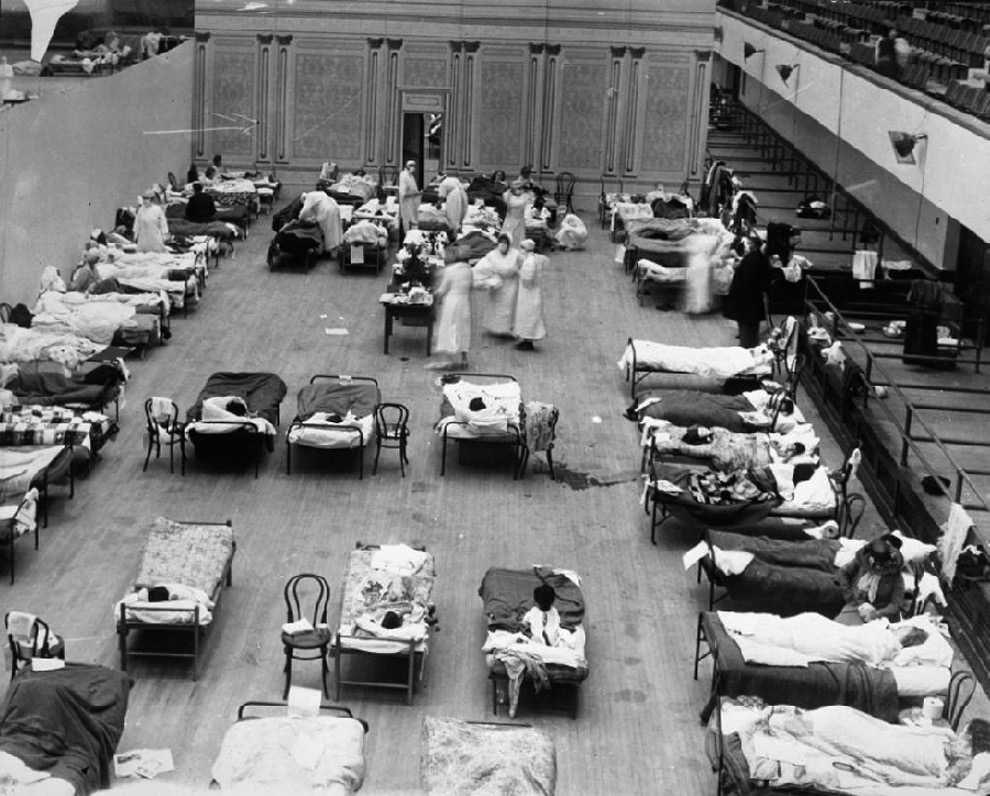
Figure 5-25 An auditorium was used as a temporary hospital during the 1918 flu pandemic.
Extraterrestrial impacts
This category includes meteorites and other objects that may fall from the sky from way, way up. Sure, these events are extremely rare, and most organizations don’t even include these events in their risk analysis, but I’ve included it here for the sake of rounding out the types of natural events.
Human-Made Disasters
Human-made disasters are events that are directly or indirectly caused by human activity through action or inaction. The results of human-made disasters are similar to natural disasters: localized or widespread damage to businesses that results in potentially lengthy interruptions in operations.
Examples of human-made disasters include
- Civil disturbances
These can include protests, demonstrations, riots, strikes, work slowdowns and stoppages, looting, and resulting actions such as curfews, evacuations, or lockdowns. - Utility outages
Failures in electric, natural gas, district heating, water, communications, and other utilities can be caused by equipment failures, sabotage, or natural events such as landslides or flooding. - Service outages
Failures in IT equipment, software programs, and online services can be caused by hardware failures, software bugs, or misconfiguration. - Materials shortages
Interruptions in the supply of food, fuel, supplies, and materials can have a ripple effect on businesses and the services that support them. Readers who are old enough to remember the petroleum shortages of the mid-1970s know what this is all about; Figure 5-26 shows a line at a gas station during a 1970s-era gasoline shortage. Shortages can result in spikes in the price of commodities, which is almost as damaging as not having any supply at all.

Figure 5-26 Citizens wait in long lines to buy fuel during a gas shortage.
- Fires
As contrasted to wildfires, human-made fires originate in or involve homes, buildings, equipment, and materials. - Hazardous materials spillsMany created or refined substances can be dangerous if they escape their confines. Examples include petroleum substances, gases, pesticides and herbicides, medical substances, and radioactive substances.
- Transportation accidents
This broad category includes plane crashes, railroad derailments, bridge collapses, and the like. - Terrorism and war
Whether they are actions of a nation, nation-state, or group, terrorism and war can have devastating but usually localized effects in cities and regions. Often, terrorism and war precipitate secondary effects such as materials shortages and utility outages. - Security events
The actions of a lone hacker or a team of organized cyber-criminals can bring down one system, one network, or many networks, which could result in widespread interruption in services. The hackers’ activities can directly result in an outage, or an organization can voluntarily (although reluctantly) shut down an affected service or network to contain the incident.
NOTE
It is important to remember that real disasters are usually complex events that involve more than just one type of damaging event. For instance, an earthquake directly damages buildings and equipment, but it can also cause fires and utility outages. A hurricane also brings flooding, utility outages, and sometimes even hazardous materials events and civil disturbances such as looting.
- How Disasters Affect Organizations
Disasters have a wide variety of effects on an organization. Many disasters have direct effects, but sometimes it is the secondary effects of a disaster event that are most significant from the perspective of ongoing business operations.
A risk analysis is a part of the BCP process (discussed in the next section) that will identify the ways in which disasters are likely to affect a particular organization. During the risk analysis, the primary, secondary, and downstream effects of likely disaster scenarios need to be identified and considered. Whoever is performing this risk analysis will need to have a broad understanding of the interdependencies of business processes and IT systems, as well as the ways in which a disaster will affect ongoing business operations. Similarly, personnel who are developing contingency and recovery plans also need to be familiar with these effects so that those plans will adequately serve the organization’s needs.
Disasters, by our definition, interrupt business operations in some measurable way. An event that has the appearance of a disaster may occur, but if it doesn’t affect a particular organization, then we would say that no disaster occurred, at least for that particular organization.
It would be shortsighted to say that a disaster affects only operations. Rather, it is appropriate to understand the longer term effects that a disaster has on the organization’s image, brand, reputation, and ongoing financial viability. The factors affecting image, brand, and reputation have as much to do with how the organization communicates to its customers, suppliers, and shareholders as with how the organization actually handles a disaster in progress.
Some of the ways that a disaster affects an organization’s operations include
- Direct damage
Events such as earthquakes, floods, and fires directly damage an organization’s buildings, equipment, or records. The damage may be severe enough that no salvageable items remain, or it may be less severe, where some equipment and buildings may be salvageable or repairable. - Utility interruption
Even if an organization’s buildings and equipment are undamaged, a disaster may affect utilities such as power, natural gas, or water, which can incapacitate some or all business operations. Significant delays in refuse collection can result in unsanitary conditions. - Transportation
A disaster may damage or render transportation systems such as roads, railroads, shipping, or air transport unusable for a period. Damaged transportation systems will interrupt supply lines and personnel. - Services and supplier shortageEven if a disaster does not have a direct effect on an organization, critical suppliers affected by a disaster can have an undesirable effect on business operations. For instance, a regional baker that cannot produce and ship bread to its corporate customers will soon result in sandwich shops and restaurants without a critical resource.
- Staff availability
A community-wide or regional disaster that affects businesses is also likely to affect homes and families. Depending upon the nature of a disaster, employees will place a higher priority on the safety and comfort of family members. Also, workers may not be able or willing to travel to work if transportation systems are affected or if there is a significant materials shortage. Employees may also be unwilling to travel to work if they fear for their personal safety or that of their families. - Customer availability
Various types of disasters may force or dissuade customers from traveling to business locations to conduct business. Many of the factors that keep employees away may also keep customers away.
CAUTION
The kinds of secondary and tertiary effects that a disaster has on a particular organization depend entirely upon its unique set of circumstances that constitute its specific critical needs. A risk analysis should be performed to identify these specific factors.
The Business Continuity Planning Process
The proper way to plan for disaster preparedness is first to know what kinds of disasters are likely and their possible effects on the organization. That is, plan first, act later.
The business continuity planning process is a life cycle process. In other words, business continuity planning (and disaster recovery planning) is not a one-time event or activity. It’s a set of activities that results in the ongoing preparedness for disaster that continually adapts to changing business conditions and that continually improves.
The elements of the BCP process life cycle are
- Develop BCP policy.
- Conduct business impact analysis (BIA).
- Perform criticality analysis.
- Establish recovery targets.
- Develop recovery and continuity strategies and plans.
- Test recovery and continuity plans and procedures.
- Train personnel.
- Maintain strategies, plans, and procedures through periodic reviews and updates.
The BCP life cycle is shown in Figure 5-27. The details of this life cycle are described in detail in this chapter.
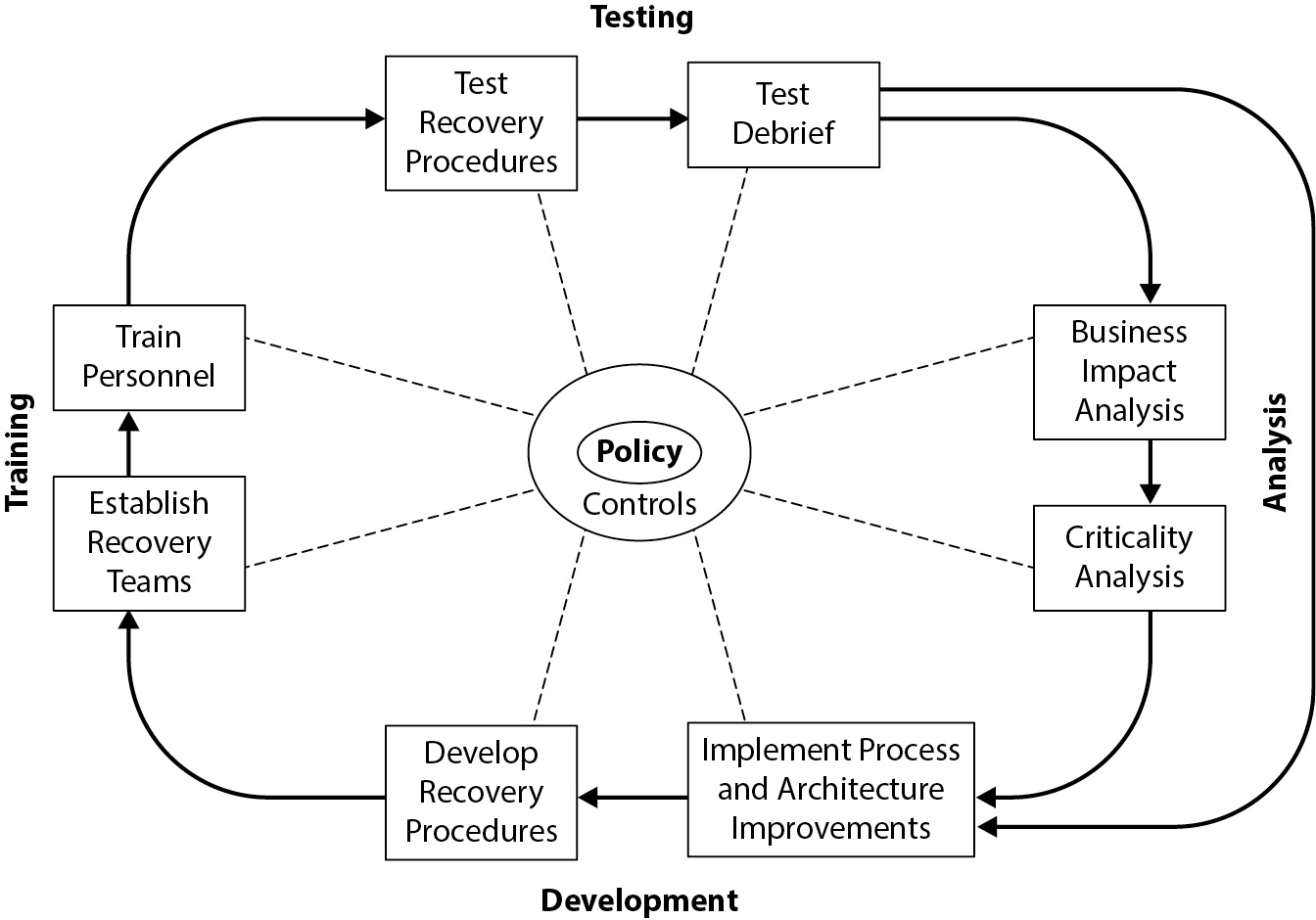
Figure 5-27 The BCP process life cycle
BCP Policy
A formal BCP effort must, like any strategic activity, flow from the existence of a formal policy and be included in the overall governance model that is the topic of this chapter. BCP should be an integral part of the IT control framework; it should not lie outside of it. Therefore, BCP policy should include or cite specific controls that ensure that key activities in the BCP life cycle are performed appropriately.
BCP policy should also define the scope of the BCP strategy. This means that the specific business processes (or departments or divisions within an organization) that are included in the BCP effort must be defined. Sometimes the scope will include a geographic boundary. In larger organizations, it is possible to “bite off more than you can chew” and define too large a scope for a BCP project, so limiting scope to a smaller, more manageable portion of the organization can be a good approach.
BCP and COBIT Controls
The specific COBIT controls that are involved with BCP are contained within DSS04—Ensure continuous service. DSS04 has eight specific controls that constitute the entire BCP life cycle:
- Define the business continuity policy, objectives and scope.
- Maintain a continuity strategy.
- Develop and implement a business continuity response.
- Exercise, test and review the BCP.
- Review, maintain and improve the continuity plan.
- Conduct continuity plan training.
- Manage backup arrangements.
- Conduct post-resumption review.
These controls are discussed in this chapter and also in COBIT.
Business Impact Analysis
The objective of the business impact analysis (BIA) is to identify the impact that different scenarios will have on ongoing business operations. The BIA is one of several steps of critical, detailed analysis that must be carried out before the development of continuity or recovery plans and procedures.
Inventory Key Processes and Systems
The first step in a BIA is the collection of key business processes and IT systems. Within the overall scope of the BCP project, the objective here is to establish a detailed list of all identifiable processes and systems. The usual approach is the development of a questionnaire or intake form that would be circulated to key personnel in end-user departments and also within IT. A sample intake form is shown in Figure 5-28.
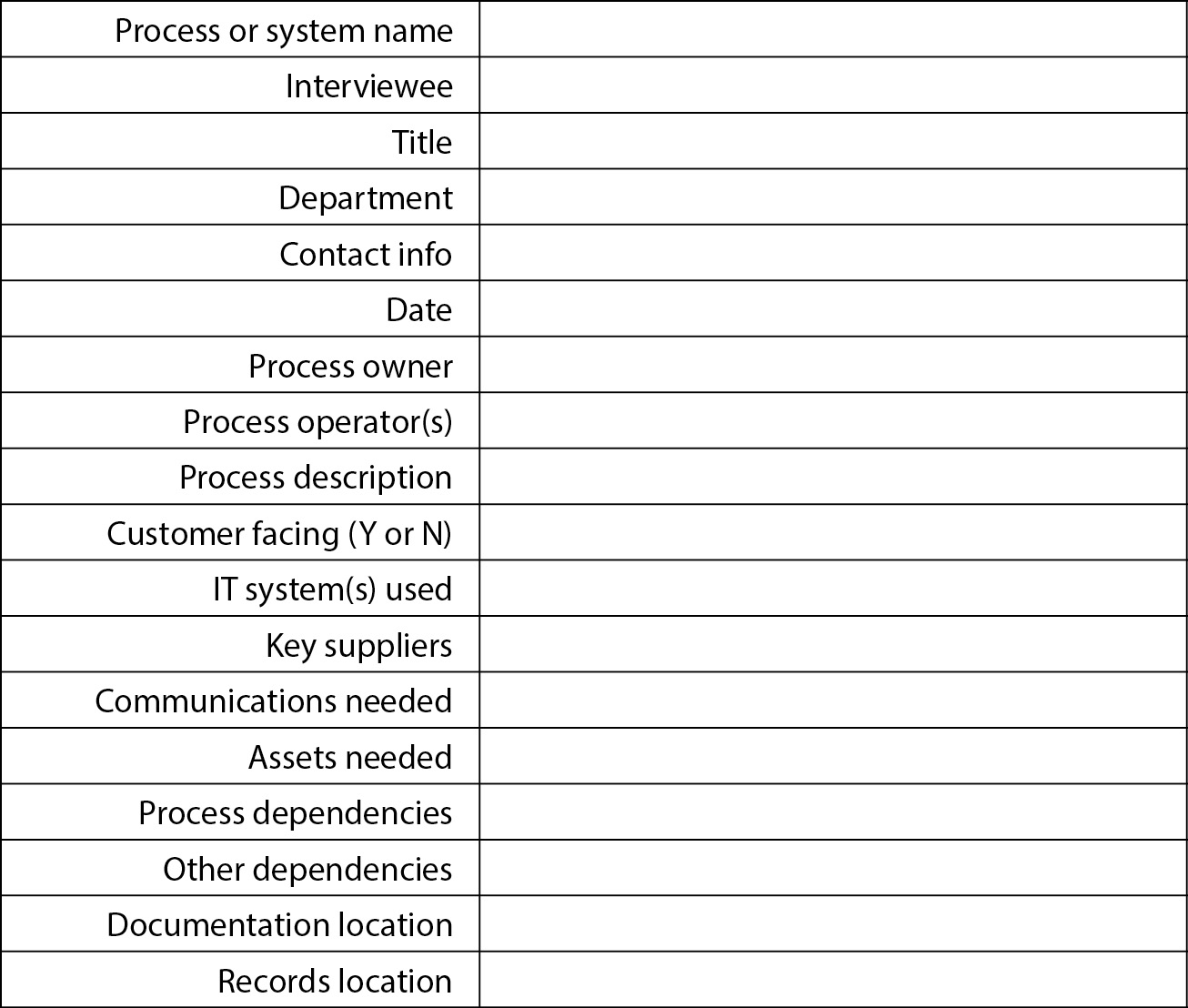
Figure 5-28 BIA sample intake form for gathering data about key processes
Typically, the information that is gathered on intake forms is transferred to a multi-columned spreadsheet, where information on all of the organization’s in-scope processes can be viewed together. This will become even more useful in subsequent phases of the BCP project, such as the criticality analysis.
TIP
Use of an intake form is not the only accepted approach when gathering information about critical processes and systems. It’s also acceptable to conduct one-on-one interviews or group interviews with key users and IT personnel to identify critical processes and systems. I recommend the use of an intake form (whether paper-based or electronic), even if the interviewer uses it only as a framework for note-taking.
Planning Precedes Action
IT personnel are often eager to get to the fun and meaty parts of a project. Developers are anxious to begin coding before design; system administrators are eager to build systems before they are scoped and designed; and BCP personnel fervently desire to begin designing more robust system architectures and to tinker with replication and backup capabilities before key facts are known. In the case of business continuity and disaster recovery planning, completion of the BIA and other analyses is critical, as the analyses help to define the systems and processes most needed before getting to the fun part.
Statements of Impact
When processes and systems are being inventoried and cataloged, it is also vitally important to obtain one or more statements of impact for each process and system. A statement of impact is a qualitative or quantitative description of the impact on the business if the process or system were incapacitated for a time.
For IT systems, you might capture the number of users and the names of departments or functions that are affected by the unavailability of a specific IT system. Include the geography of affected users and functions if that is appropriate. Here are some example statements of impact for IT systems:
- Three thousand customer support users in France and Italy will be unable to access customer records.
- All users in North America will be unable to read or send e-mail. Statements of impact for business processes may cite the business functions that would be affected. Here are some examples:
- Accounts payable and accounts receivable functions will be unable to process.
- Legal department will be unable to access contracts and addendums.
Statements of impact for revenue-generating and revenue-supporting business functions could quantify financial impact per unit of time (be sure to use the same units of time for all functions so that they can be easily compared with one another). Here are some examples:
- Inability to place orders for appliances will cost at the rate of $12,000 per hour.
- Delays in payments will cost $45,000 per day in interest charges. As statements of impact are gathered, it may make sense to create several columns in the main worksheet so that like units (names of functions, numbers of users, financial figures) can be sorted and ranked later on.
A complete BIA will have the following information about each process and system:
- Name of the system or process
- Who is responsible for it
- A description of its function
- Dependencies on systems
- Dependencies on suppliers
- Dependencies on key employees
- Quantified statements of impact in terms of revenue, users affected, and/or functions impacted
You’re almost home.
Criticality Analysis When all of the BIA information has been collected and charted, the criticality analysis (CA) can be performed.
The criticality analysis is a study of each system and process, a consideration of the impact on the organization if it is incapacitated, the likelihood of incapacitation, and the estimated cost of mitigating the risk or impact of incapacitation. In other words, it’s a somewhat special type of risk analysis that focuses on key processes and systems.
The criticality analysis needs to include, or reference, a threat analysis. A threat analysis is a risk analysis that identifies every threat that has a reasonable probability of occurrence, plus one or more mitigating controls or compensating controls, and new probabilities of occurrence with those mitigating/compensating controls in place. In case you’re having a little trouble imagining what this looks like (I’m writing the book and I’m having trouble seeing this!), take a look at Table 5-12, which is a lightweight example of what I’m talking about.
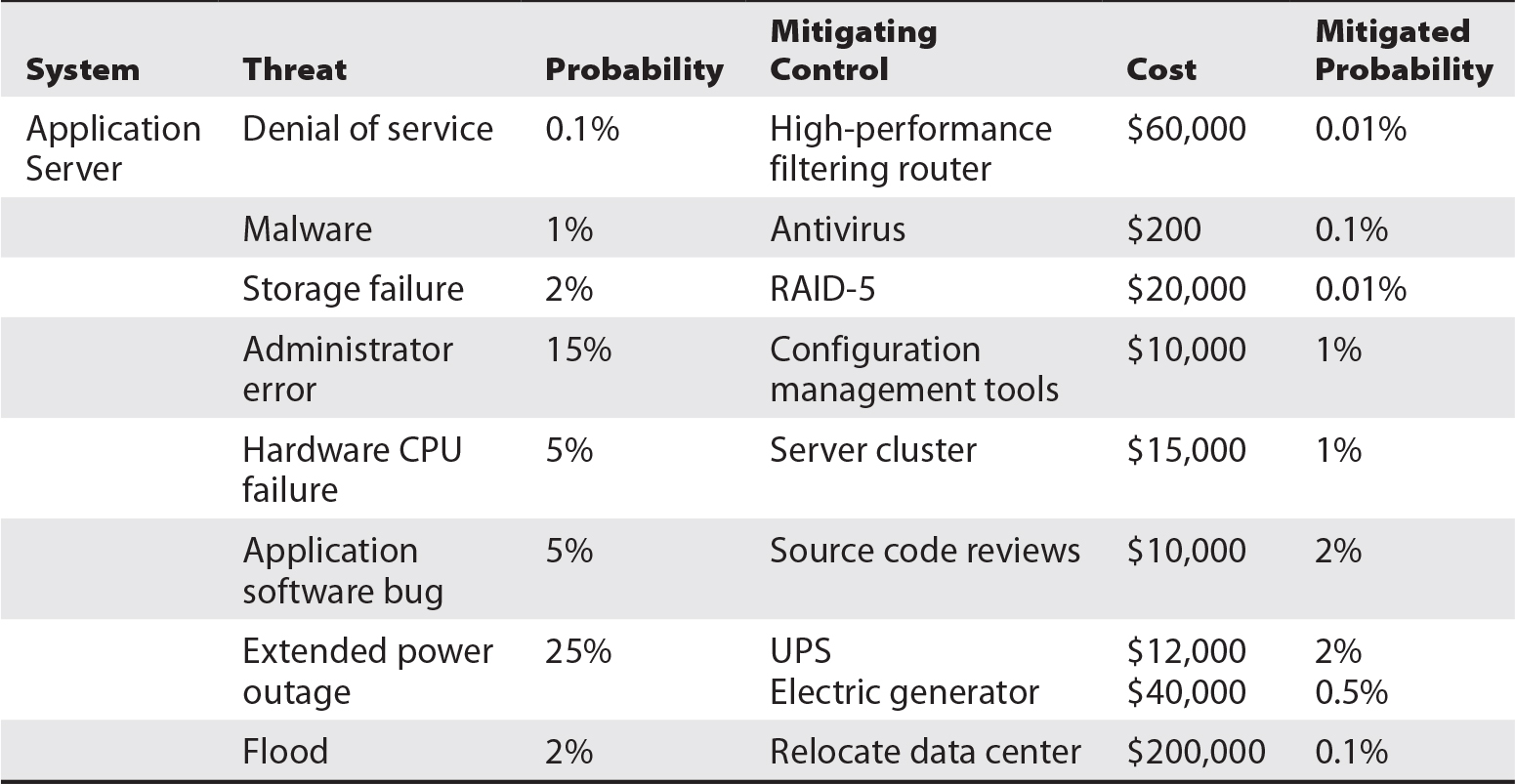
Table 5-12 Example Threat Analysis Identifies Threats and Controls for Critical Systems and Processes
In the preceding threat analysis, notice the following:
- Multiple threats are listed for a single asset. In the table, I mentioned just eight threats. For all the threats but one, I listed only a single mitigating control. For the extended power outage threat, I listed two mitigating controls.
- Cost of downtime wasn’t listed. For systems or processes where you have a cost per unit of time for downtime, you’ll need to include it here, along with some calculations to show the payback for each control.
- Some mitigating controls can benefit more than one system. That may not have been obvious in this example, but in the case of a UPS (uninterruptible power supply) and electric generator, many systems can benefit, so the cost for these mitigating controls can be allocated across many systems, thereby lowering the cost for each system. Another example is a high-availability storage area network (SAN) located in two different geographic areas; while initially expensive, many applications can use the SAN for storage, and all will benefit from replication to the counterpart storage system.
- Threat probabilities are arbitrary. In Table 5-12, the probabilities were for a single occurrence in an entire year, so, for example, 5 percent means the threat will be realized once every 20 years.
- The length of outage was not included. You may need to include this also, particularly if you are quantifying downtime per hour or other unit of time.
It is probably becoming obvious that a threat analysis, and the corresponding criticality analysis, can get complicated. The rule here should be this: the complexity of the threat and criticality analyses should be proportional to the value of the assets (or revenue, or both). For example, in a company where application downtime is measured in thousands of dollars per minute, it’s probably worth taking a few weeks or even months to work out all of the likely scenarios and a variety of mitigating controls, and to work out which ones are the most cost-effective. On the other hand, for a system or business process where the impact of an outage is far less costly, a good deal less time might be spent on the supporting threat and criticality analysis.
EXAM TIP
Test-takers should ensure that any question dealing with BIA and CA places the business impact analysis first. Without this analysis, criticality analysis is impossible to evaluate in terms of likelihood or cost-effectiveness in mitigation strategies. The BIA identifies strategic resources and provides a value to their recovery and operation, which is, in turn, consumed in the criticality analysis phase. If presented with a question identifying BCP at a particular stage, make sure that any answers you select facilitate the BIA and then the CA before moving on toward objectives and strategies.
Determine Maximum Tolerable Downtime
The next step for each critical process is the establishment of a metric called maximum tolerable downtime (MTD). This is a theoretical time interval, measured from the onset of a disaster, after which the organization’s very survival is at risk. Establishing MTD for each critical process is an important step that aids in the establishment of key recovery targets, discussed in the next section.
Establishing Key Recovery Targets
When the cost or impact of downtime has been established and the cost and benefit of mitigating controls has been considered, some key targets can be established for each critical process. These objectives determine how quickly key systems and processes should be made available after the onset of a disaster and the maximum tolerable data loss that results from the disaster. The two key recovery targets are
- Recovery time objective (RTO)
This refers to the maximum period that elapses from the onset of a disaster until the resumption of service. - Recovery point objective (RPO)
This refers to the maximum data loss from the onset of a disaster.
Once these target objectives are known, the disaster recovery (DR) team can begin to build system recovery capabilities and procedures that will help the organization economically realize these targets. This is discussed in detail later in this chapter.
Developing Continuity Plans
In the previous section, I discussed the notion of establishing recovery targets and the development of architectures, processes, and procedures. The processes and procedures are related to the normal operation of those new technologies as they will be operated in normal day-to-day operations. When those processes and procedures have been completed, the disaster recovery plans and procedures (actions that will take place during and immediately after a disaster) can be developed.
For example, an organization has established RPO and RTO targets for its critical applications. These targets necessitated the development of server clusters and storage area networks with replication. While implementing those new technologies, the organization developed the operations processes and procedures in support of those new technologies that would be carried out every day during normal business operations. As a separate activity, the organization would then develop the procedures to be performed when a disaster strikes the primary operations center for those applications; those procedures would include all of the steps that must be taken so that the applications can continue operating in an alternate location or in the public cloud.
The procedures for operating critical applications during a disaster are a small part of the entire body of procedures that must be developed. Several other sets of procedures must also be developed, including
- Personnel safety procedures
- Disaster declaration procedures
- Responsibilities
- Contact information
- Recovery procedures
- Continuing operations
- Restoration procedures
All of these are required so that an organization will be adequately prepared in the event a disaster occurs.
Personnel Safety Procedures
When a disaster strikes, measures to ensure the safety of personnel are a top priority and need to be taken immediately. If the disaster has occurred or is about to occur to a building, personnel may need to be evacuated as soon as possible. Arguably, however, in some situations, evacuation is exactly the wrong thing to do; for example, if a hurricane or tornado is bearing down on a facility, the building itself may be the best shelter for personnel, even if it incurs some damage. The point here is that personnel safety procedures need to be carefully developed, and possibly more than one set of procedures will be needed, depending on the event.
TIP
The highest priority in any disaster or emergency situation is the safety of human life.
Personnel safety procedures need to take many factors into account, including
- Ensuring that all personnel are familiar with evacuation and sheltering procedures
- Ensuring that visitors know how to evacuate the premises and the location of sheltering areas
- Posting signs and placards that indicate emergency evacuation routes and gathering areas outside of the building
- Locating emergency lighting to aid in evacuation or sheltering in place
- Providing fire extinguishment equipment (portable fire extinguishers and so on)
- Ensuring that people are able to communicate with public safety and law enforcement authorities, including in situations where communications and electric power have been cut off and when all personnel are outside of the building
- Caring for injured personnel
- Training in CPR and emergency first-aid
- Providing safety personnel who can assist in the evacuation of injured and disabled persons
- Providing the ability to account for visitors and other nonemployees
- Providing emergency shelter in extreme weather conditions
- Providing emergency food and drinking water
- Conducting periodic tests to ensure that evacuation procedures will be adequate in the event of a real emergency
Local emergency management organizations may have additional information available that can assist an organization with its emergency personnel safety procedures.
Disaster Declaration Procedures
Disaster response procedures are initiated when a disaster is declared. However, there needs to be a procedure for the declaration itself so that there will be little doubt as to the conditions that must be present.
Why is a disaster declaration procedure required? Primarily because it’s not always clear whether a situation is a real disaster. Sure, a 7.5 earthquake or a major fire is a disaster, but overcooking popcorn in the microwave and setting off a building’s fire alarm system might not be. Many “in between” situations may or may not be considered disasters. A disaster declaration procedure must state some basic conditions that will help determine whether a disaster should be declared.
Further, who has the authority to declare a disaster? What if senior management personnel frequently travel and may not be around? Who else can declare a disaster? And, finally, what does it mean to declare a disaster—and what happens next? The following points constitute the primary items that organizations need to consider for their disaster declaration procedure.
Form a Core Team
A core team of personnel needs to be established, all of whom will be familiar with the disaster declaration procedure, as well as the actions that must take place once a disaster has been declared. This core team should consist of middle and upper managers who are familiar with business operations, particularly those that are critical. This core team must be large enough so that a requisite few of them are on hand when a disaster strikes. In organizations that have second shift, third shift, and weekend workers, some of the core team members should be those in supervisory positions during those times. However, some of the core team members can be personnel who work “business hours” and are not on-site all of the time.
Declaration Criteria
The declaration procedure must contain some tangible criteria that a core team member can consult to guide him or her down the “Is this a disaster?” decision path.
The criteria for declaring a disaster should be related to the availability and viability of ongoing critical business operations. Some example criteria include any one or more of the following:
- Forced evacuation of a building containing or supporting critical operations that is likely to last for more than four hours
- Hardware, software, or network failures that result in a critical IT system being incapacitated or unavailable for more than four hours
- A major, prolonged outage by an Internet service provider or cloud service provider
- Any security incident that results in a critical IT system being incapacitated for more than four hours (security incidents could involve malware, break-in, attack, sabotage, and so on)
- Any event causing employee absenteeism or supplier shortages that, in turn, results in one or more critical business processes being incapacitated for more than eight hours
- Any event causing a communications failure that results in critical IT systems being unreachable for more than four hours
The preceding examples are a mostly complete list of criteria for many organizations. The duration periods will vary from organization to organization. For instance, a large, pure-online business such as Salesforce.com would probably declare a disaster if its main web sites were unavailable for more than a few minutes. But in an organization where computers are far less critical, an outage of four hours might not be considered a disaster.
- Pulling the Trigger
- When disaster declaration criteria are met, the disaster should be declared. The procedure for disaster declaration could permit any single core team member to declare the disaster, but it may be better to have two or more core team members agree on whether a disaster should be declared. Whether an organization should use a single-person declaration or a group of two or more is each organization’s choice.
All core team members empowered to declare a disaster should have the procedure on hand at all times. In most cases, the criteria should fit on a small, laminated wallet card that each team member can keep close at all times. For organizations that use the consensus method for declaring a disaster, the wallet card should include the names and contact numbers for other core team members so that each will have a way of contacting others.
Next Steps
Declaring a disaster will trigger the start of one or more other response procedures, but not necessarily all of them. For instance, if a disaster is declared because of a serious computer or software malfunction, there is no need to evacuate the building. While this example may be obvious, not all instances will be this clear. Either the disaster declaration procedure itself or each of the subsequent response procedures should contain criteria that will help determine which response procedures should be enacted.
False Alarms
Probably the most common cause of personnel not declaring a disaster is the fear that an actual disaster is not taking place. Core team members empowered with declaring a disaster should not necessarily hesitate. Instead, core team members could convene with additional core team members to reach a firm decision, provided this can be done quickly.
If a disaster has been declared and later it is clear that a disaster has been averted (or did not exist in the first place), the disaster can simply be called off and declared to be over. Response personnel can be contacted and told to cease response activities and return to their normal activities.
TIP
Depending on the level of effort that takes place in the opening minutes and hours of disaster response, the consequences of declaring a disaster when none exists may or may not be significant. In the spirit of continuous improvement, any organization that has had a few false alarms should seek to improve their disaster declaration criteria or procedures. Well-trained and experienced personnel can usually reduce the frequency of false alarms.
Disaster Responsibilities
During a disaster, many important tasks must be performed to evacuate or shelter personnel, assess damage, recover critical processes and systems, and carry out many other functions that are critical to the survival of the enterprise.
About 20 different responsibilities are described here. In a large organization, each responsibility may be staffed with a team of two, three, or many individuals. In small organizations, a few people may incur many responsibilities each, switching from role to role as the situation warrants.
All of these roles should be staffed by people who are available. It is important to remember that many of the “ideal” persons to fill each role may be unavailable during a disaster for several reasons, including the following:
- Injured, ill, or deceased
Some regional disasters will inflict widespread casualties that will include some proportion of response personnel. Those who are injured, ill (in the case of a pandemic, for instance, or who are recovering from a sickness or surgery when the disaster occurs), or who are killed by the disaster are clearly not going to be showing up to help. - Caring for family members
Some types of disasters may cause widespread injury or require mass evacuation. In some of these situations, many personnel will be caring for family members whose immediate needs for safety will take priority over the needs of the workplace. - Unavailable transportation
Some types of disasters include localized or widespread damage to transportation infrastructure, which may result in many persons who are willing to be on-site to help with emergency operations being unable to travel to the work site. - Out of the area
Some disaster response personnel may be away on business travel or on vacation and be unable to respond. However, some persons being away may actually be opportunities in disguise; unaffected by the physical impact of the disaster, they may be able to help out in other ways, such as communications with suppliers, customers, or other personnel. - Communications
Some types of disasters, particularly those that are localized (versus widespread and obvious to an observer), require that disaster response personnel be contacted and asked to help. If a disaster strikes after hours, some personnel may be unreachable. - Fear
Some types of disasters (such as pandemic, terrorist attack, flood, and so on) may instill fear for safety on the part of response personnel who will disregard the call to help and stay away from the work site.
NOTE
Response personnel in all disciplines and responsibilities will need to be able to piece together whatever functionality they are called on to do, using whatever resources are available—this is part art and part science. Although response and contingency plans may make certain assumptions, personnel may find themselves with fewer resources than they need, requiring them to do the best they can with the resources available.
Each role will be working with personnel in many other roles, often working with unfamiliar persons. An entire response and recovery operation may be operating almost like a brand-new organization in unfamiliar settings and with an entirely new set of rules. In typical organizations, teams work well when team members are familiar with, and trust, one another. In a response and recovery operation, the stress level is much higher because the stakes—company survival—are higher, and often the teams are composed of persons who have little experience with one another and these new roles. This will cause additional stress that will bring out the best and worst in people, as illustrated in Figure 5-29.

Figure 5-29 Stress is compounded by the pressure of disaster recovery and the formation of new teams in times of chaos.
Emergency Response
These are the first responders during a disaster. Their top priorities include evacuation or sheltering of personnel, first aid, triage of injured personnel, and possibly firefighting.
Command and Control (Emergency Management)
During disaster response operations, someone must be in charge. In a disaster, resources may be scarce, and many matters will vie for attention. Someone needs to fill the role of decision maker to keep disaster response activities moving and to handle situations that arise. This role may need to be rotated among various personnel, particularly in smaller organizations, to counteract fatigue.
TIP
Although the first person on the scene may be the person in charge initially, that will definitely change as qualified assigned personnel show up and take charge and as the nature of the disaster and response solidifies. The leadership roles may then be passed among key personnel already designated to be in charge.
Documentation
It’s vital that one or more persons continually document the important events during disaster response operations. From decisions, to discussions, to status, to roll call, these events must be written down (and later recorded digitally), so that the details of disaster response can be pieced together afterward. This will help the organization better understand how disaster response unfolded, how decisions were made, and who performed which actions, all of which will help the organization be better prepared for future events.
Internal and External Communications
In many disaster scenarios, personnel may be stripped of many or all of their normal means of communication, such as desk phone, voicemail, e-mail, smartphone, and instant messaging. Yet never are communications as vital as during a disaster, when nothing is going according to plan. Internal communications are needed so that status on various activities can be sent to command and control, and so that priorities and orders can be sent to disaster response personnel.
People outside of the organization also need to know what’s going on when a disaster strikes. There’s a potentially long list of parties who want or need to know the status of business operations during and after a disaster, including
- Customers
- Suppliers
- Partners
- Shareholders
- Neighbors
- Regulators
- Media
- Law enforcement and public safety authorities
These different audiences need different messages, as well as messages in different forms.
- Legal and Compliance
Several needs may arise during a disaster that require the attention of inside or outside legal counsel. Disasters present unique situations that need legal assistance, such as- Interpretation of regulations
- Interpretation of contracts with suppliers and customers
- Management of matters of liability to other parties
TIP
Typical legal matters need to be resolved before the onset of a disaster, with this information included in disaster response procedures, since legal staff members may be unavailable during a disaster.
Damage Assessment
Whether a disaster is a physically violent event, such as an earthquake or volcano, or instead involves no physical manifestation, such as a serious security incident, one or more experts are needed who can examine affected assets and accurately assess the damage. Because most organizations own many different types of assets (from buildings, to equipment, to information), qualified experts are needed to assess each asset type involved. It is not necessary to call upon all available experts—only those whose expertise matches the type of event that has occurred need to be consulted.
Some expertise may go well beyond the skills present in an organization, such as a building structural engineer who can assess potential earthquake damage. In such cases, it may be sensible to retain the services of an outside engineer who will respond and provide an assessment on whether a building is safe to occupy after a disaster. In fact, it may make sense to retain more than one, in case one or more of them is affected by a disaster.
Salvage
Disasters destroy assets that the organization uses to make products or perform services. When a disaster occurs, someone (either a qualified employee or an outside expert) needs to examine assets to determine which are salvageable; then a salvage team needs to perform the actual salvage operation at a pace that meets the organization’s needs.
In some cases, salvage may be a critical-path activity, where critical processes are paralyzed until salvage and repairs or replacements to critically needed machinery can be performed. In other cases, the salvage operation is performed on inventory of finished goods, raw materials, and other items so that business operations can be resumed. Occasionally, when it is obvious that damaged equipment or materials are a total loss, the salvage effort involves selling the damaged items or materials to another organization.
Assessment of damage to assets may be a high priority when an organization will be filing an insurance claim. Insurance may be a primary source of funding for the organization’s recovery effort.
CAUTION
Salvage operations may be a critical-path activity or one that can be carried out well after the disaster. To the greatest extent possible, this should be decided in advance. Otherwise, the command-and-control function will need to decide the priority of salvage operations.
Physical Security
After a disaster, the organization’s usual physical security controls may be compromised. For instance, fencing, walls, and barricades could be damaged, or video surveillance systems may be disabled or have no electric power. These and other failures could lead to increased risk of loss or damage to assets and personnel until those controls can be restored. Also, security controls in temporary quarters such as hot/warm/cold sites and temporary work centers may be inadequate compared to those in primary locations.
Supplies
During emergency and recovery operations, personnel will require supplies of many kinds, from food and drinking water, writing tablets, and pens, to smartphones, portable generators, and extension cords. This function may also be responsible for ordering replacement assets such as servers and network equipment for a cold site.
Transportation
When workers are operating from a temporary location and/or if regional or local transportation systems have been compromised, many arrangements for all kinds of transportation may be required to support emergency operations. These can include transportation of replacement workers, equipment, or supplies by truck, car, rail, sea, or air. The transportation function could also be responsible for arranging for temporary lodging for personnel.
Networks
This technology function is responsible for damage assessment to the organization’s voice and data networks, building/configuring networks for emergency operations, or both. This function may require extensive coordination with external telecommunications service providers, who, by the way, may be suffering the effects of a local or regional disaster as well.
Network Services
This function is responsible for network-centric services such as Domain Name System (DNS), Simple Network Management Protocol (SNMP), network routing, and authentication.
Systems
This function is responsible for building, loading, and configuring the servers and systems that support critical services, applications, databases, and other functions. Personnel may have other resources such as virtualization technology to enable additional flexibility.
Database Management Systems
For critical applications that rely upon database management systems, this function is responsible for building databases on recovery systems and for restoring or recovering data from backup media, replication volumes, or e-vaults onto recovery systems. Database personnel will need to work with systems, network, and applications personnel to ensure that databases are operating properly and are available as needed.
Data and Records
This function is responsible for access to and re-creation of electronic and paper business records. This is a business function that supports critical business processes and works with database management personnel and, if necessary, with data-entry personnel to rekey lost data.
Applications
This function is responsible for recovering application functionality on application servers. This may include reloading application software, performing configuration, provisioning roles and user accounts, and connecting the application to databases, network services, and other application integration issues.
Access Management
This function is responsible for creating and managing user accounts for network, system, and application access. Personnel with this responsibility may be especially susceptible to social engineering and be tempted to create user accounts without proper authority or approval.
Information Security and Privacy
Personnel who serve in this capacity are responsible for ensuring that proper security controls are being carried out during recovery and emergency operations. They will be expected to identify risks associated with emergency operations and to require remedies to reduce risks.
Security personnel will also be responsible for enforcing privacy controls so that employee and customer personal data will not be compromised, even as business operations are affected by the disaster.
Off-site Storage
This function is responsible for managing the effort of retrieving backup media from off-site storage facilities and for protecting that media in transit to the scene of recovery operations. If recovery operations take place over an extended period (more than a couple of days), data at the recovery site will need to be backed up and sent to an off-site media storage facility to protect that information should a disaster occur at the hot/warm/cold site (and what bad luck that would be!).
User Hardware
In many organizations, little productive work gets done when employees don’t have their workstations, printers, scanners, copiers, and other office equipment. Thus, a user hardware function is required to provide, configure, and support the variety of office equipment required by end users working in temporary or alternate locations. This function, like most others, will have to work with many others to ensure that workstations and other equipment are able to communicate with applications and services as needed to support critical processes.
Training
During emergency operations, when response personnel and users are working in new locations (and often on new or different equipment and software), some personnel may need training so that their productivity can be quickly restored. Training personnel will need to be familiar with many disaster response and recovery procedures so that they can help people in those roles understand what is expected of them. This function will also need to be able to dispense emergency operations procedures to these personnel.
Restoration
This function comes into play when IT is ready to migrate applications running on hot/warm/cold site systems back to the original (or replacement) processing center.
Contract Information
This function is responsible for understanding and interpreting legal contracts. Most organizations are a party to one or more legal contracts that require them to perform specific activities, provide specific services, and communicate status if service levels have changed. These contracts may or may not have provisions for activities and services during disasters, including communications regarding any changes in service levels.
This function is vital not only during the disaster planning stages but also during actual disaster response. Customers, suppliers, regulators, and other parties need to be informed according to specific contract terms.
Recovery Procedures
Recovery procedures are the instructions that key personnel use to bootstrap services (such as IT systems and other business-enabling technologies) that support the critical business functions identified in the BIA and CA. The recovery procedures should work hand-in-hand with the technologies that may have been added to IT systems to make them more resilient.
An example would be useful here: A fictitious company, Acme Rocket Boots, determines that its order-entry business function is highly critical to the ongoing viability of the business and sets recovery objectives to ensure that order entry would be continued within no more than 48 hours after a disaster. Acme determines that it needs to invest in storage, backup, and replication technologies to make a 48-hour recovery possible. Without these investments, IT systems supporting order-entry would be down for at least ten days until they could be rebuilt from scratch. Acme cannot justify the purchase of systems and software to facilitate an auto-failover of the order-entry application to hot-site DR servers. Instead, the recovery procedure would require that the database be rebuilt from replicated data on cloud-based servers. Other tasks, such as installing recent patches, would also be necessary to make recovery servers ready for production use. All of the tasks required to make the systems ready constitute the body of recovery procedures needed to support the business order-entry function.
This example is, of course, a gross oversimplification. Actual recovery procedures could take potentially dozens of pages of documentation, and procedures would also be necessary for network components, end-user workstations, network services, and other supporting IT services required by the order-entry application. And those are the procedures needed just to get the application running again. More procedures would be needed to keep the applications running properly in the recovery environment.
Continuing Operations Procedures
Procedures for continuing operations have more to do with business processes than they do with IT systems. However, the two are related, since the procedures for continuing critical business processes have to fit hand-in-hand with the procedures for operating supporting IT systems that may also (but not necessarily) be operating in a recovery or emergency mode.
Let me clarify that last statement: It is entirely conceivable that a disaster could strike an organization with critical business processes that operate in one city but that are supported by IT systems located in another city. A disaster could strike the city with the critical business function, which means that personnel may have to continue operating that business function in another location, on the original, fully featured IT application. It is also possible that a disaster could strike the city with the IT application, forcing it into an emergency/recovery mode in an alternate location, while users of the application are operating in a mostly business-as-usual mode. And, of course, a disaster could strike both locations (or a disaster could strike in one location where both the critical business function and its supporting IT applications reside), throwing both the critical business function and its supporting IT applications into emergency mode. Any organization’s reality could be even more complex than this: just add dependencies on external application service providers, applications with custom interfaces, or critical business functions that operate in multiple cities. If you wondered why disaster recovery and business continuity planning were so complicated, perhaps your appreciation has grown just now.
Restoration Procedures
When a disaster has occurred, IT operations need to take up residence temporarily in an alternate processing site while repairs are performed on the original site. Once those repairs are completed, IT operations would need to be transitioned back to the main (or replacement) processing facility. You should expect that the procedures for this transition would also be documented (and tested—testing is discussed later in this chapter).
NOTE
Transitioning applications back to the original processing site is not necessarily just a second iteration of the initial move to the cloud/hot/warm/cold site. Far from it: the recovery site may have been a skeleton (in capacity, functionality, or both) of its original self. The objective is not necessarily to move the functionality at the recovery site back to the original site, but to restore the original functionality to the original site.
Let’s continue the Acme Rocket Boots example: The company’s order-entry application at the DR site had only basic, not extended, functions. For instance, customers could not look at order history, and they could not place custom orders; they could order only off-the-shelf products. But when the application is moved back to the primary processing facility, the history of orders accumulated on the DR application needs to be merged into the main order history database, which was not a part of the DR plan.
Considerations for Continuity and Recovery Plans
A considerable amount of detailed planning and logistics must go into continuity and recovery plans if they are to be effective.
Availability of Key Personnel
An organization cannot depend upon every member of its regular expert workforce to be available in a disaster. As discussed earlier in this chapter in more detail, personnel may be unavailable for a number of reasons, including
- Injury, illness, or death
- Caring for family members
- Unavailable transportation
- Damaged transportation infrastructure
- Being out of the area
- Lack of communications
- Fear related to the disaster and its effects
TIP
An organization must develop thorough and accurate recovery and continuity documentation as well as cross-training and plan testing. When a disaster strikes, an organization has one chance to survive, and survival depends upon how well the available personnel are able to follow recovery and continuity procedures and to keep critical processes functioning properly.
A successful disaster recovery operation requires available personnel who are located near company operations centers. While the primary response personnel may consist of the individuals and teams responsible for day-to-day corporate operations, others need to be identified. In a disaster, some personnel will be unavailable for many reasons.
Key personnel, as well as their backup persons, need to be identified. Backup personnel can consist of employees who have familiarity with specific technologies, such as operating system, database, and network administration, and who can cover for primary personnel if needed. Sure, it would be desirable for these backup personnel also to be trained in specific recovery operations, but at the very least, if these personnel have access to specific detailed recovery procedures, having them on a call list is probably better than having no available personnel during a disaster.
Besides employees, many other parties need to be notified in the event of a disaster. Outside parties need to be aware of the disaster as well as of basic changes in business conditions.
In a regional disaster such as a hurricane or earthquake, nearby parties will certainly be aware of the disaster and that your organization is involved in it somehow. However, those parties may not be aware of the status of business operations immediately after the disaster: a regional event’s effects can range from complete destruction of buildings and equipment to no damage at all and business-as-usual conditions. Unless key parties are notified of the status, they may have no other way to know for sure.
Parties that need to be contacted may include
- Key suppliers
This may include electric and gas utilities, fuel delivery, and materials delivery. In a disaster, an organization will often need to impart special instructions to one or more suppliers, requesting delivery of extra supplies or temporary cessation of deliveries. - Key customers
Many organizations have key customers whose relationships are valued above most others. These customers may depend on a steady delivery of products and services that are critical to their own operations; in a disaster, those customers may have a dire need to know whether such deliveries will be able to continue or not and under what circumstances. - Public safety
Police, fire, and other public safety authorities may need to be contacted, not only for emergency operations such as firefighting, but also for any required inspections or other services. It is important that “business office” telephone numbers for these agencies be included on contact lists, as 911 and other emergency lines may be flooded by calls from others. - Insurance adjusters
Most organizations rely on insurance companies to protect their assets from damage or loss in a disaster. Because insurance adjustment funds are often a key part of continuing business operations in an emergency, it’s important to be able to reach insurers as soon as possible after a disaster has occurred. - Regulators
In some industries, organizations are required to notify regulators of certain types of disasters. While regulators obviously may be aware of noteworthy regional disasters, they may not immediately know of an event’s specific effects on an organization. Further, some types of disasters are highly localized and may not be newsworthy, even in a local city. - Media
Media outlets such as newspapers and television stations may need to be notified as a means of quickly reaching the community or region with information about the effects of a disaster on organizations. - Shareholders
Organizations are usually obliged to notify their shareholders of any disastrous event that affects business operations. This may be the case whether the organization is publicly or privately held.
The persons or teams responsible for communicating with these outside parties will need to have all of the individuals and organizations included in a list of parties to contact. This information should all be included in emergency response procedures.
Wallet cards containing emergency contact information should be prepared for core team personnel for the organization as well as for members in each department who would be actively involved in disaster response. Wallet cards are advantageous, because most personnel will have a wallet, notebook, or purse nearby at all times, even when away from home, running errands, traveling, or on vacation. Information on the wallet card should include contact information for fellow team members, a few of the key disaster response personnel, and any conference bridges or emergency call-in numbers that are set up. An example wallet card is shown in Figure 5-30.

Figure 5-30 Example laminated wallet card for core team participants with emergency contact information and disaster declaration criteria
Emergency Supplies
The onset of a disaster may cause personnel to be stranded at a work location, possibly for several days. This can be caused by a number of reasons, including inclement weather that makes travel dangerous or a transportation infrastructure that is damaged or blocked with debris.
Emergency supplies should be laid up at a work location and made available to personnel stranded there, regardless of whether they are supporting a recovery effort or not (it’s also possible that severe weather or a natural or human-made event could make transportation dangerous or impossible).
A disaster can also prompt employees to report to a work location (at the primary location or at an alternate site) where they may remain for days at a time, even around the clock if necessary. A situation like this may make the need for emergency supplies less critical, but it still may be beneficial to the recovery effort to make supplies available to support recovery personnel.
An organization stocking emergency supplies at a work location should consider including the following items:
- Drinking water
- Food rations
- First-aid supplies
- Blankets
- Flashlights
- Battery or crank-powered radio
Local emergency response authorities may recommend other supplies be kept at a work location as well.
Communications
Communications within organizations, as well as with customers, suppliers, partners, shareholders, regulators, and others, is vital under normal business conditions. During a disaster and subsequent recovery and restoration operations, such communications are more important than ever, while many of the usual means for communications may be impaired.
Disaster response procedures need to include a call tree. This is a method where the first personnel involved in a disaster begin notifying others in the organization, informing them of the developing disaster and enlisting their assistance. Just as the branches of a tree originate at the trunk and are repeatedly subdivided, a call tree is most effective when each person in the tree can make just a few phone calls. Not only will the notification of important personnel proceed more quickly, but each person will not be overburdened with many calls.
Remember that in a disaster a significant portion of personnel may be unavailable or unreachable. Therefore, a call tree should be structured so that there is sufficient flexibility as well as assurance that all critical personnel will be contacted. Figure 5-31 shows an example call tree.
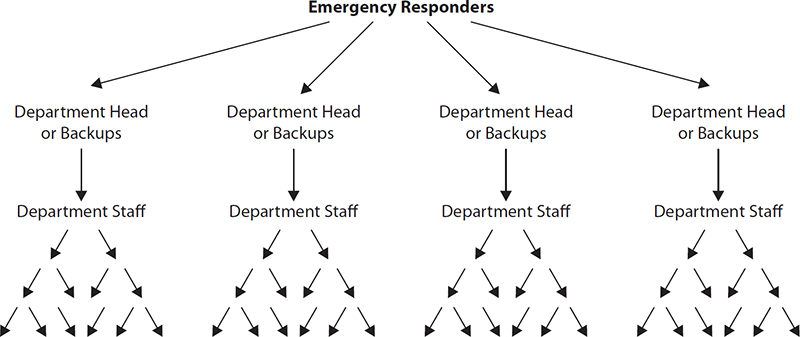
Figure 5-31 Example call tree structure
An organization can also use an automated outcalling system to notify critical personnel of a disaster. Such a system can play a prerecorded message or request that personnel call an information number to hear a prerecorded message. Most outcalling systems keep a log of which personnel have been successfully reached.
An automated calling system should not be located in the same geographic region as the disaster. A regional disaster could damage the system or make it unavailable during a disaster. The system should be Internet accessible so that response personnel can access it to determine which personnel have been notified and to make any needed changes before or during a disaster.
Transportation
Some types of disasters may make certain modes of transportation unavailable or unsafe. Widespread natural disasters, such as earthquakes, volcanoes, hurricanes, and floods, can immobilize virtually every form of transportation, including highways, railroads, boats, and airplanes. Other types of disasters may impede one or more types of transportation, which could result in overwhelming demand for the available modes. High volumes of emergency supplies may be needed during and after a disaster, but damaged transportation infrastructure often makes the delivery of those supplies difficult.
- Components of a Business Continuity Plan
The complete set of business continuity plan documents will include the following:- Supporting project documents
These will include the documents created at the beginning of the business continuity project, including the project charter, project plan, statement of scope, and statement of support from executives. - Analysis documents
These include the- Business impact analysis (BIA)
- Threat assessment and risk assessment
- Criticality analysis
- Documents defining approved recovery targets such as recovery time objective (RTO) and recovery point objective (RPO)
- Response documents
These are all the documents that describe the required action of personnel when a disaster strikes, plus documents containing information required by those same personnel. Examples of these documents include - Business recovery (or resumption) plan
This describes the activities required to recover and resume critical business processes and activities. - Occupant emergency plan (OEP)
This describes activities required to care for occupants safely in a business location during a disaster. This will include both evacuation procedures and sheltering procedures, each of which may be required, depending upon the type of disaster that occurs. - Emergency communications plan
This describes the types of communications imparted to many parties, including emergency response personnel, employees in general, customers, suppliers, regulators, public safety organizations, shareholders, and the public. - Contact lists
These contain names and contact information for emergency response personnel as well as for critical suppliers, customers, and other parties. - Disaster recovery plan
This describes the activities required to restore critical IT systems and other critical assets, whether in alternate or primary locations. - Continuity of operations plan (COOP)
This describes the activities required to continue critical and strategic business functions at an alternate site. - Security incident response plan (SIRP)
This describes the steps required to deal with a security incident that could reach disastrous proportions. - Test and review documents
This is the entire collection of documents related to tests of all of the different types of business continuity plans, as well as reviews and revisions to documents.
- Supporting project documents
Testing Recovery and Continuity Plans
It’s surprising what you can accomplish when no one is concerned about who gets the credit.
*–*Ronald Reagan
Business continuity and disaster recovery plans may look elegant and even ingenious on paper, but their true business value is unknown until their worth is proven through testing.
The process of testing DR and BC plans uncovers flaws not only in the plans, but also in the systems and processes that they are designed to protect. For example, testing a system recovery procedure may point out the absence of a critically needed hardware component, or a recovery procedure may contain a syntax or grammatical error that misleads the recovery team member and results in recovery delays. Testing is designed to uncover these types of issues.
Recovery and continuity plans need to be tested to prove their viability. Without testing, an organization has no way of really knowing whether its plans are effective. With ineffective plans, an organization has a far smaller chance of surviving a disaster.
Recovery and continuity plans have built-in obsolescence—not by design, but by virtue of the fact that technology and business processes in most organizations are undergoing constant change and improvement. Thus, it is imperative that newly developed or updated plans be tested as soon as possible to ensure their effectiveness.
Types of tests range from lightweight and unobtrusive to intense and disruptive and include the following:
- Document review
- Walkthrough
- Simulation
- Parallel test
- Cutover test
These tests are described in more detail in this section.
TIP
Usually, an organization will perform the less intensive tests first to identify the most obvious flaws and then follow with tests that require more effort.
Each type of test requires advance preparation and recordkeeping. Preparation will consist of several activities, including
- Participants
The organization needs to identify personnel who will participate in an upcoming test. It is important to identify all relevant skill groups and department stakeholders so that the test will include a full slate of contributors. - Schedule
The availability of each participant needs to be confirmed so that the test will include participation from all stakeholders. - Facilities
For all but the document review test, proper facilities need to be identified and set up. This might consist of a large conference room or training room. If the test will take place over several hours, one or more meals and/or refreshments may be needed as well. - Scripting
The simulation test requires some scripting, usually in the form of one or more documents that describe a developing scenario and related circumstances. Scenario scripting can make parallel and cutover tests more interesting and valuable, but this can be considered optional. - Recordkeeping
For all of the tests except the document review, one or more persons should take good notes that can be collected and organized after the test is completed. - Contingency plan
The cutover test involves the cessation of processing on primary systems and the resumption of processing on recovery systems. This is the highest risk plan, and things can go wrong. A contingency plan to get primary systems running again in case something goes wrong during the test needs to be developed.
These preparation activities are shown in Table 5-13.
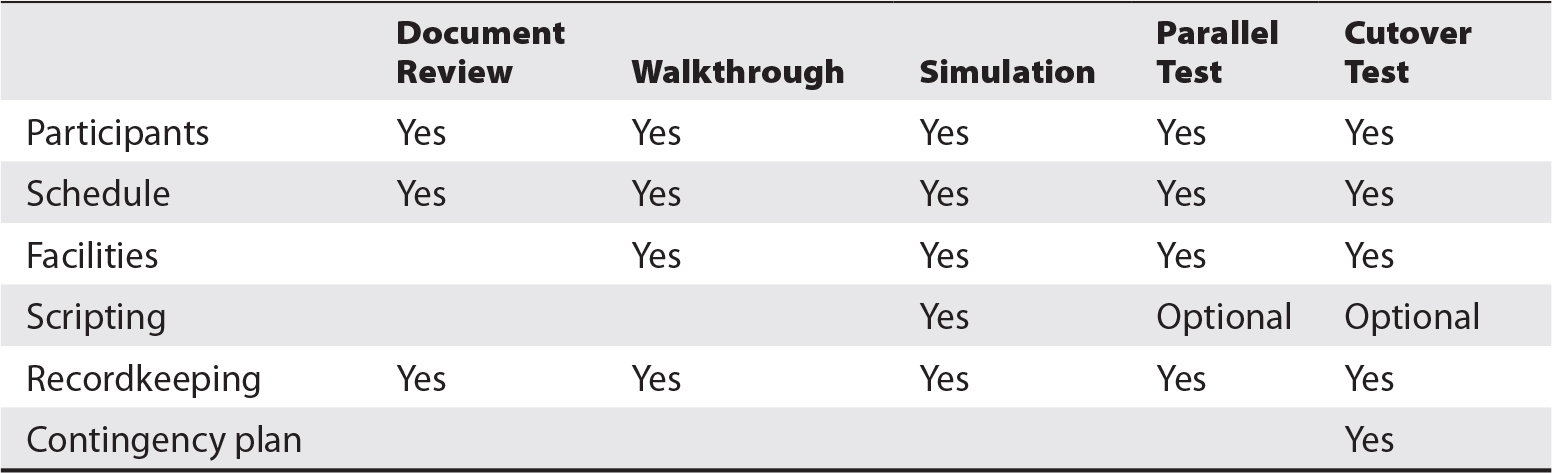
Table 5-13 Preparation Activities Required for Each Type of DR/BC Test
The various types of tests are discussed next.
Document Review
A document review test is a review of some or all disaster recovery and business continuity plans, procedures, and other documentation. Individuals typically review these documents on their own, at their own pace, but within whatever time constraints or deadlines have been established.
The purpose of a document review test is to review the accuracy and completeness of document content. Reviewers should read each document with a critical eye, point out any errors, and annotate the document with questions or comments that can be sent back to the document’s author(s), who can make any necessary changes.
If significant changes are needed in one or more documents, the project team may want to include a second round of document review before moving on to more resource-intensive tests.
The owner or document manager for the organization’s business continuity and disaster recovery planning project should document which persons review which documents and perhaps even include the review copies or annotations. This practice will create a more complete record of the activities related to the development and testing of important BCP planning and response documents. It will also help to capture the true cost and effort of the development and testing of BCP capabilities in the organization.
Walkthrough
A walkthrough is similar to a document review: it’s a review of just the BCP documents. However, where a document review is carried out by individuals working on their own, a walkthrough is performed by a group of individuals in a live discussion.
A walkthrough is usually facilitated by a leader who guides the participants page by page through each document. The leader may read sections of the document aloud, describe various scenarios where information in a section might be relevant, and take comments and questions from participants.
A walkthrough is likely to take considerably more time than a document review. One participant’s question on some minor point in the document could spark a worthwhile and lively discussion that could last a few minutes to an hour. The group leader or another person will need to take careful notes to record any deficiencies found in any of the documents as well as issues to be handled after the walkthrough. The leader will also need to control the pace of the review so that the group does not get unnecessarily hung up on minor points. Some discussions will need to be cut short or tabled for a later time or for an offline conversation among interested parties.
Even if major revisions are needed in recovery documents, it probably will be infeasible to conduct another walkthrough with updated documents. However, follow-up document reviews are probably warranted to ensure that the documents were updated appropriately, at least in the opinion of the walkthrough participants.
CAUTION
Participants in the walkthrough should carefully consider that the potential audience for recovery procedures may be persons who are not as familiar as they are with systems and processes. They need to remember that the ideal personnel may not be available during a real disaster. Participants also need to realize that the skill level of recovery personnel might be a little below that of the experts who operate systems and processes in normal circumstances. Finally, walkthrough participants need to remember that systems and processes undergo almost continuous change, which could render some parts of the recovery documentation obsolete or incorrect all too soon.
Simulation
A simulation is a test of disaster recovery and business continuity procedures where the participants take part in a “mock disaster” to add some realism to the process of thinking their way through procedures in emergency response documents.
A simulation could be an elaborate and choreographed walkthrough test, where a facilitator reads from a script and describes a series of unfolding events in a disaster such as a hurricane or an earthquake. This type of simulation could almost be viewed as “playacting,” where the script is the set of emergency response documentation. By stimulating the imagination of simulation participants, it’s possible for participants to imagine that a disaster is taking place, which may help them better understand what real disaster conditions could be like. It will help tremendously if the facilitator has experienced one or more disaster scenarios so that he or she can add more realism when describing events.
To make the simulation more credible and valuable, the scenario that is chosen should have a reasonable chance of actually occurring in the local area. Good choices would include an earthquake in San Francisco or Los Angeles, a volcanic eruption in Seattle, or an avalanche in Switzerland. A poor choice would be a hurricane or tsunami in central Asia, because these events would not ever occur there.
A simulation can also go a few steps further. For instance, the simulation can take place at an established emergency operations center, the same place where emergency command and control would operate in a real disaster. Also, the facilitator could change some of the participants’ roles to simulate the real absence of certain key personnel to see how remaining personnel might conduct themselves in a real emergency.
TIP
The facilitator of a simulation is limited only by his or her own imagination when organizing a simulation. One important fact to remember, though, is that a simulation does not actually affect any live or DR systems—it’s all as pretend as the make-believe cardboard televisions and computers in furniture stores.
Parallel Test
A parallel test is an actual test of disaster recovery and/or business continuity response plans and their supporting IT systems. The purpose of a parallel test is to evaluate the ability of personnel to follow directives in emergency response plans—to set up the actual DR business processing or data processing capability. In a parallel test, personnel set up the IT systems that would be used in an actual disaster and operate those IT systems with real business transactions to determine whether the IT systems correctly perform the processing.
The outcome of a parallel test is threefold:
- It evaluates the accuracy of emergency response procedures.
- It evaluates the ability of personnel to follow the emergency response procedures correctly.
- It evaluates the ability of IT systems and other supporting apparatus to process real business transactions properly.
A parallel test is so named because live production systems continue to operate, while backup IT systems are processing business transactions in parallel to see if they process them the same as the live production systems do.
Setting up a valid parallel test is complicated in many cases. In effect, you need to insert a logical “Y cable” into the business process flow so that the information flow will split and flow both to production systems (without interfering with their operation) and to backup systems. Results of transactions need to be compared. Personnel need to be able to determine whether the backup systems would be able to output correct data without actually having them do so. In many complex environments, you would not want the DR system to actually feed information back into a live environment, because that may cause duplicate events to occur someplace else in the organization (or with customers, suppliers, or other parties). For instance, in a travel reservations system, you would not want a DR system to book actual travel, because that would cost real money and consume available space on an airline or other mode of transportation. But it would be important to know whether the DR system would be able to perform those functions. Somewhere along the line, it will be necessary to “unplug” the DR system from the rest of the environment and manually examine results to see if they appear to be correct.
Organizations that do want to see if their backup/DR systems can manage a real workload can perform a cutover test, which is discussed next.
Cutover Test
A cutover test is the most intrusive type of disaster recovery test. It will also provide the most reliable results in terms of answering the question of whether backup systems have the capacity and correct functionality to shoulder the real workload properly.
The consequences of a failed cutover test, however, might resemble an actual disaster: if any part of the cutover test fails, then real, live business processes will be going without the support of IT applications as though a real outage or disaster were in progress. But even a failure like this would show you that “no, the backup systems won’t work in the event a real disaster were to happen later today.”
In some respects, a cutover test is easier to perform than a parallel test. A parallel test is a little trickier, since business information is required to flow to the production system and to the backup system, which means that some artificial component has been somehow inserted into the environment. However, with a cutover test, business processing does take place on the backup systems only, which can often be achieved through a simple configuration someplace in the network or the systems layer of the environment.
TIP
Not all organizations perform cutover tests, because they take a lot of resources to set up and they are risky. Many organizations find that a parallel test is sufficient to determine whether backup systems are accurate, and the risk of an embarrassing incident is almost zero with a parallel test.
Documenting Test Results
Every type and every iteration of DR plan testing needs to be documented. It’s not enough to say, “We did the test on September 10, 2019, and it worked.” First of all, no test goes perfectly—opportunities for improvement are always identified. But the most important part of testing is to discover what parts of the test still need work so that those parts of the plan can be fixed before the next test (or a real disaster).
As with any well-organized project, success is in the details. The road to success is littered with big and little mistakes, and all of the things that are identified in every sort of DR test need to be detailed so that the next iteration of the test will give better results.
Recording and comparing detailed test results from one test to the next will also help the organization to measure progress. By this I mean that the quality of emergency response plans should steadily improve from year to year. Simple mistakes of the past should not be repeated, and the only failures in future tests should be in new and novel parts of the environment that weren’t well thought out to begin with. And even these should diminish over time.
Debriefing to Improving Recovery and Continuity Plans
Every test of recovery and response plans should include a debrief or review so that participants can discuss the outcome of the test: what went well, what went wrong, and how things should be done differently next time. All of this information should be collected by someone who will be responsible for making changes to relevant documents. The updated documents should be circulated among the test participants who can confirm whether their discussion and ideas are properly reflected in the document.
Training Personnel
The value and usefulness of a high-quality set of disaster response and continuity plans and procedures will be greatly diminished if those responsible for carrying out the procedures are unfamiliar with them.
A person cannot learn to ride a bicycle by reading even the most detailed how-to instructions on the subject, so it’s equally unrealistic to expect personnel to be able to carry out disaster response procedures properly if they are inexperienced in those procedures.
Several forms of training can be made available for the personnel who are expected to be available if a disaster strikes, including
- Document review
Personnel can carefully read through procedure documents to become familiar with the nature of the recovery procedures. But, as mentioned earlier, this alone may be insufficient. - Participation in walkthroughs
People who are familiar with specific processes and systems that are the subject of walkthroughs should participate in them. Exposing personnel to the walkthrough process will not only help to improve the walkthrough and recovery procedures, but will also provide a learning experience for participants. - Participation in simulations
Taking part in simulations will similarly benefit the participants by giving them the experience of thinking through a disaster. - Participation in parallel and cutover tests
Other than experiencing an actual disaster and its recovery operations, no experience is quite like participating in parallel and cutover tests. Here, participants will gain actual hands-on experience with critical business processes and IT environments by performing the actual procedures that they would in the event of a disaster. When a disaster strikes, those participants can draw upon their memory of having performed those procedures in the past, instead of just the memory of having read the procedures.
You can see that all of the levels of tests that need to be performed to verify the quality of response plans are also training opportunities for personnel. The development and testing of disaster-related plans and procedures provide a continuous learning experience for all of the personnel involved.
Making Plans Available to Personnel When Needed
When a disaster strikes, often one of the effects is no access to even the most critical IT systems. Given a 40-hour workweek, there is roughly a 25 percent likelihood that critical personnel will be at the business location when a disaster strikes (at least the violent type of disaster that strikes with no warning, such as an earthquake—other types of disasters, such as hurricanes, may afford the organization a little bit of time to anticipate the disaster’s impact). The point is that chances are very good that the personnel who are available to respond may be unable to access the procedures and other information that they will need, unless special measures are taken.
CAUTION
Complete BCP documentation often contains details of key systems, operating procedures, recovery strategies, and even vendor and model identification of in-place equipment. This information can be misused if available to unauthorized personnel, so the mechanism selected for ensuring availability must include planning to prevent inadvertent disclosure.
Response and recovery procedures can be made available to personnel during a disaster in several ways:
- Hard copy
Although many have grown accustomed to the paperless office, disaster recovery and response documentation should be available in hardcopy form. Copies, even multiple copies, should be available for each responder, with a copy at the workplace and another at home, and possibly even a set in the responder’s vehicle. - Soft copy
Traditionally, softcopy documentation is kept on file servers, but as you might expect, those file servers might be unavailable in a disaster. Soft copies should be available on responders’ portable devices (laptops, tablets, and smartphones). An organization can also consider issuing documentation on memory sticks and cards. Depending upon the type of disaster, it can be difficult to know what resources will be available to access documentation, so making it available in more than one form will ensure that at least one copy of it will be available to the personnel who need access to it. - Alternate work/processing site
Organizations that utilize a hot/warm/cold site for the recovery of critical operations can maintain hard copies and/or soft copies of recovery documentation there. This makes perfect sense; personnel working at an alternate processing or work site will need to know what to do, and having those procedures on-site will facilitate their work. - Online
Soft copies of recovery documentation can be archived on an Internet-based site that includes the ability to store data. Almost any type of online service that includes authentication and the ability to upload documents could be suitable for this purpose. - Wallet cards
It’s unreasonable to expect to publish recovery documentation on a laminated wallet card, but those cards could be used to store the contact information for core response team members as well as a few other pieces of information, such as conference bridge codes, passwords to online repositories of documentation, and so on. An example wallet card appears earlier in this chapter, in Figure 5-30.
Maintaining Recovery and Continuity Plans
Business processes and technology undergo almost continuous change in most organizations. A business continuity plan that is developed and tested is liable to be outdated within months and obsolete within a year. If much more than a year passes, a DR plan in some organizations may approach uselessness. This section discusses how organizations need to keep their DR plans up-to-date and relevant.
A typical organization needs to establish a schedule whereby the principal DR documents will be reviewed. Depending on the rate of change, this could be as frequently as quarterly or as seldom as every two years.
Further, every change, however insignificant, in business processes and information systems should include a step to review, and possibly update, relevant DR documents. That is, a review of, and possibly changes to, relevant DR documents should be a required step in every business process engineering or information systems change process and a key component of the organization’s information systems development life cycle (SDLC). If this is done faithfully, then you would expect that the annual review of DR documents would conclude that few (if any) changes were required, although it is still a good practice to perform a periodic review, just to be sure.
Periodic testing of DR documents and plans, discussed in detail in the preceding section, is another vital activity. Testing validates the accuracy and relevance of DR documents, and any issues or exceptions in the testing process should precipitate updates to appropriate documents.
Sources for Best Practices
It is unnecessary to begin BCP and disaster recovery planning (DRP) by first inventing a practice or methodology. BCP and DRP are advanced professions with several professional associations, professional certifications, international standards, and publications. Any or all of these are, or can lead to, sources of practices, processes, and methodologies:
- U.S. National Institute of Standards and Technology (NIST)
This branch of the U.S. Department of Commerce is responsible for developing business and technology standards for the federal government. The quality of the standards developed by NIST is exceedingly high, and as a result many private organizations all over the world are adopting them. The NIST web site is at https://www.nist.gov. - Business Continuity Institute (BCI)
This membership organization is dedicated to the advancement of business continuity management. BCI has more than 8,000 members in almost 100 countries. BCI holds several events around the world, prints a professional journal, and it has developed a professional certification, the Certificate of the BCI (CBCI). Its web site is at https://www.thebci.org. - U.S. National Fire Protection Agency (NFPA)
NFPA has developed a pre-incident planning standard, NFPA 1620, which addresses the protection, construction, and features of buildings and other structures. It also requires the development of pre-incident plans that emergency responders can use to deal with fires and other emergencies. The NFPA web site is at https://www.nfpa.org. - U.S. Federal Emergency Management Agency (FEMA)
FEMA is a part of the Department of Homeland Security (DHS) and is responsible for emergency disaster relief planning information and services. FEMA’s most visible activities are its relief operations in the wake of hurricanes and floods in the United States. Its web site is at https://www.fema.gov. - Disaster Recovery Institute International (DRI International)
This professional membership organization provides education and professional certifications for DRP professionals. Its web site is at https://drii.org. Its certifications include- Associate Business Continuity Professional (ABCP)
- Certified Business Continuity Vendor (CBCV)
- Certified Functional Continuity Professional (CFCP)
- Certified Business Continuity Professional (CBCP)
- Master Business Continuity Professional (MBCP)
- Certified Business Continuity Auditor (CBCA)
- Certified Business Continuity Lead Auditor (CBCLA)
- Business Continuity Management Institute (BCM Institute)
This professional association specializes in education and professional certification. BCM Institute is a co-organizer of the World Continuity Congress, an annual conference that is dedicated to business continuity and disaster recovery planning. Its web site is at https://www.bcm-institute.org. Certifications offered by BCM Institute include- Business Continuity Certified Expert (BCCE)
- Business Continuity Certified Specialist (BCCS)
- Business Continuity Certified Planner (BCCP)
- Business Continuity Certified Auditor (BCCA)
- Business Continuity Certified Lead Auditor (BCCLA)
- DR Certified Planner (DRCP)
- Disaster Recovery Certified Expert (DRCE)
- Disaster Recovery Certified Specialist (DRCS)
- Crisis Management Certified Planner (CMCP)
- Crisis Management Certified Specialist (CMCS)
- Crisis Management Certified Expert (CMCE)
- Crisis Communication Certified Planner (CCCP)
- Crisis Communication Certified Specialist (CCCS)
- Crisis Communication Certified Expert (CCCE)
Disaster Recovery Planning
DRP is undertaken to reduce risks related to the onset of disasters and other events and is closely related to BCP. The groundwork for DRP begins in BCP activities such as the business impact analysis, criticality analysis, establishment of recovery objectives, and testing. The outputs from these activities are the key inputs to DRP:
- The business impact analysis and criticality analysis help to prioritize which business processes (and, therefore, which IT systems) are the most important.
- Key recovery targets specify how quickly specific IT applications are to be recovered. This guides DRP personnel as they develop new IT architectures that make IT systems compliant with those objectives.
- Testing of DRP plans can be performed in coordination with tests of BCP plans to simulate real disasters and disaster response more accurately.
Business continuity planning is discussed in detail in Chapter 2.
Disaster Response Team Roles and Responsibilities
Disaster recovery plans need to specify the teams that are required for disaster response, as well as each team’s roles and responsibilities. Table 5-14 describes several teams and their roles.
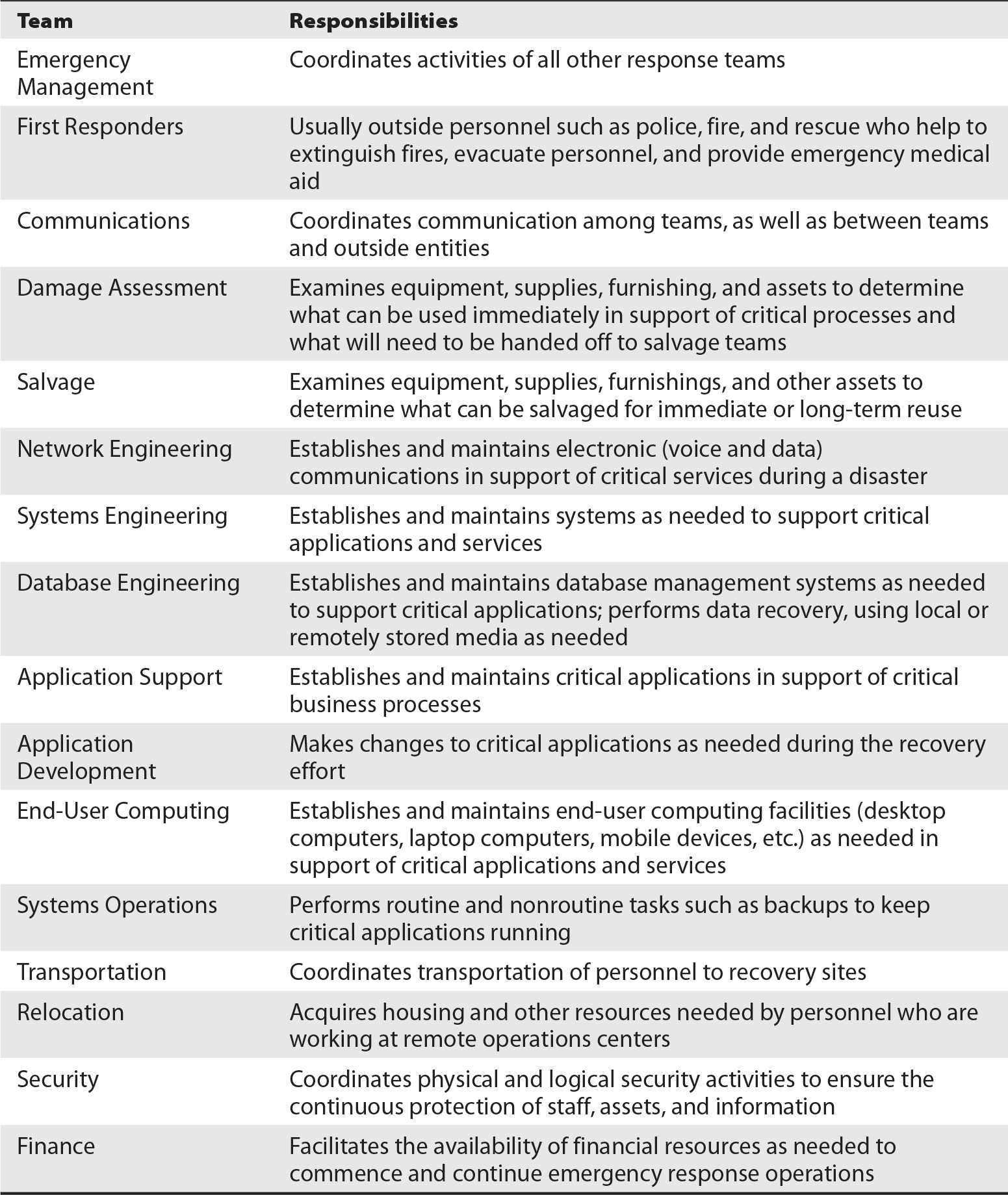
Table 5-14 Disaster Response Teams’ Roles and Responsibilities
NOTE
Some of the roles in Table 5-14 may overlap with responsibilities defined in the organization’s BCP. DR and BC planners will need to work together to ensure that the organization’s overall response to disaster is appropriate and does not overlook vital functions. Also, because of variations in organizations’ disaster response plans, some of these teams will not be needed in some organizations.
Recovery Objectives
During the business impact analysis and criticality analysis phases of a BC/DR project, the speed with which each business activity (with its underlying IT systems) needs to be restored after a disaster is determined.
Recovery Time Objective
Recovery time objective (RTO) is the period from the onset of an outage until the resumption of service. RTO is usually measured in hours or days. Each process and system in the BIA should have an RTO value.
RTO does not mean that the system (or process) has been recovered to 100 percent of its former capacity. Far from it—in an emergency situation, management may determine that a DR server in another city with, say, 60 percent of the capacity of the original server is adequate. That said, an organization could establish two RTO targets, one for partial capacity and one for full capacity.
NOTE
For a given organization, it’s probably best to use one unit of measure for recovery objectives for all systems. That will help to avoid any errors that would occur during a rank-ordering of systems so that, for example, two days does not appear to be a shorter period than four hours.
Further, a system that has been recovered in a disaster situation might not have 100 percent of its functionality. For instance, an application that lets users view transactions that are more than two years old may, in a recovery situation, only contain 30 days’ worth of data. Again, such a decision is usually the result of a careful analysis of the cost of recovering different features and functions in an application environment. In a larger, complex environment, some features might be considered critical, while others are less so.
CAUTION
Senior management should be involved in any discussion related to recovery system specifications in terms of capacity, integrity, or functionality.
Recovery Point Objective A recovery point objective (RPO) is the period of time for which recent data will be irretrievably lost in a disaster. Like RTO, RPO is usually measured in hours or days. However, for critical transaction systems, RPO could even be measured in minutes or seconds.
RPO is usually expressed as a worst-case figure; for instance, a transaction processing system RPO will be two hours or less.
The value of a system’s RPO is usually a direct result of the frequency of data backup or replication. For example, if an application server is backed up once per day, the RPO is going to be at least 24 hours (or one day, whichever way you like to express it). Maybe it will take three days to rebuild the server, but once data is restored from backup tape, no more than the last 24 hours of transactions are lost. In this case, the RTO is three days and the RPO is one day.
Publishing RTO and RPO Figures
If the storage system for an application takes a snapshot every hour, the RPO could be one hour, unless the storage system itself was damaged in a disaster. If the snapshot is replicated to another storage system four times per day, then the RPO might be better expressed as six to eight hours.
The last example brings up an interesting point. There may not be one “golden” RPO figure for a given system. Instead, the severity of a disrupting event or a disaster will dictate the time to get systems running again (RTO) with a certain amount of data loss (RPO). Here are some examples:
- A server’s CPU or memory fails and is replaced and restarted in two hours. No data is lost. The RTO is two hours and the RPO is zero.
- The storage system supporting an application suffers a hardware failure that results in the loss of all data. Data is recovered from a snapshot on another server taken every six hours. The RPO is six hours in this case.
- The database in a transaction application is corrupted and must be recovered. Backups are taken twice per day. The RPO is 12 hours. However, it takes 10 hours to rebuild indexes on the database, so the RTO is closer to 22–24 hours, since the application cannot be returned to service until indexes are available.
NOTE
When publishing RTO and RPO figures to customers, it’s best to publish the worst-case figures: “If our data center burns to the ground, our RTO is X hours and the RPO is Y hours.” Saying it that way would be simpler than publishing a chart that shows RPO and RTO figures for various types of disasters.
Pricing RTO and RPO Capabilities
Generally speaking, the shorter the RTO or RPO for a given system, the more expensive it will be to achieve the target. Table 5-15 depicts a range of RTOs along with the technologies needed to achieve them and their relative cost.

Table 5-15 The Lower the RTO, the Higher the Cost to Achieve It
The BCP project team needs to understand the relationship between the time required to recover an application and the cost required to recover the application within that time. A shorter recovery time is more expensive, and this relationship is not linear. This means that reducing RPO from three days to six hours may mean that the equipment and software investment might double, or it might increase eightfold. There are so many factors involved in the supporting infrastructure for a given application that the BCP project team has to just knuckle down and develop the cost for a few different RTO and RPO figures. Once costs have been analyzed and approved, the actual DR capabilities can be designed and implemented.
The business value of the application itself is the primary driver in determining the amount of investment that senior management is willing to make to reach any arbitrary RTO and RPO figures. This business value may be measured in local currency if the application supports revenue. However, the loss of an application during a disaster may harm the organization’s reputation. Again, management will have to make a decision on how much it will be willing to invest in DR capabilities that bring RTO and RPO figures down to acceptable levels. Figure 5-32 illustrates these relationships.
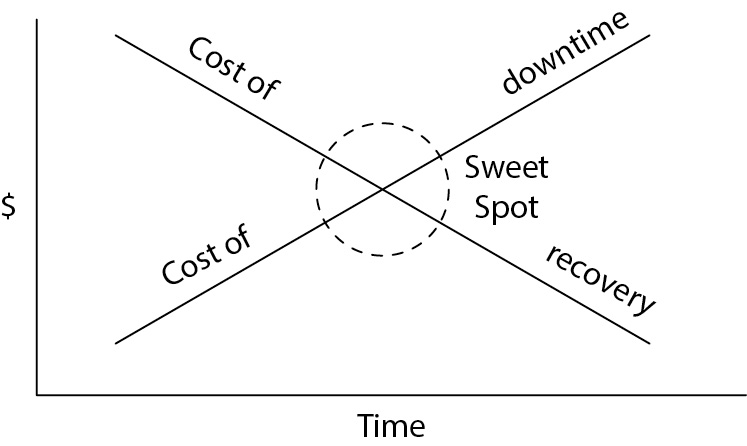
Figure 5-32 Aim for the sweet spot and balance the costs of downtime and recovery.
Developing Recovery Strategies
When management has chosen specific RPO and RTO targets for a given system or process, the BCP project team can roll up its sleeves and devise some ways to meet these targets. This section discusses the technologies and logistics associated with various recovery strategies. This will help the project team to decide which types of strategies are best suited for their organization.
Developing recovery strategies to meet specific recovery targets is an iterative process. The project team will develop a strategy to reach specific targets for a specific cost; senior management could well decide that the cost is too high and they are willing to increase RPO and/or RTO targets accordingly. Similarly, the project team could also discover that it is less costly to achieve specific RPO and RTO targets, and management could respond by lowering those targets. This is illustrated in Figure 5-33.
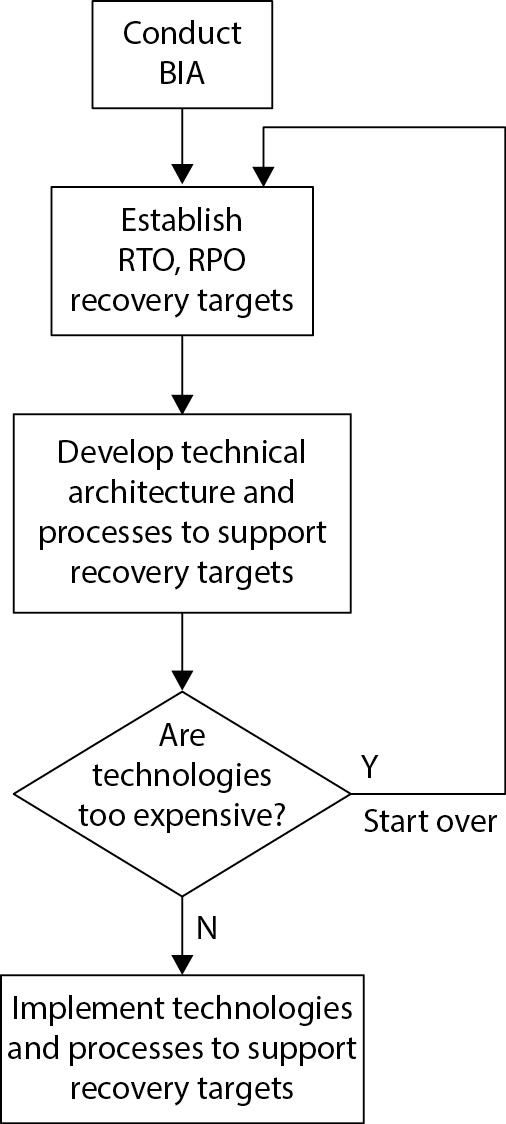
Figure 5-33 Recovery objective development flowchart
Site Recovery Options
In a worst-case disaster scenario, the site where information systems reside is partially or completely destroyed. In most cases, the organization cannot afford to wait for the damaged or destroyed facility to be restored, as this could take weeks or months. If an organization can take that long to recover an application, you’d have to wonder whether it is needed at all. The assumption has got to be that in a disaster scenario, critical applications will be recovered in another location. This other location is called a recovery site. There are two dimensions to the process of choosing a recovery site: the first is the speed at which the application will be recovered at the recovery site; the second is the location of the recovery site itself. Both are discussed here.
As you might expect, speed costs. If a system is to be recovered within a few minutes or hours, the costs will be much higher than if the system can be recovered in five days.
Various types of facilities are available for rapid or not-too-rapid recovery. These facilities are called hot sites, warm sites, and cold sites. As the names might suggest, hot sites permit rapid recovery, while cold sites provide a much slower recovery. The costs associated with these are somewhat proportional as well, as illustrated in Table 5-16.

Table 5-16 Relative Costs of Recovery Sites
NOTE
The use of a private or public cloud, although not explicitly included in Table 5-16, offers varying degrees of recovery site readiness that can be established in the cloud, which includes both hot and warm sites.
The details about each type of site are discussed in the remainder of this section.
Hot Sites
A hot site is an alternate processing center where backup systems are already running in some state of near-readiness to assume production workload. The systems at a hot site most likely have application software and database management software already loaded and running, perhaps even at the same patch levels as the systems in the primary processing center.
A hot site is the best choice for systems whose RTO targets range from zero to several hours, perhaps as long as 24 hours.
A hot site may consist of infrastructure in a private or public cloud, or leased rack space (or even a cage for larger installations) at a colocation center. If the organization has its own processing centers, then a hot site for a given system would consist of the required rack space to house the recovery systems. Recovery servers will be installed and running, with the same version and patch level for the operating system, database management system (if used), and application software.
Systems at a hot site require the same level of administration and maintenance as the primary systems. When patches or configuration changes are made to primary systems, they should be made to hot-site systems at the same time or very shortly afterward.
Because systems at a hot site need to be at or very near a state of readiness, a strategy needs to be developed regarding a method for keeping the data on hot standby systems current. This is discussed in detail in the later section “Recovery and Resilience Technologies.”
Systems at a hot site should have full network connectivity. A method for quickly directing network traffic toward the recovery servers needs to be worked out in advance so that a switchover can be accomplished. This is also discussed in the “Recovery and Resilience Technologies” section.
When setting up a hot site, the organization will need to send one or more technical staff members to the site to set up systems. But once the systems are operating, much or all of the system- and database-level administration can be performed remotely. However, in a disaster scenario, the organization may need to send the administrative staff to the site for day-to-day management of the systems. This means that workspace for these personnel needs to be identified so that they can perform their duties during the recovery operation.
NOTE
Hot-site planning needs to consider work (desk) space for on-site personnel. Some colocation centers provide limited work areas, but these areas are often shared and often have little privacy for phone discussions. Also, transportation, hotel, and dining accommodations need to be arranged, possibly in advance, if the hot site is in a different city from the primary site.
Warm Sites
A warm site is an alternate processing center where recovery systems are present, but at a lower state of readiness than recovery systems at a hot site. For example, while the same version of the operating system may be running on the warm site system, it may be a few patch levels behind primary systems. The same could be said about the versions and patch levels of database management systems (if used) and application software: they may be present, but they’re not as up-to-date as they are on the primary systems. Like a hot site, a warm site can be implemented in a private or public cloud, a colocation center, or an organization’s own alternate processing center.
A warm site is appropriate for an organization whose RTO figures range from roughly one to seven days. In a disaster scenario, recovery teams would travel to the warm site and work to get the recovery systems to a state of production readiness and to get systems up-to-date with patches and configuration changes to bring the systems into a state of complete readiness.
A warm site is also used when the organization is willing to take the time necessary to recover data from tape or other backup media. Depending upon the size of the database(s), this recovery task can take several hours to a few days.
The primary advantage of a warm site is that its costs are lower than for a hot site, particularly in the effort required to keep the recovery system up-to-date. The site may not require expensive data replication technology, but instead data can be recovered from backup media.
Cold Sites
A cold site is an alternate processing center where the degree of readiness for recovery systems is low. At the very least, a cold site is nothing more than an empty rack or allocated space on a computer room floor. It’s just an address in someone’s data center or colocation site where computers can be set up and used at some future date. A cold site could also exist in the form of an enterprise account established at a public cloud organization, but where no infrastructure has been created and configured.
Often, there is little or no equipment at a cold site. When a disaster or other highly disruptive event occurs in which the outage is expected to exceed seven to fourteen days, the organization will order computers from a manufacturer or perhaps have computers shipped from some other business location, so that they can arrive at the cold site soon after the disaster event has begun. Then personnel would travel to the site and set up the computers, operating systems, databases, network equipment, and so on, and get applications running within several days.
The advantage of a cold site is its low cost. The main disadvantage is the cost, time, and effort required to bring it to operational readiness in a short period. But for some organizations, a cold site is exactly what is needed.
Table 5-17 shows a comparison of hot, warm, and cold recovery sites and a few characteristics of each.
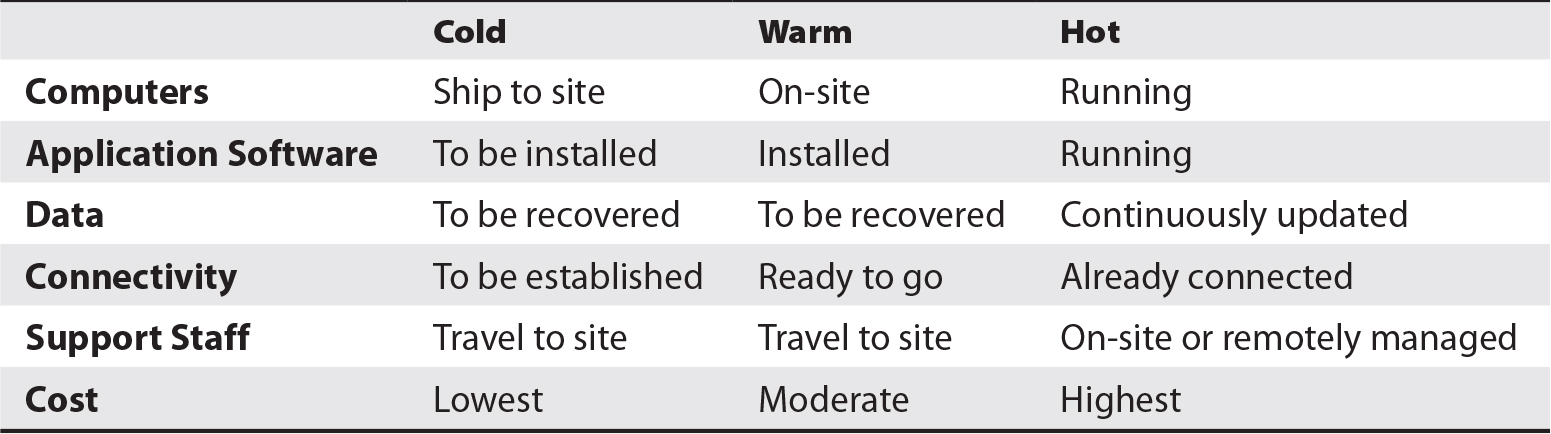
Table 5-17 Detailed Comparison of Cold, Warm, and Hot Sites
Mobile Sites
A mobile site is a portable recovery center that can be delivered to almost any location in the world. A viable alternative to a fixed location recovery site, a mobile site can be transported by semi-truck and may even have its own generator, communications, and cooling capabilities.
APC and SunGard have mobile sites installed in semi-truck trailers. Oracle has mobile sites that can include a configurable selection of servers and workstations, all housed in shipping containers that can be shipped by truck, rail, ship, or air to any location in the world.
Cloud Sites
Organizations are increasingly using cloud hosting services as their recovery sites. Such sites charge for the utilization of servers and devices in virtual environments. Hence, capital costs for recovery sites is near zero and operational costs come into play as recovery sites are used.
As organizations become accustomed to building recovery sites in the cloud, they are with increasing frequency moving their primary processing sites to the cloud as well.
Reciprocal Sites
A reciprocal recovery site is a data center that is operated by another company. Two or more organizations with similar processing needs will draw up a legal contract that obligates one or more of the organizations to house another party’s systems temporarily in the event of a disaster.
Often, a reciprocal agreement pledges not only floor space in a data center, but also the use of the reciprocal partner’s computer system. This type of arrangement is less common, but it is used by organizations that use mainframe computers and other high-cost systems.
NOTE
With the wide use of public cloud and Internet colocation centers, reciprocal sites have fallen out of favor. Still, they may be ideal for organizations with mainframe computers that are otherwise too expensive to deploy to a cold or warm site.
Geographic Site Selection
An important factor in the process of recovery site selection is the location of the recovery site. The distance between the main processing site and the recovery site is vital and may figure heavily into the viability and success of a recovery operation.
A recovery site should not be located in the same geographic region as the primary site. A recovery site in the same region may be involved in the same regional disaster as the primary site and may be unavailable for use or be suffering from the same problems present at the primary site.
NOTE
“Geographic region” refers to a location that will likely experience the effects of the same regional disaster that affects the primary site. No arbitrarily chosen distance (such as 100 miles) guarantees sufficient separation. In some locales, 50 miles is plenty of distance; in other places, 300 miles is too close—it all depends on the nature of disasters that are likely to occur in these areas. Information on regional disasters should be available from local disaster preparedness authorities or from local disaster recovery experts.
Considerations When Using Third-Party Disaster Recovery Sites
Since most organizations cannot afford to implement their own secondary processing site, the only other option is to use a disaster recovery site that is owned by a third party. This could be a colocation center, a disaster services center, or a public cloud provider. An organization considering such a site needs to ensure that its services contract addresses the following:
- Disaster definition
The definition of disaster needs to be broad enough to meet the organization’s requirements. - Equipment configuration
IT equipment must be configured as needed to support critical applications during a disaster. - Availability of equipment during a disaster
IT equipment needs to be available during a disaster. In the case of disaster service providers, the organization needs to know how the disaster service provider will allocate equipment if many of its customers suffer a disaster simultaneously. - Customer priorities
The organization needs to know whether the disaster services provider has any customers (government or military, for example) whose priorities may exceed their own. - Data communications
There must be sufficient bandwidth and capacity for the organization plus other customers who may be operating at the disaster provider’s center at the same time. - Testing
The organization needs to know what testing it is permitted to perform on the service provider’s systems so that the ability to recover from a disaster can be tested in advance. - Right to audit
The organization should have a “right to audit” clause in its contract so that it can verity the presence and effectiveness of all key controls in place at the recovery facility. Note, however, that a right to audit is generally not an option for public cloud providers. - Security and environmental controls
The organization needs to know what security and environmental controls are in place at the disaster recovery facility. - Acquiring Additional Hardware
Many organizations elect to acquire their own server, storage, and network hardware for disaster recovery purposes. How an organization goes about acquiring hardware depends on its high-level recovery strategy: - Cold site
Warm site- An organization probably will need to purchase hardware in advance of the disaster, but it may be able to purchase hardware when the disaster occurs. The choice will depend on the recovery time objective.
- Hot site
An organization will need to purchase its recovery hardware in advance of the disaster. - Cloud
An organization will not need to purchase hardware, as this is provided by the cloud infrastructure provider.
Pros and cons to these strategies are listed in Table 5-18. Warm site strategy is not listed, since an organization could purchase hardware either in advance of the disaster or when it occurs. But because cold, hot, and cloud sites are deterministic, they are included in the table.
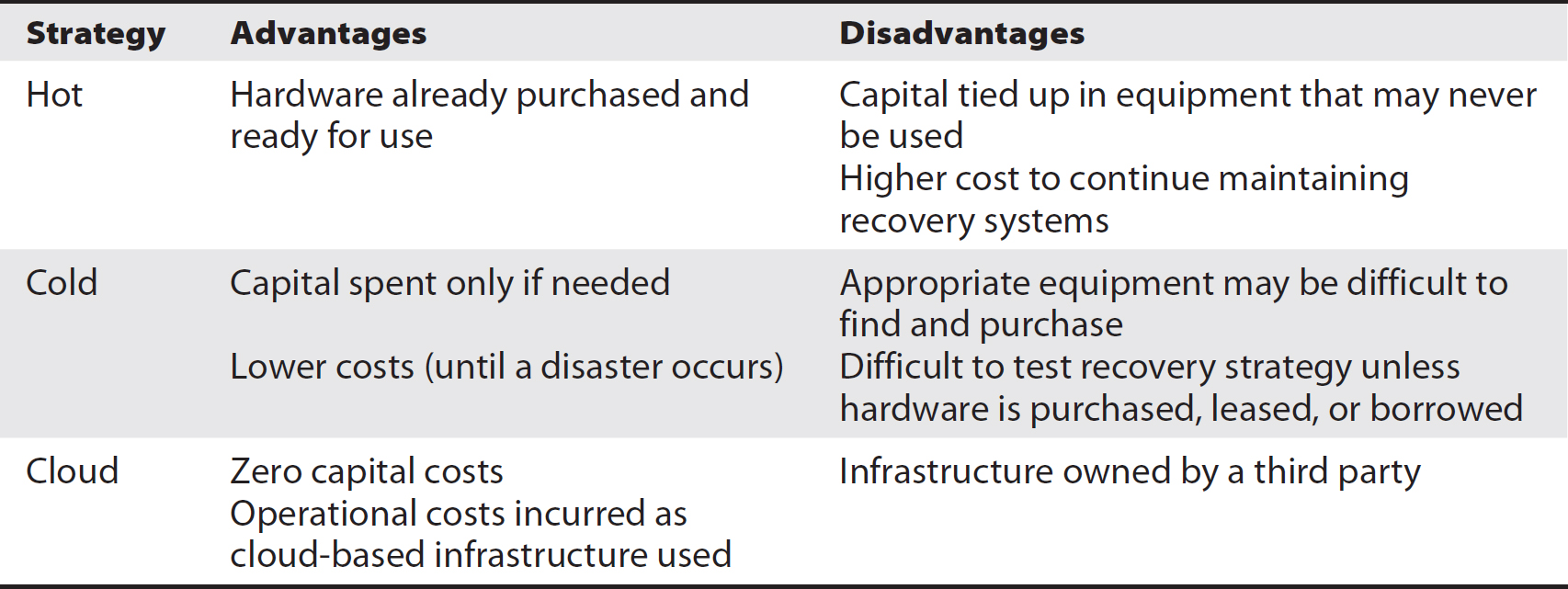
Table 5-18 Hardware Acquisition Pros and Cons for Hot, Cold, and Cloud Recovery Sites
The main reasons for choosing a cloud hosting provider are to eliminate capital costs and to rapidly develop and deploy virtual infrastructure. The cloud hosting provider provides all hardware and charges organizations when the hardware is used.
Dual-Purpose Infrastructure
The primary business reason for not choosing a hot site is the high capital cost required to purchase disaster recovery equipment that may never be used. One way around this obstacle is to put those recovery systems to work every day. For example, recovery systems could be used for development or testing of the same applications that are used in production. This way, systems that are purchased for recovery purposes are being well utilized for other purposes, and they’ll be ready in case a disaster occurs.
When a disaster occurs, the organization will be less concerned about development and testing and more concerned about keeping critical production applications running. It will be a small sacrifice to forgo development or testing (or whatever low-criticality functions are using the DR hardware) during a disaster.
Recovery and Resilience Technologies
Once recovery targets have been established, the next major task is to survey and select technologies to enable recovery time and recovery point objectives to be met. Several important factors when considering each technology are
- Does the technology help the information system achieve the RTO and RPO targets?
- Does the cost of the technology meet or exceed budget constraints?
- Can the technology be used to benefit other information systems (thereby lowering the cost for each system)?
- Does the technology fit well into the organization’s current IT operations?
- Will operations staff require specialized training on the technology used for recovery?
- Does the technology contribute to the simplicity of the overall IT architecture, or does it complicate it unnecessarily?
These questions are designed to help determine whether a specific technology is a good fit, from a technology perspective as well as from process and operational perspectives.
RAID
Redundant Array of Independent Disks (RAID) is a family of technologies used to improve the reliability, performance, or size of disk-based storage systems. From a disaster recovery or systems resilience perspective, the feature of RAID that is of particular interest is the reliability. RAID is used to create virtual disk volumes over an array (pun intended) of disk storage devices and can be configured so that the failure of any individual disk drive in the array will not affect the availability of data on the disk array.
RAID is usually implemented on a hardware device called a disk array, which is a chassis in which several hard disks can be installed and connected to a server. The individual disk drives can usually be “hot swapped” in the chassis while the array is still operating. When the array is configured with RAID, a failure of a single disk drive will have no effect on the disk array’s availability to the server to which it is connected. A system operator can be alerted to the disk’s failure, and the defective disk drive can be removed and replaced while the array is still fully operational.
There are several options, or levels, for RAID configuration:
- RAID-0
This is known as a striped volume, where a disk volume splits data evenly across two or more disks to improve performance. - RAID-1
This creates a mirror, where data written to one disk in the array is also written to a second disk in the array. RAID-1 makes the volume more reliable through the preservation of data, even when one disk in the array fails. - RAID-4
This level of RAID employs data striping at the block level by adding a dedicated parity disk. The parity disk permits the rebuilding of data in the event one of the other disks fails. - RAID-5
This is similar to RAID-4 block-level striping, except that the parity data is distributed evenly across all of the disks instead of dedicated on one disk. Like RAID-4, RAID-5 allows for the failure of one disk without losing information. - RAID-6
This is an extension of RAID-5, where two parity blocks are used instead of a single parity block. The advantage of RAID-6 is that it can withstand the failure of any two disk drives in the array, instead of a single disk, as is the case with RAID-5.
NOTE
Several nonstandard RAID levels have been developed by various hardware and software companies. Some of these are extensions of RAID standards, while others are entirely different.
Storage systems are hardware devices that are entirely separate from servers—their only purpose is to store a large amount of data and to be highly reliable through the use of redundant components and the use of one or more RAID levels. Storage systems generally come in two forms:
- Storage area network (SAN)
This stand-alone storage system can be configured to contain several virtual volumes and to connect to several servers through fiber optic cables. The servers’ operating systems will often consider this storage to be “local,” as though it consisted of one or more hard disks present in the server’s own chassis. - Network attached storage (NAS)
This stand-alone storage system contains one or more virtual volumes. Servers access these volumes over the network using the NFS or Server Message Block/Common Internet File System (SMB/CIFS) protocols, common on Unix and Windows operating systems, respectively.
NOTE
In public cloud environments, the physical implementation of storage is an abstraction.
- Replication
Replication is an activity whereby data written to a storage system is also copied over a network to another storage system. The result is the presence of up-to-date data that exists on two or more storage systems, each of which could be located in a different geographic region.
Replication can be handled in several ways and at different levels in the technology stack:
- Disk storage system
Data-write operations that take place in a disk storage system (such as a SAN or NAS) can be transmitted over a network to another disk storage system, where the same data will be written to the other system. - Operating system
The operating system can control replication so that updates to a particular file system can be transmitted to another server where those updates will be applied locally on that other server. - Database management system
The database management system (DBMS) can manage replication by sending transactions to a DBMS on another server. - Transaction management system
The transaction management system (TMS) can manage replication by sending transactions to a counterpart TMS located elsewhere. - Application
The application can write its transactions to two different storage systems. This method is not often used. - Virtualization
Virtual machine images can be replicated to recovery sites to speed the recovery of applications.
Replication can take place from one system to another system in primary-backup replication. This is the typical setup when data on an application server is sent to a distant storage system for data recovery or disaster recovery purposes.
Replication can also be bidirectional, between two active servers, called multiprimary or multimaster. This method is more complicated, because simultaneous transactions on different servers could conflict with one another (such as two reservation agents trying to book two passengers in the same seat on an airline flight). Some form of concurrent transaction control would be required, such as a distributed lock manager.
In terms of the speed and integrity of replicated information, there are two types of replication:
- Synchronous replication
Writing data to a local and to a remote storage system is performed as a single operation, guaranteeing that data on the remote storage system is identical to data on the local storage system. Synchronous replication incurs a performance penalty, as the speed of the entire transaction is slowed to the rate of the remote transaction. - Asynchronous replication
Writing data to the remote storage system is not kept in sync with updates on the local storage system. Instead, there may be a time lag, and you have no guarantee that data on the remote system is identical to data on the local storage system. However, performance is improved, because transactions are considered complete when they have been written to the local storage system only. Bursts of local updates to data will take a finite period to replicate to the remote server, subject to the available bandwidth of the network connection between the local and remote storage systems.
NOTE
Replication is often used for applications where the RTO is smaller than the time necessary to recover data from backup media. For example, if a critical application’s RTO is established to be two hours, then recovery from backup tape is probably not a viable option, even if backups are performed every two hours. While more expensive than recovery from backup media, replication ensures that up-to-date information is present on a remote storage system that can be brought online in a short period.
Server Clusters
A cluster is a collection of two or more servers that appears as a single server resource. Clusters are often the technology of choice for applications that require a high degree of availability and a very small RTO, measured in minutes.
When an application is implemented on a cluster, even if one of the servers in the cluster fails, the other server (or servers) in the cluster will continue to run the application, usually with no user awareness that a failure occurred.
There are two typical configurations for clusters, active-active and active-passive. In active-active mode, all servers in the cluster are running and servicing application requests. This is often used in high-volume applications where many servers are required to service the application workload.
In active-passive mode, one or more servers in the cluster are active and servicing application requests, while one or more servers in the cluster are in “standby” mode; they can service application requests but won’t do so unless one of the active servers fails or goes offline for any reason. When an active server goes offline and a standby server takes over, this event is called a failover.
A typical server cluster architecture is shown in Figure 5-34.
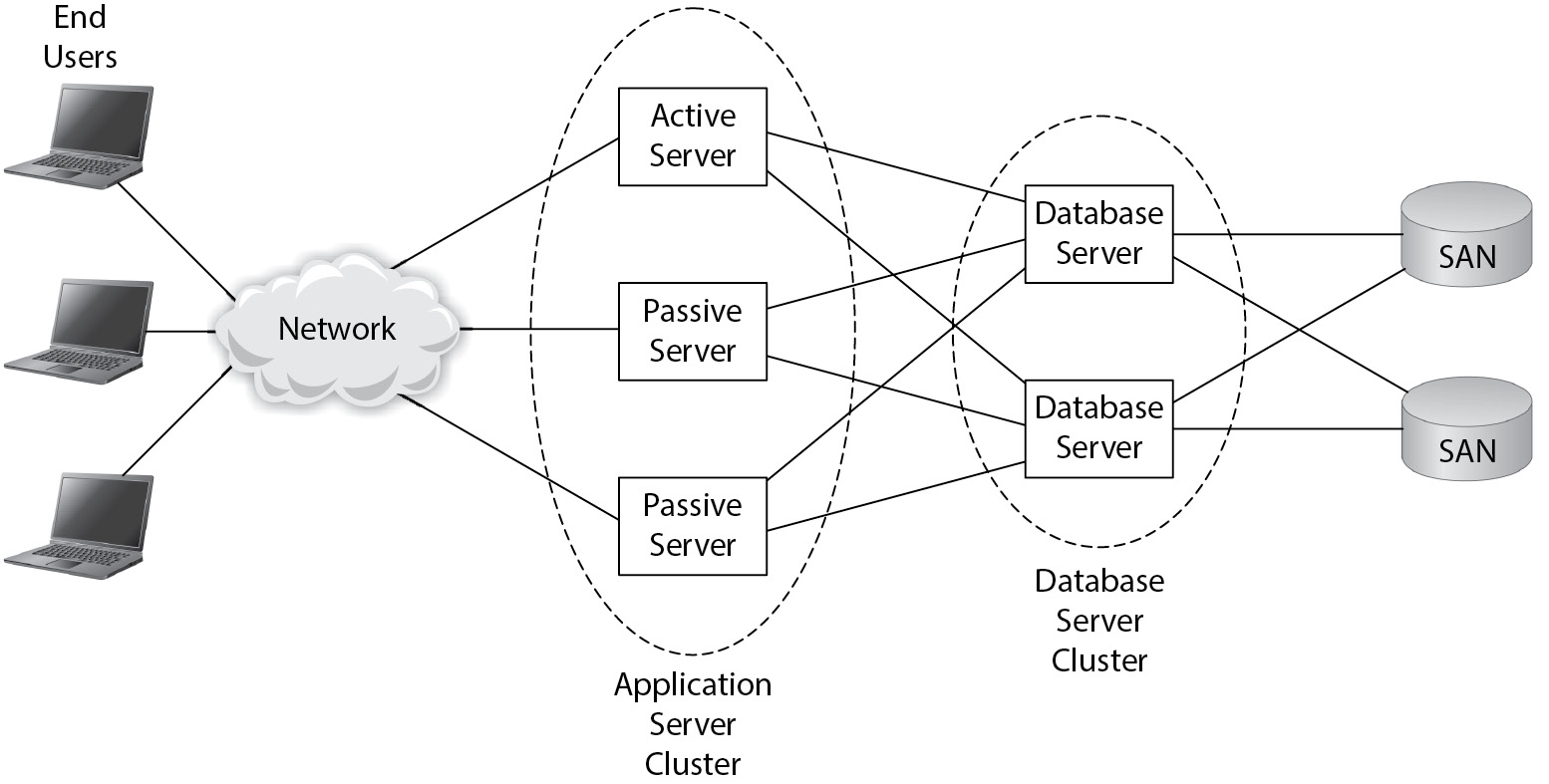
Figure 5-34 Application and database server clusters
A server cluster is typically implemented in a single physical location such as a data center. However, a cluster can also be implemented where great distances separate the servers in the cluster. This type of cluster is called a geographic cluster, or geo-cluster. Servers in a geo-cluster are connected through a WAN connection. A typical geographic cluster architecture is shown in Figure 5-35.
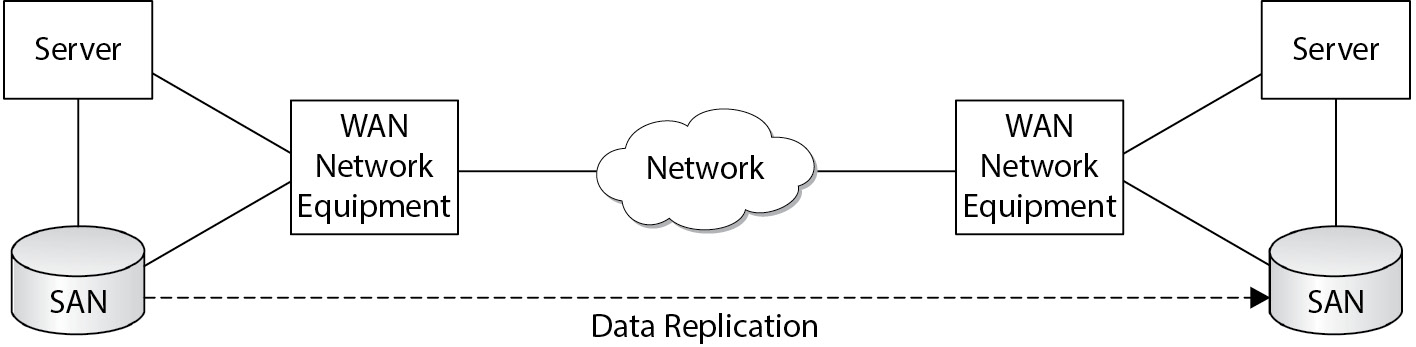
Figure 5-35 Geographic cluster with data replication
Network Connectivity and Services
An overall application environment that is required to be resilient and have recoverability must have those characteristics present within the network that supports it. A highly resilient application architecture that includes clustering and replication would be of little value if it had only a single network connection that was a single point of failure.
An application that requires high availability and resilience may require one or more of the following in the supporting network:
- Redundant network connections
These may include multiple network adapters on a server, but also a fully redundant network architecture with multiple switches, routers, load balancers, and firewalls. They could also include physically diverse network provider connections, where network service provider feeds enter the building from two different directions. - Redundant network services
Certain network services are vital to the continued operation of applications, such as DNS (the function of translating server names like www.mcgraw-hill.com into an IP address), NTP (used to synchronize computer time clocks), SMTP, SNMP, authentication services, and perhaps others. These services are usually operated on servers that may require clustering and/or replication of their own so that the application will be able to continue functioning in the event of a disaster.
Developing Recovery Plans
A DRP effort starts with the initial phases of the BCP project: the business impact analysis (BIA) and criticality analysis (CA) lead to the establishment of recovery objectives that determine how quickly critical business processes need to be back up and running.
With this information, the DR team can determine what additional data processing equipment is needed (if any) and establish a roadmap for acquiring that equipment.
The other major component in the DR project is the development of recovery plans. These are the process and procedure documents that will be vital when a disaster has been declared. These processes and procedures will instruct response personnel how to establish and operate business processes and IT systems after a disaster has occurred. It’s not enough to have all of the technology ready if personnel don’t know what to do.
Most DR plans are going to have common components:
- Disaster declaration procedure
This needs to include criteria for how a disaster is determined and who has the authority to declare a disaster. - Roles and responsibilities
DR plans need to specify what activities need to be performed and specify which persons or teams are best equipped to perform them. - Emergency contact lists
Response personnel need contact information for other personnel so that they may establish and maintain communications as the disaster unfolds and recovery operations begin. These contact lists should include several different ways of contacting personnel, since some disasters have an adverse impact on regional telecommunications infrastructure. - System recovery procedures
These are the detailed steps for getting recovery systems up and running. These procedures will include a lot of detail describing obtaining data, configuring servers and network devices, confirming that the application and business information is healthy, and starting business applications. - System operations procedures
These are detailed steps for operating critical IT systems while they are in recovery mode. These detailed procedures are needed because the systems in recovery mode may need to be operated differently from their production counterparts; further, they may need to be operated by personnel who have not been doing this before. - System restoration procedures
These are the detailed steps to restore IT operations back to the original production systems.
NOTE
Business continuity and disaster recovery plans work together to get critical business functions operating again after a disaster. Because of this, BC and DR teams need to work closely when developing their respective response procedures to make sure that all activities are covered, but without unnecessary overlap (or gaps).
DR plans need to take into account the likely disaster scenarios that may occur to an organization. Understanding these scenarios can help the DR team take a more pragmatic approach when creating response procedures. The added benefit is that not all disasters result in the entire loss of a computing facility. Most are more limited in their scope, although all of them can result in a complete inability to continue operations. Some of these scenarios are
- Complete loss of network connectivity
- Sustained electric power outage
- Loss of a key system (this could be a server, storage system, or network device)
- Extensive data corruption or data loss
These scenarios are probably more likely to occur than a catastrophe such as a major earthquake or hurricane (depending on where your data center is located).
Data Backup and Recovery
Disasters and other disruptive events can damage information and information systems. It’s essential that fresh copies of this information exist elsewhere in a form that enables IT personnel to load this information easily into alternative systems so that processing can resume as quickly as possible.
CAUTION
Testing backups is important; testing recoverability is critical. In other words, performing backups is only valuable to the extent that backed up data can be recovered at a future time.
- Backup to Tape and Other Media
In organizations still utilizing their own IT infrastructure, tape backup is just about as ubiquitous as power cords. From a DR perspective, however, the issue probably is not whether the organization has tape backup, but whether its current backup capabilities are adequate in the context of disaster recovery. An organization’s backup capability may need to be upgraded if- The current backup system is difficult to manage.
- Whole-system restoration takes too long.
- The system lacks flexibility with regard to DR (for instance, how difficult it would be to recover information onto a different type of system).
- The technology is old or outdated.
- Confidence in the backup technology is low.
Many organizations may consider tape backup as a means for restoring files or databases when errors have occurred, and they may have confidence in their backup system for that purpose. However, the organization may have somewhat less confidence in their backup system and its ability to recover all of their critical systems accurately and in a timely manner.
While tape has been the default medium since the 1960s, using hard drives as backup media is growing in popularity: hard disk transfer rates are far higher, and disk is a random-access medium, whereas tape is a sequential-access medium. A virtual tape library (VTL) is a type of data storage technology that sets up a disk-based storage system with the appearance of tape storage, permitting existing backup software to continue to back up data to “tape,” which is really just more disk storage.
E-vaulting is another viable option for system backup. E-vaulting permits organizations to back up their systems and data to an off-site location, which could be a storage system in another data center or a third-party service provider. This accomplishes two important objectives: reliable backup and off-site storage of backup data.
- Backup Schemes
- There are three main schemes for backing up data: full, incremental, and differential backups.
- Full backup
This is a complete copy of a data set. - Incremental backup
This is a copy of all data that has changed since the last full or incremental backup. - Differential backup
This is a copy of all data that has changed since the last full backup.
The precise nature of the data to be backed up will determine which combination of backup schemes is appropriate for the organization. Some of the considerations for choosing an overall scheme include
- Criticality of the data set
- Size of the data set
- Frequency of change of the data set
- Performance requirements and the impact of backup jobs
- Recovery requirements
An organization that is creating a backup scheme usually starts with the most common scheme, which is a full backup once per week and an incremental or differential backup every day. However, as stated previously, various factors will influence the design of the final backup scheme, such as the following:
- A small data set could be backed up more than once a week, while an especially large data set might be backed up less often.
- A more rapid recovery requirement may induce the organization to perform differential backups instead of incremental backups.
- If a full backup takes a long time to complete, it should probably be performed during times of lower demand or system utilization.
Backup Media Rotation
Organizations will typically want to retain backup media for as long as possible in order to provide a greater range of choices for data recovery. However, the desire to maintain a large library of backup media will be countered by the high cost of media and the space required to store it. And although legal or statutory requirements may dictate that backup media be kept for some minimum period, the organization may be able to find creative ways to comply with such requirements without retaining several generations of such media.
Some example backup media rotation schemes are discussed here.
- First In, First Out (FIFO)
- In this scheme, there is no specific requirement for retaining any backup media for long periods (such as one year or more). The method in the FIFO rotation scheme specifies that the oldest available backup tape is the next one to be used.
The advantage of this scheme is its simplicity. However, there is a significant disadvantage: any corruption of backed up data needs to be discovered quickly (within the period of media rotation), or else no valid set of data can be recovered. Hence, only low-criticality data without any lengthy retention requirements should be backed up using this scheme.
Grandfather-Father-Son
The most common backup media rotation scheme, grandfather-father-son creates a hierarchical set of backup media that provides for greater retention of backed up data that is still economically feasible.
In the most common form of this scheme, full backups are performed once per week and incremental or differential backups are performed daily.
Daily backup tapes used on Monday are not used again until the following Monday. Backup tapes used on Tuesday, Wednesday, Thursday, Friday, and Saturday are handled in the same way.
Full backup tapes created on Sunday are kept longer. Tapes used on the first Sunday of the month are not used again until the first Sunday of the following month. Similarly, tapes used on the second Sunday are not reused until the second Sunday of the following month, and so on for each week’s tapes for Sunday.
For even longer retention, for example, tapes created on the first Sunday of the first month of each calendar quarter can be retained until the first Sunday of the first month of the next quarter. Backup media can be kept for even longer if needed.
Towers of Hanoi
The Towers of Hanoi backup media retention scheme is complex but results in a more efficient scheme for producing a lengthier retention of some backups. Patterned after the Towers of Hanoi puzzle, the scheme is most easily understood visually, as shown in Figure 5-36 in a five-level scheme.
Figure 5-36 Towers of Hanoi backup media rotation scheme
Backup Media Storage
Backup media that remains in the same location as backed up systems is adequate for data recovery purposes but completely inadequate for disaster recovery purposes: any event that physically damages information systems (such as fire, smoke, flood, hazardous chemical spill, and so on) is also likely to damage backup media. To provide disaster recovery protection, backup media must be stored off-site in a secure location. Selection of this storage location is as important as the selection of a primary business location: in the event of a disaster, the survival of the organization may depend upon the protection measures in place at the off-site storage location.
EXAM TIP
CISA exam questions relating to off-site backups may include details for safeguarding data during transport and storage, mechanisms for access during restoration procedures, media aging and retention, or other details that may aid you during the exam. Watch for question details involving the type of media, geo-locality (distance, shared disaster spectrum [such as a shared coastline], and so on) of the off-site storage area and the primary site, or access controls during transport and at the storage site, including environmental controls and security safeguards.
The criteria for selection of an off-site media storage facility are similar to the criteria for selection of a hot/warm/cold/cloud recovery site discussed earlier in this chapter. If a media storage location is too close to the primary processing site, it is more likely to be involved in the same regional disaster, which could result in damage to backup media. However, if the media storage location is too far away, it might take too long for a delivery of backup media, which would result in a recovery operation that runs unacceptably long.
Another location consideration is the proximity of the media storage location and the hot/warm/cold recovery site. If a hot site is being used, chances are there is some other near-real-time means (such as replication) for data to get to the hot site. But a warm or cold site may be relying on the arrival of backup media from the off-site media storage facility, so it might make sense for the off-site facility to be near the recovery site. If the public cloud is used as an alternate recovery site, then a different means than tape backup will need to be used to get data to the public cloud, such as e-vaulting or replication.
An important factor when considering off-site media storage is the method of delivery to and from the storage location. Chances are that the backup media is being transported by a courier or a shipping company. It is vital that the backup media arrive safely and intact, and that the opportunities for interception or loss be reduced as much as possible. Not only can a lost backup tape make recovery more difficult, but it can also cause an embarrassing security incident if knowledge of the loss were to become public. From a confidentiality/integrity perspective, encryption of backup tapes is a good idea, although this digresses somewhat from disaster recovery (concerned primarily with availability).
NOTE
The requirements for off-site storage are a little less critical than those for a hot/warm/cold recovery site. All you have to do is be able to get your backup media out of that facility. This can occur even if there is a regional power outage, for instance.
Backup media that must be kept on-site should be stored in locked cabinets or storerooms that are separate from the rooms where backups are performed. This will help to preserve backup media if a relatively small fire (or similar event) breaks out in the room containing computers that are backed up.
Backup Media Records and Destruction
To ensure the ability of restoring data from backup media, organizations need to have meticulous records that list all backup volumes in place, where they are located, and which data elements are backed up on them. Without these records, it may prove impossible for an organization to recover data from its backup media library.
Protecting Sensitive Backup Media with Encryption
Information security and data privacy laws are expanding data protection requirements by requiring encryption of backup media in many cases. This is a sensible safeguard, especially for organizations that utilize off-site backup media storage. There is a risk of loss of backup media when it is being transported back and forth from an organization’s primary data center and the backup media off-site storage facility.
Laws and regulations may specify maximum periods that specific information may be retained. Organizations need to have good records management that helps them track which business records are on which backup media volumes. When it is time for an organization to stop retaining a specific set of data, those responsible for the backup media library need to identify the backup volumes that can be recycled. If the data on the backup media is sensitive, the backup volume may need to be erased prior to use. Any backup media that is being discarded needs to be destroyed so that no other party can possibly recover data on the volume. Records of this destruction need to be kept.
Testing Disaster Response Plans
Disaster response plans need to be accurate and complete if they are going to result in a successful recovery. It is recommended that recovery and response plans be thoroughly tested.
The types of recovery tests are
- Document review
- Walkthrough
- Simulation
- Parallel test
- Cutover test
These test methods are described in detail earlier in this chapter.
Auditing IT Infrastructure and Operations
Auditing infrastructure and operations requires considerable technical expertise in order for the auditor to fully understand the technology that he or she is examining. If an auditor lacks technical knowledge, interviewed subjects may offer explanations that can evade vital facts that the auditor should be aware of. Auditors need to be familiar with hardware, operating systems, database management systems, networks, IT operations, monitoring, and DRP.
Auditing Information Systems Hardware
Auditing hardware requires attention to several key factors and activities, including
- Standards
The auditor should examine hardware procurement standards that specify the types of systems the organization uses. These standards should be periodically reviewed and updated. A sample of recent purchases should be examined to determine whether standards are being followed. The scope of this activity should include servers, workstations, network devices, and other hardware used by IT. - Maintenance
Maintenance requirements and records should be examined to determine whether any required maintenance is being performed. If service contracts are used, these should be examined to ensure that all critical systems are covered. - Capacity
The auditor should examine capacity management and planning processes, procedures, and records. This will help the auditor to understand whether the organization monitors its systems’ capacity and does any planning for future expansion. - Change management
Change management processes and records should be examined to determine whether hardware changes are being performed in a life cycle process. All changes that are made should be requested and reviewed in advance, approved by management, and recorded. - Configuration management
The auditor should examine configuration management records to determine whether the IT organization is tracking the configuration of its systems in a centralized and systematic manner.
NOTE
Audits of these aspects of hardware are applicable to public cloud environments also.
Auditing Operating Systems
Auditing operating systems, whether on-premises or cloud-based, requires attention to many different details, including
- Standards
The auditor should examine written standards to determine whether they are complete and up-to-date. He or she should then examine a sampling of servers and workstations to ensure that they comply with the organization’s written standards. - Maintenance and support
Business records should be examined to see whether the operating systems running on servers or workstations are covered by maintenance or support contracts. - Change management
The auditor should examine operating system change management processes and records to determine whether changes are being performed in a systematic manner. All changes that are made should be requested and reviewed in advance, approved by management, and recorded. - Configuration management
Operating systems are enormously complex; in all but the smallest organizations, configuration management tools should be used to ensure consistency of configuration among systems. The auditor should examine configuration management processes, tools, and recordkeeping. - Security management
The auditor should examine security configurations on a sample of servers and workstations and determine whether they are “hardened” or resemble manufacturer default configurations. This determination should be made in light of the relative risk of various selected systems. An examination should include patch management and administrative access.
Auditing File Systems
File systems containing business information must be examined to ensure that they are properly configured. An examination should include
- Capacity
File systems must have adequate capacity to store all of the currently required information, plus room for future growth. The auditor should examine any file storage capacity management tools, processes, and records. - Access control
Files and directories should be accessible only by personnel with a business need. Records of access requests should be examined to see if they correspond to the access permissions observed.
Auditing Database Management Systems
DBMSs are as complex as operating systems. This complexity requires considerable auditor scrutiny in several areas, including
- Configuration management
The configuration of DBMSs should be centrally controlled and tracked in larger organizations to ensure consistency among systems. Individual DBMSs and configuration management records should be compared. - Change management
Databases are used to store not only information, but also software in many cases. The auditor should examine DBMS change management processes and records to determine whether changes are being performed in a consistent, systematic manner. All changes that are made should be requested and reviewed in advance, approved by management, tested, implemented, and recorded. Changes to software should be examined in coordination with an audit of the organization’s software development life cycle. - Capacity management
The availability and integrity of supported business processes requires sufficient capacity in all underlying databases. The auditor should examine procedures and records related to capacity management to see whether management ensures sufficient capacity for business data. - Access management
Access controls determine which users and systems are able to access and update data. The auditor should examine access control configurations, access requests, and access logs.
Auditing Network Infrastructure
The IS auditor needs to perform a detailed study of the organization’s network infrastructure and underlying management processes. An auditor’s scrutiny should include
- Enterprise architecture
The auditor should examine enterprise architecture documents. There should be overall and detailed schematics and standards. - Network architecture
The auditor should examine network architecture documents. These should include schematics, topology and design, data flow, routing, and addressing. - Virtual architecture
The auditor should examine all aspects of network infrastructure that is implemented in public cloud environments. - Security architecture
Security architecture documents should be examined, including critical and sensitive data flows, network security zones, access control devices and systems, security countermeasures, intrusion detection and prevention systems, firewalls, screening routers, gateways, anti-malware, and security monitoring. - Standards
The auditor should examine standards documents and determine whether they are reasonable and current. Selected devices and equipment should be examined to see whether they conform to these standards. - Change management
All changes to network devices and services should be governed by a change management process. The auditor should review change management procedures and records and examine a sample of devices and systems to ensure that changes are being performed according to the change management policy. - Capacity management
The auditor should determine how the organization measures network capacity, whether capacity management procedures and records exist, and how capacity management affects network operations. - Configuration management
The auditor should determine whether any configuration management standards, procedures, and records exist and are used. He or she should examine the configuration of a sampling of devices to see whether configurations are consistent from device to device. - Administrative access management
Access management procedures, records, and configurations should be examined to see whether only authorized persons are able to access and manage network devices and services. - Network components
The auditor should examine several components and their configuration to determine how well the organization has constructed its network infrastructure to support business objectives. - Log management
The auditor should determine whether administrative activities performed on network devices and services are logged. He or she should examine the configuration of logs to see if they can be altered. The logs themselves should be examined to determine whether any unauthorized activities are taking place. - User access management
Often, network-based services provide organization-wide user access controls. The auditor should examine these centralized services to see whether they conform to written security standards. Examination should include user ID convention, password controls, inactivity locking, user account provisioning, user account termination, and password reset procedures.
Auditing Network Operating Controls
The IS auditor needs to examine network operations to determine whether the organization is operating its network effectively. Examinations should include
- Network operating procedures
The auditor should examine procedures for normal activities for all network devices and services. These activities will include login, startup, shutdown, upgrade, and configuration changes. - Restart procedures
Procedures for restarting the entire network (and portions of it for larger organizations) should exist and be tested periodically. A network restart would be needed in the event of a massive power failure, network failure, or significant upgrade. - Troubleshooting procedures
The auditor should examine network troubleshooting procedures for all significant network components. Procedures that are specific to the organization’s network help network engineers and analysts quickly locate problems and reduce downtime. - Security controls
Operational security controls should be examined, including administrator authentication, administrator access control, logging of administrator actions, protection of device configuration data, security configuration reviews, and protection of audit logs. - Change management
All changes to network components and services should follow a formal change management life cycle, including request, review, approval by management, testing in a separate environment, implementation, verification, and complete recordkeeping. The auditor should examine change management policy, procedures, and records.
Auditing IT Operations
Auditing IT operations involves examining the processes used to build, maintain, update, and repair computing hardware, operating systems, and network devices. Audits will cover processes, procedures, and records, as well as examinations of information systems.
Auditing Computer Operations
The auditor should examine computer operational processes, including
- System configuration standards
The auditor should examine configuration standards that specify the detailed configuration settings for each type of system that is used in the organization. - System build procedures
The auditor should examine the procedures used to install and configure the operating system. - System recovery procedures
The procedures that are used to recover systems from various types of failures should be examined. Usually, this will include reinstalling and configuring the operating system, restoring software and data from backup, and verifying system recovery. - System update procedures
The auditor should examine procedures used for making changes to systems, including configuration changes and component upgrades. - Patch management
The auditor should examine the procedures for receiving security advisories, risk analysis, and decisions regarding when new security patches should be implemented. Procedures should also include testing, implementation, and verification. - Daily tasks
Daily and weekly operating procedures for systems should be examined, which may include data backup, log review, log file cycling, review of performance logs, and system capacity checks. - Backup and replication
The auditor should examine procedures and records for file and database backup, backup verification, replication, recovery testing, backup media control and inventory, and off-site media storage. - Media control
Media control procedures should be examined, which includes backup media retirement procedures, disk media retirement procedures, media custody, and off-site storage. - Monitoring
Computer monitoring is discussed in detail later in this section.
Auditing File Management
The IS auditor should examine file management policies and procedures, including
- File system standards
The auditor should examine file system standards that specify file system architecture, directory naming standards, and technical settings that govern disk utilization and performance. - Access controls
The auditor should examine file system access control policy and procedures, the configuration settings that control which users and processes are able to access directories and files, and log files that record access control events such as permission changes and attempted file accesses, including any procedures followed when such events occur. - Capacity management
The settings and controls used to manage the capacity of file systems should be examined. This should include logs that show file system utilization, procedures for adding capacity, and records of capacity-related events. - Version control
In file systems and data repositories that contain documents under version control, the auditor should examine version control configuration settings, file update procedures, and file recovery procedures and records.
Auditing Data Entry
The IS auditor should examine data entry standards and operations, including
- Data entry procedures
This may include document control, input procedures, and error recovery procedures. - Input verification
This may include automatic and manual controls used to ensure that data has been entered properly into forms. - Batch verification
This may include automatic and manual controls used to calculate and verify batches of records that are input. - Correction procedures
This may include controls and procedures used to correct individual forms and batches when errors occur.
Auditing Lights-Out Operations
A lights-out operation is any production IT environment, such as computers in a data center, that runs without on-site operator intervention. The term “lights out” means that the computers can be in a room with the lights out since no personnel are present to attend to them.
Audit activities of a lights-out operation will fall primarily into the other categories of audits discussed in this chapter, plus a few specific activities, including
- Remote administration procedures
- Remote monitoring procedures
Auditing Problem Management Operations
The auditor should examine the organization’s problem management operations, including
- Problem management policy and processes
The auditor should examine policy and procedure documents that describe how problem management is supposed to be performed. - Problem management records
A sampling of problems and incidents should be examined to determine whether problems are being properly managed. - Problem management timelines
The time spent on each problem should be examined to see whether resolution falls within the SLA. - Problem management reports
The auditor should examine management reports to ensure that management is aware of all problems. - Problem resolution
The auditor should examine a sample of problems to see which ones required changes in other processes. The other process documents should be examined to determine if they were changed. The auditor also should examine records to see if fixes were verified by another party. - Problem recurrence
The auditor should examine problem records to make sure that the same problems are not coming up over and over again.
Auditing Monitoring Operations
The IS auditor needs to audit system monitoring operations to ensure that it is effective, including
- Monitoring plan
The auditor should review any monitoring plan documents that describe the organization’s monitoring program, tools, and processes. - Response plans
The auditor should review response plans, as well as records of responses. - Problem log
Monitoring problem logs should be reviewed to see what kinds of problems are being recorded. The auditor should determine whether all devices and systems are represented in problem logs. - Preventive maintenance
The auditor should examine monitoring results, monitoring plan, and preventive maintenance records, and determine whether the level of preventive maintenance is adequate and effective. - Management review and action
Any monitoring reports, meeting minutes, and decision logs should be examined to see whether management is reviewing monitoring reports and whether management actions are being carried out.
Auditing Procurement
The auditor should examine hardware, software, and services procurement processes, procedures, and records to determine whether any of the following activities are being performed:
- Requirements definition
All stakeholders (both technical and business, as appropriate) need to develop functional, technical, and security requirements. Each requirement needs to be approved and used to apply scrutiny to candidate products and services. Each candidate supplier’s responses need to be scored on their merits regarding their ability to meet requirements. This entire process needs to be transparent and documented. Auditors will need to examine procurement policies, procedures, and records from selected procurement projects. - Feasibility studies
Many requests for service will require an objective feasibility study that will be designed to identify the economic and business benefits that may be derived from the requested service. Auditors need to examine selected feasibility study documents as well as policy and procedure documents for performing feasibility projects.
Auditing Business Continuity Planning
Audits of an organization’s business continuity plan are especially difficult, because it is impossible to prove whether the plans will work unless a real disaster is experienced.
The IT auditor has quite a task when it comes to auditing an organization’s business continuity. The lion’s share of the audit results hinges on the quality of documentation and walkthroughs with key personnel.
As is typical with most audit activities, an audit of an organization’s BC program is a top-down analysis of key business objectives and a review of documentation and interviews to determine whether the BC strategy and program details support those key business objectives. This approach is depicted in Figure 5-37.
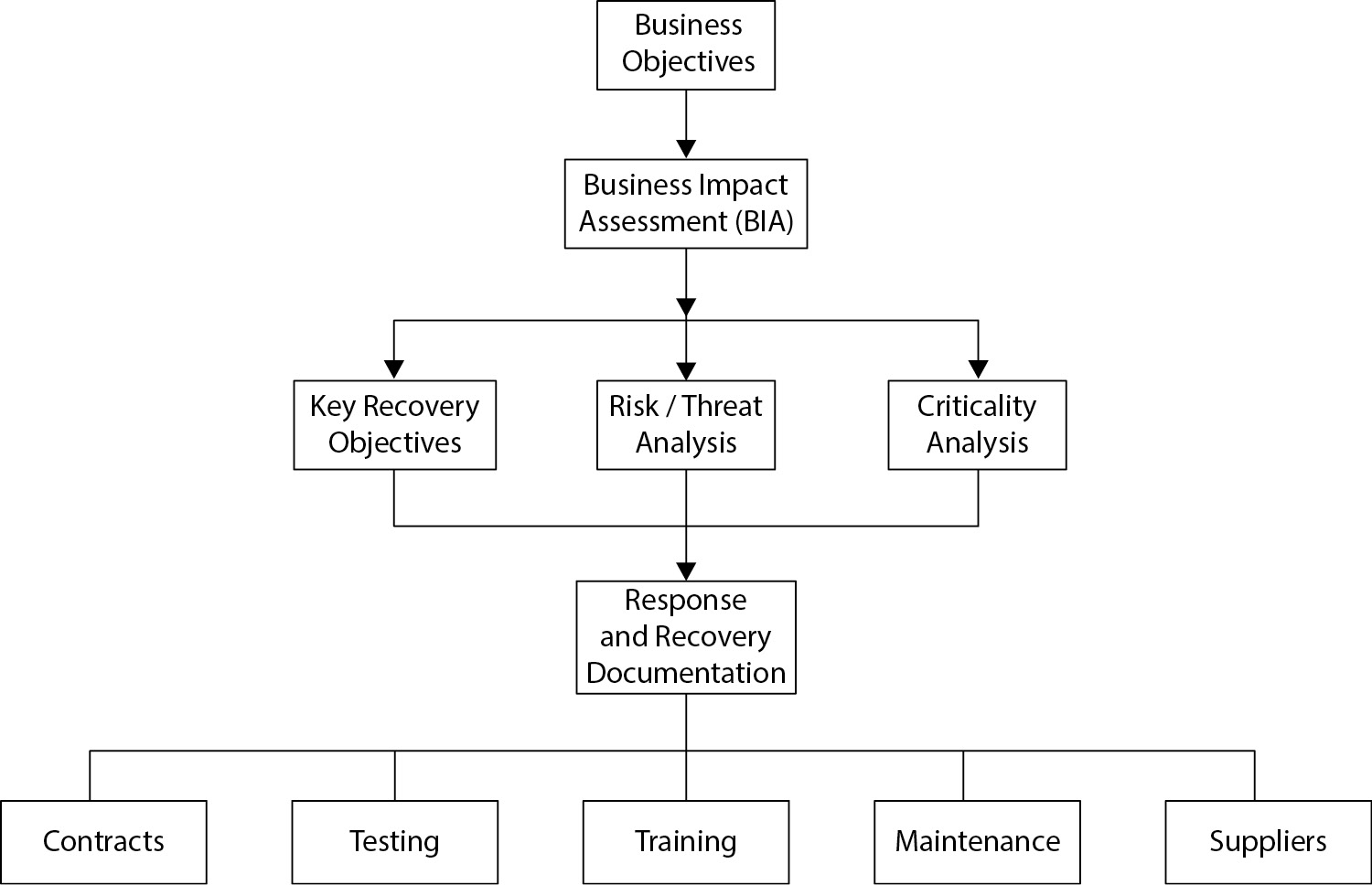
Figure 5-37 Top-down approach to an audit of business continuity
The objectives of an audit of BCP should include the following activities:
- Obtain documentation that describes current business strategies and objectives. Obtain high-level documentation (for example, strategy, charter, objectives) for the BC program, and determine whether the BC program supports business strategies and objectives.
- Obtain the most recent BIA and accompanying threat analysis, risk analysis, and criticality analysis. Determine whether these documents are current and complete, and that they support the BC strategy. Also determine whether the scope of these documents covers those activities considered strategic according to high-level business objectives. Finally, determine whether the methods in these documents represent good practices for these activities.
- Determine whether key personnel are ready to respond during a disaster by reviewing test plans and training plans and results. Find out where emergency procedures are stored and whether key personnel have access to them.
- Verify whether there is a process for the regular review and update of BC documentation. Evaluate the process’s effectiveness by reviewing records to see how frequently documents are being reviewed.
These activities are described in more detail in the following sections.
Auditing Business Continuity Documentation
The bulk of an organization’s business continuity plan lies in its documentation, so it should be of little surprise that the bulk of the audit effort will lie in the examination of this documentation. The following steps will help the auditor to determine the effectiveness of the organization’s BC plans:
- Obtain a copy of business continuity documentation, including response procedures, contact lists, and communication plans.
- Examine samples of distributed copies of BC documentation, and determine whether they are up-to-date. These samples can be obtained during interviews of key response personnel, which are covered in this procedure.
- Determine whether all documents are clear and easy to understand, not just for primary responders, but for alternate personnel who may have specific relevant skills but less familiarity with the organization’s critical applications.
- Examine documentation related to the declaration of a disaster and the initiation of disaster response. Determine whether the methods for declaration are likely to be effective in a disaster scenario.
- Obtain emergency contact information, and contact some of the personnel to see whether the contact information is accurate and up-to-date. Also determine whether all response personnel are still employed in the organization and are in the same or similar roles in support of disaster response efforts.
- Contact some or all of the response personnel who are listed in emergency contact lists. Interview them and see how well they understand their disaster response responsibilities and whether they are familiar with disaster response procedures. Ask each interviewee if they have a copy of these procedures. See if their copies are current.
- Determine whether a process exists for the formal review and update of business continuity documentation. Examine records to see how frequently, and how recently, documents have been reviewed and updated.
- Determine whether response personnel receive any formal or informal training on response and recovery procedures. Determine whether personnel are required to receive training and whether any records are kept that show which personnel received training and at what time.
Reviewing Prior Test Results and Action Plans
Effectiveness of business continuity plans relies, to a great degree, on the results and outcomes of tests. An IS auditor needs to examine these tests carefully to determine their effectiveness and to what degree they are used to improve procedures and to train personnel. The following procedure will help the IS auditor determine the effectiveness of business continuity testing:
- Determine whether there is a strategy for testing business continuity procedures. Obtain records for past tests and a plan for future tests. Determine whether prior tests and planned tests are adequate for establishing the effectiveness of response and recovery procedures.
- Examine records for tests that have been performed over the past year or two. Determine the types of tests that were performed. Obtain a list of participants for each test. Compare the participants to lists of key recovery personnel. Examine test work papers to determine the level of participation by key recovery personnel.
- Determine whether there is a formal process for recording test results and for using those results to make improvements in plans and procedures. Examine work papers and records to determine the types of changes that were recommended in prior tests. Examine BC documents to see whether these changes were made as expected.
- Considering the types of tests that were performed, determine the adequacy of testing as an indicator of the effectiveness of the BC program. Did the organization perform only document reviews and walkthroughs, for example, or did the organization also perform parallel or cutover tests?
- If tests have been performed for two years or more, determine whether there’s a trend showing continuous improvement in response and recovery procedures.
- If the organization performs parallel tests, determine whether tests are designed in a way that effectively determines the actual readiness of standby systems. Also determine whether parallel tests measure the capacity of standby systems or merely their ability to process correctly but at a lower level of performance.
Interviewing Key Personnel
The knowledge and experience of key personnel are vital to the success of any DR operation. Interviews will help the IT auditor determine whether key personnel are prepared and trained to respond during a disaster. The following procedure will guide the IT auditor in interviews:
- Obtain the name, title, tenure, and full contact information for each person interviewed.
- Ask the interviewee to summarize his or her professional experience and training and current responsibilities in the organization.
- Ask the interviewee whether he or she is familiar with the organization’s business continuity and disaster recovery programs.
- Determine whether the interviewee is among the key response personnel expected to respond during a disaster.
- Ask the interviewee if he or she has been issued a copy of any response or recovery procedures. If so, ask to see those procedures; determine whether they are current versions. Ask if the interviewee has additional sets of procedures in any other locations (residence, for example).
- Ask the interviewee if he or she has received any training. Request evidence of this training (certificate, calendar entry, and so on).
- Ask the interviewee if he or she has participated in any tests or evaluations of recovery and response procedures. Ask the interviewee whether the tests were effective, whether management takes the tests seriously, and whether any deficiencies in tests resulted in any improvements to test procedures or other documents.
Reviewing Service Provider Contracts
No organization is an island. Every organization has critical suppliers without which it could not carry out its critical functions. The ability to recover from a disaster also frequently requires the support of one or more service providers or suppliers. The IT auditor should examine contracts for all critical suppliers and consider the following guidelines:
- Does the contract support the organization’s requirements for delivery of services and supplies, even in the event of a local or regional disaster?
- Does the service provider have its own disaster recovery capabilities that will ensure its ability to deliver critical services during a disaster?
- Is recourse available should the supplier be unable to provide goods or services during a disaster?
Reviewing Insurance Coverage
The IT auditor should examine the organization’s insurance policies related to the loss of property and assets supporting critical business processes. Insurance coverage should cover the actual cost of recovery or a lesser amount if the organization’s executive management has accepted a lower amount. The IT auditor should obtain documentation that includes cost estimates for various DR scenarios, including equipment replacement, business interruption, and the cost of performing business functions and operating IT systems in alternate sites. These cost estimates should be compared with the value of insurance policies.
Visiting Media Storage and Alternate Processing Sites
The IT auditor should identify and visit remote sites used for storage of backup media and alternate processing. This will permit the auditor to confirm their existence, verify features and functions of these sites to see if they correspond to details in continuity and recovery plans, and to discover any risks.
Auditing Disaster Recovery Planning
The objectives of an audit of disaster recovery planning should include the following activities:
- Determine the effectiveness of planning and recovery documentation by examining previous test results.
- Evaluate the methods used to store critical information off-site (which may consist of off-site storage, alternate data centers, or e-vaulting).
- Examine environmental and physical security controls in any off-site or alternate sites and determine their effectiveness.
- Note whether off-site or alternate site locations are within the same geographic region—which could mean that both the primary and alternate sites may be involved in common disaster scenarios.
Auditing Disaster Recovery Plans
The following steps will help the auditor determine the effectiveness of the organization’s DR plans:
- Obtain a copy of DR documentation, including response procedures, contact lists, and communication plans.
- Examine samples of distributed copies of DR documentation and determine whether they are up-to-date. These samples can be obtained during interviews of key response personnel, which are covered in this procedure.
- Determine whether all documents are clear and easy to understand, not just for primary responders, but for alternate personnel who may have specific relevant skills but less familiarity with the organization’s critical applications.
- Obtain contact information for off-site storage providers, hot-site facilities, and critical suppliers. Determine whether these organizations are still providing services to the organization. Call some of the contacts to determine the accuracy of the documented contact information.
- For organizations using third-party recovery sites such as cloud infrastructure providers, obtain contracts that define organization and cloud provider obligations, service levels, and security controls.
- Obtain logical and physical architecture diagrams for key IT applications that support critical business processes. Determine whether BC documentation includes recovery procedures for all components that support those IT applications. See whether documentation includes recovery for end users and administrators for the applications.
- If the organization uses a hot site, examine one or more systems to determine whether they have the proper versions of software, patches, and configurations. Examine procedures and records related to the tasks in support of keeping standby systems current. Determine whether these procedures are effective.
- If the organization has a warm site, examine the procedures used to bring standby systems into operational readiness. Examine warm-site systems to see whether they are in a state where readiness procedures will likely be successful.
- If the organization has a cold site, examine all documentation related to the acquisition of replacement systems and other components. Determine whether the procedures and documentation are likely to result in systems capable of hosting critical IT applications and within the period required to meet key recovery objectives.
- If the organization uses a cloud service provider’s service as a recovery site, examine the procedures used to prepare and bring cloud-based systems to operational readiness. Examine procedures and configurations to see whether they are likely to support the organization successfully during a disaster.
- Determine whether any documentation exists regarding the relocation of key personnel to the hot/warm/cold processing site. See whether the documentation specifies which personnel are to be relocated and what accommodations and supporting logistics are provided. Determine the effectiveness of these relocation plans.
- Determine whether backup and off-site (or replication or e-vaulting) storage procedures are being followed. Examine systems to ensure that critical IT applications are being backed up and that proper media are being stored off-site (or that the proper data is being e-vaulted). Determine whether data recovery tests are ever performed and, if so, whether results of those tests are documented and problems are properly dealt with.
- Evaluate procedures for transitioning processing from the alternate processing facility back to the primary processing facility. Determine whether these procedures are complete and effective.
- Determine whether a process exists for the formal review and update of business continuity documentation to ensure continued alignment with DR planning. Examine records to see how frequently, and how recently, documents have been reviewed and updated. Determine whether this is sufficient and effective by interviewing key personnel to understand whether significant changes to applications, systems, networks, or processes are reflected in recovery and response documentation.
- Determine whether response personnel receive any formal or informal training on response and recovery procedures. Determine whether personnel are required to receive training, and whether any records are kept that show which personnel received training and at what time.
- Examine the organization’s change control process. Determine whether the process includes any steps or procedures that require personnel to determine whether any change has an impact on DR documentation or procedures.
Reviewing Prior DR Test Results and Action Plans
The effectiveness of DR plans relies on the results and outcomes of tests. The IS auditor needs to examine these plans and activities to determine their effectiveness. The following will help the IS auditor audit DR testing:
- Determine whether there is a strategy for testing DR plans. Obtain records for past tests and a plan for future tests.
- Examine records for tests that have been performed over the past year or two. Determine the types of tests that were performed. Obtain a list of participants for each test. Compare the participants to lists of key recovery personnel. Examine test work papers to determine the level of participation by key recovery personnel.
- Determine whether there is a formal process for recording test results and for using those results to make improvements in plans and procedures. Examine work papers and records to determine the types of changes that were recommended in prior tests. Examine DR documents to see whether these changes were made as expected.
- Considering the types of tests that were performed, determine the adequacy of testing as an indicator of the effectiveness of the DR program. Did the organization perform only document reviews and walkthroughs, for example, or did the organization also perform parallel or cutover tests?
- If tests have been performed for two years or more, determine whether there’s a trend showing continuous improvement in response and recovery procedures.
- If the organization performs parallel tests, determine whether tests are designed in a way that effectively determines the actual readiness of standby systems. Also determine whether parallel tests measure the capacity of standby systems or merely their ability to process correctly but at a lower level of performance.
- Determine whether any tests included the retrieval of backup data from off-site storage or e-vaulting facilities.
Evaluating Off-Site Storage
Storage of critical data and other supporting information is a key component in any organization’s DR plan. Because some types of disasters can completely destroy a business location, including its vital records, it is imperative that all critical information is backed up and copies moved to an off-site storage facility. The following procedure will help the IS auditor determine the effectiveness of off-site storage:
- Obtain the location of the off-site storage or e-vaulting facility. Determine whether the facility is located in the same geographic region as the organization’s primary processing facility.
- If possible, visit the off-site storage facility. Examine its physical security controls as well as its safeguards to prevent damage to stored information in a disaster. Consider the entire spectrum of physical and logical access controls. Examine procedures and records related to the storage and return of backup media and other information that the organization may store there. If it is not possible to visit the off-site storage facility, obtain copies of audits or other attestations of controls effectiveness.
- Take an inventory of backup media and other information stored at the facility. Compare this inventory with a list of critical business processes and supporting IT systems to determine whether all relevant information is, in fact, stored at the off-site storage facility.
- Determine how often the organization performs its own inventory of the off-site facility and whether steps to correct deficiencies are documented and remedied.
- Examine contracts, terms, and conditions for off-site storage providers or e-vaulting facilities, if applicable. Determine whether data can be recovered to the original processing center and to alternate processing centers within a period that will ensure that DR can be completed within RTOs.
- Determine whether the appropriate personnel have current access codes for off-site storage or e-vaulting facilities and whether they have the ability to recover data from those facilities.
- Determine what information, in addition to backup data, exists at the off-site storage facility. Information stored off-site should include architecture diagrams, design documentation, operations procedures, and configuration information for all logical and physical layers of technology and facilities supporting critical IT applications, operations documentation, and application source code.
- Obtain information related to the manner in which backup media and copies of records are transported to and from the off-site storage or e-vaulting facility. Determine the adequacy of controls protecting transported information.
- Obtain records supporting the transport of backup media and records to and from the off-site storage facility. Examine samples of records and determine whether they match other records such as backup logs.
Evaluating Alternate Processing Facilities
The IS auditor needs to examine alternate processing facilities to determine whether they are sufficient to support the organization’s BC and DR plans. The following procedure will help the IS auditor to determine whether an alternate processing facility will be effective:
- Obtain addresses and other location information for alternate processing facilities. These will include hot sites, warm sites, cold sites, cloud-based services, and alternate processing centers owned or operated by the organization. Note that exact locations of cloud services are often unavailable for security reasons.
- Determine whether alternate facilities are located within the same geographic region as the primary processing facility and the probability that the alternate facility will be adversely affected by a disaster that strikes the primary facility.
- Perform a threat analysis on the alternate processing site. Determine which threats and hazards pose a significant risk to the organization and its ability to carry out operations effectively during a disaster.
- Determine the types of natural and man-made events likely to take place at the alternate processing facility. Determine whether there are adequate controls to mitigate the effect of these events.
- Examine all environmental controls and determine their adequacy. This should include environmental controls (HVAC), power supply, uninterruptible power supply (UPS), power distribution units (PDUs), and electric generators. Also examine fire detection and suppression systems, including smoke detectors, pull stations, fire extinguishers, sprinklers, and inert gas suppression systems.
- If the alternate processing facility is a separate organization, obtain the legal contract and all exhibits. Examine these documents and determine whether the contract and exhibits support the organization’s recovery and testing requirements.
NOTE
Cloud-based service providers often do not permit on-site visits. Instead, they may have one or more external audit reports available through standard audits such as SSAE18, ISAE3402, SOC1, SOC2, ISO, or PCI. Auditors will need to determine whether any such external audit reports may be relied upon, and whether there are any controls that are not covered by such external audits.
Chapter Review
All activities in the IT department should be managed, controlled, and monitored. Activities performed by operations personnel should be a part of a procedure or process that is approved by management. Processes, procedures, and projects should have sufficient recordkeeping to facilitate measurements.
IT operations should be structured in a service management model that is aligned with the IT Infrastructure Library (ITIL) or the COBIT framework of processes. These frameworks ensure that comprehensive coverage of activities is likely to be taking place in most IT organizations.
IS auditors need to have a thorough understanding of information systems hardware and software and how they work to support business objectives. This includes knowing how computer hardware functions; how operating systems are installed, configured, and operated; how end users’ workstations are provisioned, managed, and used; and how software applications operate. Because newer technologies are not always implemented properly at first, IS auditors need to understand technologies such as virtualization, virtual desktops, software-defined networking, and mobile devices to ensure that the organization is not incurring unnecessary risk through their use.
Network management tools and systems help management understand a network’s utilization, capacity, and problems. Network management should be a part of a larger infrastructure monitoring strategy.
Natural and human-made disasters can damage business facilities, assets, and information systems, thus threatening the viability of the organization by halting its critical processes. Even without direct effects, many secondary or indirect effects from a disaster such as crippled transportation systems, damaged communications systems, and damaged public utilities can seriously harm an organization. The development of business continuity plans helps an organization be better prepared to act when a disaster strikes. A vital part of this preparation is the development of alternative means for continuing the most critical activities, usually in alternate locations that are not damaged by a disaster.
There is an accepted methodology to BC and DR planning, which begins with the development of a BCP policy, a statement of the goals and objectives of a planning effort. This is followed by a BIA, a study of the organization’s business processes to determine which are the most critical to the organization’s ongoing viability. For each critical process, a statement of impact is developed, which is a brief description of the effect on the organization if the process is incapacitated for any significant period. The statement of impact can be qualitative or quantitative.
A criticality analysis is performed next, where all in-scope business processes are ranked in order of criticality. Ranking can be strictly quantitative, qualitative, or even subjective. The maximum tolerable downtime (MTD) is established for each critical business process. This drives the development of recovery targets.
Next, recovery targets for each critical business process are developed. The key targets are RTO and RPO. These targets specify time to system restoration and maximum data loss, respectively. When these targets have been established, the project team can develop plans that include changes to technical architecture as well as business processes that will help achieve these established recovery objectives.
Continuity plans are then developed. These consist of procedures for personnel safety and disaster declaration, together with definitions of responsibilities, contact information for key personnel, and procedures for recovery, continuity of operations, and restoration of assets.
The effectiveness of business continuity plans can be determined only by testing. There are five types of tests: document review, walkthrough, simulation, parallel test, and cutover test. These five tests represent progressively more complex (and risky) means for testing procedures and IT systems to determine whether they will be able to support critical business processes in a real disaster. The parallel test involves the use of backup IT systems in a way that enables them to process real business transactions while primary systems continue to perform the organization’s real work. The cutover test actually transitions business data processing to backup IT systems, where they will process actual business workload for a period.
Response personnel need to be carefully chosen from available staff to ensure that sufficient numbers of personnel will be available in a real disaster. Some personnel may be unable to respond for a variety of reasons that are related to the disaster itself. As a result, some of the personnel who respond in an actual disaster may not be as familiar with the systems and procedures required to recover and maintain them. This makes training and accurate procedures critical for effective disaster recovery.
Recovery and continuity plans need to be periodically updated to reflect changes in information systems, and distributed to or made available to response and recovery personnel.
Auditing an organization’s BC capabilities involves the examination of BCP policies, plans, and procedures, as well as contracts and technical architectures. The IT auditor also needs to interview response personnel to gauge their readiness and to visit off-site media storage and alternate processing sites to identify risks present there.
During a DRP project, once acceptable architectures and process changes have been determined, the organization sets out to make investments in these areas to bring its systems and processes closer to the recovery objectives. Procedures for recovering systems and processes are also developed at this time, as well as procedures for other aspects of disaster response, such as emergency communications plans and evacuation plans.
Some of the investment in IT system resilience may involve the establishment of an alternate processing site, where IT systems can be resumed in support of critical business processes. There are several types of alternate sites, including a hot site, where IT systems are in a continual state of near-readiness and can assume production workload within an hour or two; a warm site, where IT systems are present but require several hours to a day of preparation; a cold site, where no systems are present but must be acquired, which may require several days of preparation before those replacement systems are ready to support business processes; and a cloud-based site, in which virtual machines are provided on an on-demand basis, and where the organization will establish a hot, warm, or cold capability therein. Virtual infrastructure in a public cloud can serve as a hot or warm site.
Some of the technologies that may be introduced in IT systems to improve recovery targets include RAID, a technology that improves the reliability of disk storage systems; replication, a technique for copying data in near–real time to an alternate (and usually distant) storage system; e-vaulting, where data is copied to a cloud-based e-vaulting service; and clustering, a technology whereby several servers (including some that can be located in another region) act as one logical server, enabling processing to continue even if one or more servers are incapacitated or unreachable.
Quick Review
- All IT activities should be a part of a documented process, procedure, or project.
- Key systems, applications, and infrastructure should be monitored to ensure that they continue to operate properly in their support of key business processes.
- Software program libraries should be controlled with access and authorization controls, check-out and check-in, version control, and code analysis.
- Media sanitization procedures ensure that data leakage will not result from discarded data storage media.
- Mobile devices such as tablet computers and smartphones are the new endpoints. Lacking mature enterprise management controls and anti-malware tools, and being small enough to easily lose, mobile devices are a popular attack vector. The IS auditor needs to understand how the organization addresses these matters.
- It is as important to understand the internal architecture of computers as it is to understand how computers can be combined to form clusters and multitier application environments.
- Automated monitoring of computing and network infrastructure includes monitoring of internal components such as CPU, power supply, memory, and storage. Monitoring also includes resource utilization such as CPU, memory, disk storage, and network. The external environment, including temperature, humidity, water, and vibration, should also be monitored.
- Software license management ensures that the organization will remain in compliance with its software license agreements and avoid costly and embarrassing legal trouble. Automated tools can help monitor the installation and use of licensed software.
- Although the seven-layer OSI data model has never been implemented in its pure form, it is still important to understand its concepts. Terms from the model are used by IT specialists; for instance, layer 4 switches are a type of network device that routes packets based on their OSI layer 4 characteristics.
- IS auditors need to understand the TCP/IP model and TCP/IP’s common protocols well enough to be able to identify risks and control weaknesses.
- A network’s logical architecture (star, ring, or bus) often does not match its physical architecture (star, ring, or bus).
- A key place to examine a network is its boundary. Edge devices such as firewalls, routers, wireless access points, and gateways contain configurations that control inbound and outbound traffic. Mistakes here can be costly.
- Most of the older and less secure TCP/IP protocols such as Telnet, FTP, and RCP have been superseded by newer protocols such as SSH, SFTP, and FTPS.
- BCP ensures business recovery following a disaster. Business continuity focuses on maintaining service availability with the least disruption to standard operating parameters during an event, while disaster recovery focuses on post-event recovery and restoration of services.
- BCP encompasses a life cycle beginning with the initial BCP policy, followed by business impact and criticality analysis to evaluate risk and impact factors. Recovery targets facilitate the development of strategies for continuity and recovery, which then must be tested and conveyed to operation personnel through training and exercise. Post-implementation maintenance includes periodic reviews and updates as part of the enterprise continuous-improvement process.
- The business impact analysis (BIA) measures the impact on enterprise operation posed by various identified areas of risk. The output of the BIA is used in the criticality analysis (CA), which measures the impact of each risk against its likelihood and the cost of mitigation. Maximum tolerable downtime (MTD) metrics are established for each critical process.
- The output of the BIA, CA, and MTD activities are used when establishing recovery time objectives (RTOs) and recovery point objectives (RPOs), which can then be measured against relative cost scenarios for each identified risk and mitigation option.
- RTOs and RPOs are fed into the DR process so that staff can develop resilient and recoverable IT architectures supporting critical business processes.
- BC plans must be tested to validate effectiveness through document review, walkthrough, simulation, parallel testing, or cutover testing practices. Regular testing must take place to ensure new objectives and procedures meet the requirements of a living enterprise environment. Participation in these tests provides familiarity and training for engaged operational staff members, raising understanding and awareness of requirements and responsibilities.
- Organizations are increasingly turning to the cloud for their alternate processing sites. IS auditors need to understand how cloud-based infrastructure is procured, protected, and managed.
- Once recovery objectives have been identified, strategies can be developed to meet each objective. Many solutions may include redundant (hot, warm, or cold) alternate sites, redundant service operation or storage in high-availability or distributed-cluster environments, alternative network access strategies, and backup/recovery strategies structured to meet identified recovery time and recovery point requirements.
Questions
- [1]. A web application is displaying information incorrectly and many users have contacted the IT service desk. This matter should be considered a(n)
- A. Incident
- B. Problem
- C. Bug
- D. Outage
- [2]. An IT organization is experiencing many cases of unexpected downtime that are caused by unauthorized changes to application code and operating system configuration. Which process should the IT organization implement to reduce downtime?
- A. Configuration management
- B. Incident management
- C. Change management
- D. Problem management
- [3]. An IT organization manages hundreds of servers, databases, and applications, and is having difficulty tracking changes to the configuration of these systems. What process should be implemented to remedy this?
- A. Configuration management
- B. Change management
- C. Problem management
- D. Incident management
- [4]. A computer’s CPU, memory, and peripherals are connected to each other through a
- A. Kernel
- B. FireWire
- C. Pipeline
- D. Bus
- [5]. A database administrator has been asked to configure a database management system so that it records all changes made by users. What should the database administrator implement?
- A. Audit logging
- B. Triggers
- C. Stored procedures
- D. Journaling
- [6]. The layers of the TCP/IP reference model are
- A. Link, Internet, transport, application
- B. Physical, link, Internet, transport, application
- C. Link, transport, Internet, application
- D. Physical, data link, network, transport, session, presentation, application
- [7]. The purpose of the Internet layer in the TCP/IP model is
- A. Encapsulation
- B. Packet delivery on a local network
- C. Packet delivery on a local or remote network
- D. Order of delivery and flow control
- [8]. The purpose of the DHCP protocol is
- A. Control flow on a congested network.
- B. Query a station to discover its IP address.
- C. Assign an IP address to a station.
- D. Assign an Ethernet MAC address to a station.
- [9]. An IS auditor is examining a wireless (Wi-Fi) network and has determined that the network uses WEP encryption. What action should the auditor take?
- A. Recommend that encryption be changed to WPA.
- B. Recommend that encryption be changed to EAP.
- C. Request documentation for the key management process.
- D. Request documentation for the authentication process.
- [10]. 126.0.0.1 is an example of a
- A. MAC address
- B. Loopback address
- C. Class A address
- D. Subnet mask
- [11]. What is the most important consideration when selecting a hot site?
- A. Time zone
- B. Geographic location in relation to the primary site
- C. Proximity to major transportation
- D. Natural hazards
- [12]. An organization has established a recovery point objective of 14 days for its most critical business applications. Which recovery strategy would be the best choice?
- A. Mobile site
- B. Warm site
- C. Hot site
- D. Cold site
- [13]. What technology should an organization use for its application servers to provide continuous service to users?
- A. Dual power supplies
- B. Server clustering
- C. Dual network feeds
- D. Transaction monitoring
- [14]. An organization currently stores its backup media in a cabinet next to the computers being backed up. A consultant told the organization to store backup media at an off-site storage facility. What risk did the consultant most likely have in mind when he made this recommendation?
- A. A disaster that damages computer systems can also damage backup media.
- B. Backup media rotation may result in loss of data backed up several weeks in the past.
- C. Corruption of online data will require rapid data recovery from off-site storage.
- D. Physical controls at the data processing site are insufficient.
- [15]. Which of the following statements about virtual server hardening is true?
- A. The configuration of the host operating system will automatically flow to each guest operating system.
- B. Each guest virtual machine needs to be hardened separately.
- C. Guest operating systems do not need to be hardened because they are protected by the hypervisor.
- D. Virtual servers do not need to be hardened because they do not run directly on computer hardware.
Answers
- [1]. B. A problem is defined as a condition that is the result of multiple incidents that exhibit common symptoms. In this example, many users are experiencing the effects of the application error.
- [2]. C. Change management is the process of managing change through a life cycle process that consists of request, review, approve, implement, and verify.
- [3]. A. Configuration management is the process (often supplemented with automated tools) of tracking configuration changes to systems and system components such as databases and applications.
- [4]. D. A bus connects all of the computer’s internal components together, including its CPU, main memory, secondary memory, and peripheral devices.
- [5]. A. The database administrator should implement audit logging. This will cause the database to record every change that is made to it.
- [6]. A. The layers of the TCP/IP model are (from lowest to highest) link, Internet, transport, and application.
- [7]. C. The purpose of the Internet layer in the TCP/IP model is the delivery of packets from one station to another, on the same network or on a different network.
- [8]. C. The DHCP protocol is used to assign IP addresses to computers on a network.
- [9]. A. The WEP protocol has been seriously compromised and should be replaced with WPA or WPA2 encryption.
- [10]. C. Class A addresses are in the range 0.0.0.0 to 127.255.255.255. The address 126.0.0.1 falls into this range.
- [11]. B. An important selection criterion for a hot site is the geographic location in relation to the primary site. If they are too close together, then a single disaster event may involve both locations.
- [12]. D. An organization that has a 14-day recovery time objective (RTO) can use a cold site for its recovery strategy. Fourteen days is enough time for most organizations to acquire hardware and recover applications.
- [13]. B. An organization that wants its application servers to be continuously available to its users needs to employ server clustering. This enables at least one server to be always available to service user requests.
- [14]. A. The primary reason for employing off-site backup media storage is to mitigate the effects of a disaster that could otherwise destroy computer systems and their backup media.
- [15]. B. In a virtualization environment, each guest operating system needs to be hardened; they are no different from operating systems running directly on server (or workstation) hardware.